![]()

Tutorial 2: Model-free Reinforcement Learning#
Week 3, Day 4: Basic Reinforcement Learning
By Neuromatch Academy
Content creators: Pablo Samuel Castro
Content reviewers: Shaonan Wang, Xiaomei Mi, Julia Costacurta, Dora Zhiyu Yang, Adrita Das, Jiaxin Cindy Tu
Content editors: Shaonan Wang, Jiaxin Cindy Tu
Production editors: Spiros Chavlis, Konstantine Tsafatinos
Tutorial Objectives#
In the previous tutorial you mastered the full model-based RL toolkit (GridWorld, MDP, value iteration, policy iteration). Today you will tackle the algorithms that make RL powerful in practice, where the agent has no access to \(P\) or \(R\):
\(Q\)-learning — learn optimal \(Q\)-values by interacting with the environment, one transition at a time.
\(\epsilon\)-greedy exploration — balance exploiting what you know against exploring new possibilities.
Project students (lunar lander / human RL): These two sections cover exactly the \(Q\)-learning and exploration concepts you need for DQN.
Setup#
This is a GPU free notebook!
Install and import feedback gadget#
Show code cell source
# @title Install and import feedback gadget
!pip3 install vibecheck datatops --quiet
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_dl",
"user_key": "f379rz8y",
},
).render()
feedback_prefix = "W3D4_T2"
# Imports
import numpy as np
import matplotlib.pyplot as plt
from typing import Optional, Tuple
Figure settings#
Show code cell source
# @title Figure settings
import logging
logging.getLogger('matplotlib.font_manager').disabled = True
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/content-creation/main/nma.mplstyle")
Recap: What you built in Tutorial 1#
After running the cell you will have a gwb GridWorld and a mdpVi value-iteration solver ready to use.
Run this cell first#
Show code cell source
# @title Run this cell first
ASCII_TO_EMOJI = {
' ': '⬜', '*': '⬛', 'g': '⭐',
'<': '◀️', '>': '▶️', 'v': '🔽', '^': '🔼',
}
ACTIONS = ['<', '>', 'v', '^']
ACTION_EFFECTS = {'<': (0, -1), '>': (0, 1), 'v': (1, 0), '^': (-1, 0)}
def get_emoji(c, policy=None):
assert c in ASCII_TO_EMOJI
if policy is not None and c != 'g':
assert policy in ASCII_TO_EMOJI
if policy != ' ':
c = policy
return ASCII_TO_EMOJI[c]
class GridWorldBase(object):
def __init__(self, world_spec: Optional[np.ndarray] = None):
if world_spec is None:
self.world_spec = np.array(
[['*', '*', '*', '*', '*', '*'],
['*', ' ', ' ', ' ', ' ', '*'],
['*', ' ', ' ', ' ', ' ', '*'],
['*', ' ', ' ', ' ', ' ', '*'],
['*', ' ', ' ', ' ', 'g', '*'],
['*', '*', '*', '*', '*', '*']]
)
else:
assert len(world_spec.shape) == 2
self.world_spec = world_spec
assert len(np.where(self.world_spec == 'g')[0]) == 1
self.policy = np.full_like(self.world_spec, ' ')
self.goal_cell = [x[0] for x in np.where(self.world_spec == 'g')]
def get_neighbours(self, cell: Tuple[int, int]):
height, width = self.world_spec.shape
i, j = cell
neighbours = {}
for a in ACTIONS:
delta = ACTION_EFFECTS[a]
nbr = [i + delta[0], j + delta[1]]
if (nbr[0] < 0 or nbr[1] < 0 or nbr[0] >= height or nbr[1] >= width
or self.world_spec[nbr[0], nbr[1]] == '*'):
neighbours[a] = cell
else:
neighbours[a] = nbr
return neighbours
def plan(self):
for i in range(self.policy.shape[0]):
for j in range(self.policy.shape[1]):
if self.world_spec[i, j] == '*':
continue
self.policy[i, j] = ACTIONS[np.random.choice(len(ACTIONS))]
def draw(self, include_policy: bool = False):
for i in range(len(self.world_spec)):
row_range = range(len(self.world_spec[i]))
if include_policy:
row_chars = [get_emoji(self.world_spec[i, j], self.policy[i, j]) for j in row_range]
else:
row_chars = [get_emoji(self.world_spec[i, j], None) for j in row_range]
print(''.join(row_chars))
class MDPBase(object):
def __init__(self, grid_world: GridWorldBase):
self.grid_world = grid_world
self.num_states = np.sum(grid_world.world_spec != '*')
self.num_actions = len(ACTIONS)
self.P = np.zeros((self.num_states, self.num_actions, self.num_states))
self.R = np.zeros((self.num_states, self.num_actions))
self.pi = np.zeros(self.num_states, dtype=np.int32)
state_idx = 0
self.cell_to_state = np.ones(grid_world.world_spec.shape, dtype=np.int32) * -1
self.state_to_cell = {}
for i, row in enumerate(grid_world.world_spec):
for j, cell in enumerate(row):
if cell == '*':
continue
if cell == 'g':
self.goal_state = state_idx
self.cell_to_state[i, j] = state_idx
self.state_to_cell[state_idx] = (i, j)
state_idx += 1
for s in range(self.num_states):
neighbours = grid_world.get_neighbours(self.state_to_cell[s])
for a, action in enumerate(neighbours):
nbr = neighbours[action]
s2 = self.cell_to_state[nbr[0], nbr[1]]
self.P[s, a, s2] = 1.0
if s2 == self.goal_state:
self.R[s, a] = 1.0
def draw(self, include_policy: bool = False):
for s in range(self.num_states):
r, c = self.state_to_cell[s]
self.grid_world.policy[r, c] = ACTIONS[self.pi[s]]
self.grid_world.draw(include_policy)
def plan(self):
goal_queue = [self.goal_state]
goals_done = set()
while goal_queue:
goal = goal_queue.pop(0)
nbr_states, nbr_actions = np.where(self.P[:, :, goal] > 0.)
