![]()

Performance Analysis of DQN Algorithm on the Lunar Lander task#
By Neuromatch Academy
Content creators: Raghuram Bharadwaj Diddigi, Geraud Nangue Tasse, Yamil Vidal, Sanjukta Krishnagopal, Sara Rajaee
Content editors: Shaonan Wang, Spiros Chavlis, Mobin Nesari
Objective#
In this project, the objective is to analyze the performance of the Deep Q-Learning algorithm on an exciting task- Lunar Lander. Before we describe the task, let us focus on two keywords here - analysis and performance. What exactly do we mean by these keywords in the context of Reinforcement Learning (RL)?
Setup#
Install dependencies#
Show code cell source
# @title Install dependencies
!pip install rarfile --quiet
!pip install ale-py --quiet
!pip install 'stable-baselines3[extra]' --quiet
!pip install -q gymnasium --quiet
!pip install swig --quiet
!pip install pyvirtualdisplay --quiet
!pip install pyglet --quiet
!pip install pygame --quiet
!pip install minigrid --quiet
!pip install -q swig --quiet
!pip install minigrid --quiet
!pip3 install box2d-py --quiet
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 363.4/363.4 MB 4.8 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 13.8/13.8 MB 120.4 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 24.6/24.6 MB 30.2 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 883.7/883.7 kB 45.8 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 664.8/664.8 MB 773.2 kB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 211.5/211.5 MB 5.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 56.3/56.3 MB 13.3 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 127.9/127.9 MB 7.6 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 207.5/207.5 MB 6.4 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 21.1/21.1 MB 101.0 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 184.5/184.5 kB 16.3 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.9/1.9 MB 39.4 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 984.0/984.0 kB 22.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 136.7/136.7 kB 5.0 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 374.5/374.5 kB 13.4 MB/s eta 0:00:00
?25h Preparing metadata (setup.py) ... ?25l?25hdone
Building wheel for box2d-py (setup.py) ... ?25l?25hdone
# Imports
import io
import os
import glob
import torch
import base64
import minigrid
import numpy as np
import matplotlib.pyplot as plt
import sys
import gymnasium
import stable_baselines3
from stable_baselines3 import DQN
from stable_baselines3.common.results_plotter import ts2xy, load_results
from stable_baselines3.common.callbacks import EvalCallback
from stable_baselines3