goals_done.add(goal)
for s, a in zip(nbr_states, nbr_actions):
if s == goal:
continue
if s not in goals_done:
self.pi[s] = a
goal_queue.append(s)
class MDPToGo(MDPBase):
def __init__(self, grid_world: GridWorldBase):
super().__init__(grid_world)
self.Q = np.zeros((self.num_states, self.num_actions))
def computeQ(self):
goal_queue = [(self.goal_state, 0)]
goals_done = set()
while goal_queue:
goal, steps_to_go = goal_queue.pop(0)
steps_to_go += 1
nbr_states, nbr_actions = np.where(self.P[:, :, goal] > 0.)
goals_done.add(goal)
for s, a in zip(nbr_states, nbr_actions):
if goal == self.goal_state and s == self.goal_state:
self.Q[s, a] = 0
elif s == goal:
self.Q[s, a] = np.inf
else:
self.Q[s, a] = steps_to_go
if s not in goals_done:
goal_queue.append((s, steps_to_go))
def plan(self):
self.pi = np.argmin(self.Q, axis=-1)
class MDPValueIteration(MDPToGo):
def __init__(self, grid_world: GridWorldBase, gamma: float = 0.99):
super().__init__(grid_world)
self.gamma = gamma
def computeQ(self, error_tolerance: float = 1e-5):
self.Q = np.zeros((self.num_states, self.num_actions))
num_iterations = 0
error = np.inf
while error > error_tolerance:
new_Q = np.zeros_like(self.Q)
max_next_Q = np.max(self.Q, axis=-1)
for a in range(self.num_actions):
new_Q[:, a] = self.R[:, a] + self.gamma * (self.P[:, a, :] @ max_next_Q)
error = np.max(abs(new_Q - self.Q))
self.Q = np.copy(new_Q)
num_iterations += 1
self.V = np.max(self.Q, axis=-1)
print(f'Value iteration converged in {num_iterations} iterations.')
def plan(self):
self.pi = np.argmax(self.Q, axis=-1)
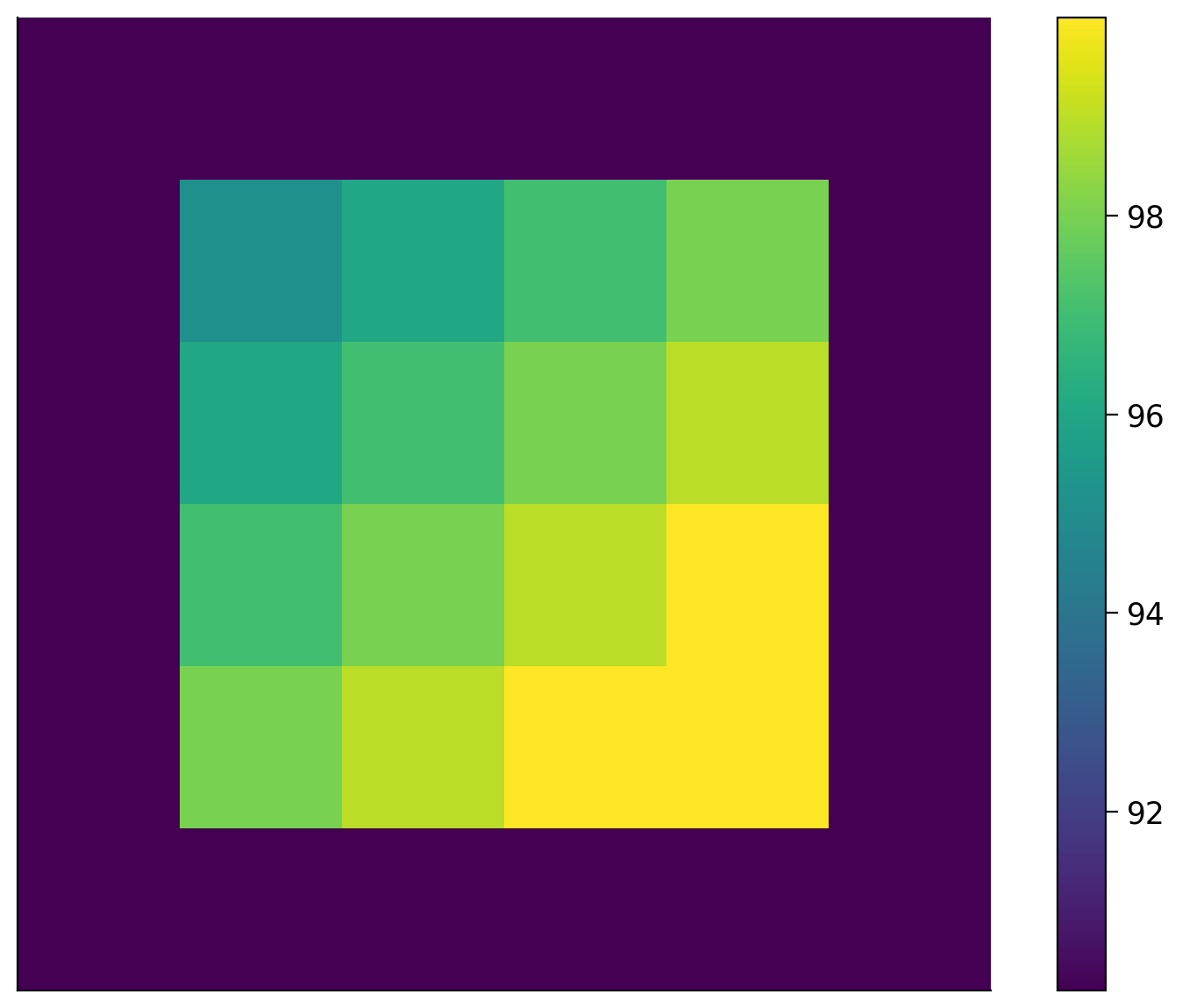
def _draw_v(self):
min_v = np.min(self.V); max_v = np.max(self.V)
wall_v = 2 * min_v - max_v
grid_values = np.ones_like(self.grid_world.world_spec, dtype=np.int32) * wall_v
for s in range(self.num_states):
cell = self.state_to_cell[s]
grid_values[cell[0], cell[1]] = self.V[s]
fig, ax = plt.subplots()
ax.grid(False); ax.get_xaxis().set_visible(False); ax.get_yaxis().set_visible(False)
grid = ax.matshow(grid_values); grid.set_clim(wall_v, max_v); fig.colorbar(grid)
def draw(self, draw_mode: str = 'grid'):
if draw_mode == 'values':
self._draw_v()
else:
super().draw(draw_mode == 'policy')
# ── Set up the shared GridWorld and run value iteration ──────────────────────
gwb = GridWorldBase()
mdpVi = MDPValueIteration(gwb)
mdpVi.computeQ()
mdpVi.plan()
print('GridWorld with optimal policy (value iteration):')
mdpVi.draw('policy')
print('Value function:')
mdpVi.draw('values')
Value iteration converged in 1147 iterations.
GridWorld with optimal policy (value iteration):
⬛⬛⬛⬛⬛⬛
⬛▶️▶️▶️🔽⬛
⬛▶️▶️▶️🔽⬛
⬛▶️▶️▶️🔽⬛
⬛▶️▶️▶️⭐⬛
⬛⬛⬛⬛⬛⬛
Value function:
Section 1: \(Q\)-learning#
So far every algorithm you have implemented required direct access to the transition matrix \(P\) and the reward function \(R\). In real RL problems these are almost never available — the agent must learn from experience alone.
\(Q\)-learning solves this by updating \(Q\)-values online using single transitions \((s, a, r, s')\):
The difference between the TD target and the current estimate is called the TD error. Over many steps, \(Q\) converges to the optimal values — no model needed.
Video: Q-learning#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Q_learning_Video")
Before you start: the Q-learning update rule in code#
Given a single experience \((s, a, r, s')\), the update is:
td_error = r + gamma * max(Q[s', :]) - Q[s, a]
Q[s, a] += alpha * td_error
Initialization matters! If you initialise Q to all zeros, a greedy agent will never explore — every action looks equally good and the agent gets stuck. Initialise Q optimistically (to a value higher than any real return) so the agent is always “disappointed” and forced to try new actions.
The maximum possible discounted return when rewards are in \([0, 1]\) is \(\frac{1}{1-\gamma}\).
Coding Exercise 1: Implement Q-learning#
Create a QLearner class that learns \(Q\)-values through interaction.
class QLearner(MDPValueIteration):
def __init__(self, grid_world: GridWorldBase, gamma: float = 0.99):
"""Constructs an MDP from a GridWorldBase object.
States should be numbered from left-to-right and from top-to-bottom.
Args:
grid_world: GridWorld specification.
gamma: Discount factor.
"""
super().__init__(grid_world, gamma)
self.Q = np.zeros((self.num_states, self.num_actions))
self.current_state = np.random.choice(self.num_states)
def step(self, action: int) -> Tuple[int, float]:
"""Take one step: returns (next_state, reward)."""
new_state = np.random.choice(self.num_states,
p=self.P[self.current_state, action, :])
return (new_state, self.R[self.current_state, action])
def pickAction(self) -> int:
"""Greedy action from current state."""
return np.argmax(self.Q[self.current_state, :])
def maybeReset(self):
"""Reset to a random state when the goal is reached."""
if self.current_state == self.goal_state:
self.current_state = np.random.choice(self.num_states)
def learnQ(self, alpha: float = 0.1, max_steps: int = 10_000):
"""Learn Q by interacting with the environment.
Args:
alpha: Learning rate.
max_steps: Total number of environment steps.
"""
# Initialise Q optimistically so the agent is forced to explore.
# The maximum possible discounted return is 1 / (1 - gamma).
self.Q = np.ones((self.num_states, self.num_actions)) / (1 - self.gamma)
num_steps = 0
##############################################################
# TODO: implement the Q-learning loop.
# Hint: use pickAction(), step(), and maybeReset().
raise NotImplementedError("Implement learnQ!")
##############################################################
while num_steps < max_steps:
a = ... # pick a greedy action
new_state, r = ... # take the step
td = ... # TD error: r + γ·max(Q[s',:]) - Q[s,a]
self.Q[self.current_state, a] += ... # α · TD error
self.current_state = ...
self.maybeReset()
num_steps += 1
self.V = np.max(self.Q, axis=-1)
def plan(self):
self.pi = np.argmax(self.Q, axis=-1)
self.V = np.max(self.Q, axis=-1)
base_q_learner = QLearner(gwb)
print('GridWorld:')
base_q_learner.draw()
base_q_learner.learnQ()
base_q_learner.plan()
print('Learned policy:')
base_q_learner.draw('policy')
base_q_learner.draw('values')
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Q_learning_Exercise")
Section 2: \(\epsilon\)-greedy Exploration#
The QLearner above is purely greedy: it always picks the action with the highest current Q-estimate. If Q starts wrong (which it always does), the agent can get trapped:
It discovers one path to the goal and keeps repeating it, never finding a shorter one.
States that it never visits keep their optimistic Q-values, so it never updates them.
\(\epsilon\)-greedy adds a simple fix: with probability \(\epsilon\), ignore Q and pick a random action. This ensures every state-action pair is visited infinitely often, which guarantees convergence.
Video: Epsilon-greedy exploration#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Epsilon_greedy_Video")
Coding Exercise 2: Implement \(\epsilon\)-greedy exploration#
Extend QLearner so it sometimes explores randomly.
class QLearnerExplorer(QLearner):
def __init__(self, grid_world: GridWorldBase, gamma: float = 0.99,
epsilon: float = 0.1):
"""Constructs an MDP from a GridWorldBase object.
States should be numbered from left-to-right and from top-to-bottom.
Args:
grid_world: GridWorld specification.
gamma: Discount factor.
epsilon: Exploration rate.
"""
super().__init__(grid_world, gamma)
self.epsilon = epsilon
def pickAction(self) -> int:
"""With probability epsilon pick a random action; otherwise be greedy."""
##############################################################
# TODO: implement epsilon-greedy action selection.
# Hint: np.random.rand() < self.epsilon means 'explore'.
raise NotImplementedError("Implement epsilon-greedy pickAction!")
##############################################################
if np.random.rand() < self.epsilon:
return ... # explore: random action
return ... # exploit: greedy action
explorer = QLearnerExplorer(gwb)
print('GridWorld:')
explorer.draw()
explorer.learnQ()
explorer.plan()
print('Learned policy (with exploration):')
explorer.draw('policy')
explorer.draw('values')
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Epsilon_greedy_Exercise")
Summary#
\(Q\)-learning is a widely used RL algorithm known for its simplicity and effectiveness. It is essential because it allows an agent to learn how to make decisions in an environment without requiring a model of the environment and can be applied to a wide range of tasks.
Finally, \(\epsilon\)-greedy exploration is an important concept in RL because it helps to balance the exploration-exploitation tradeoff. Occasionally choosing a random action allows an agent to explore new areas of the environment and potentially discover better policies.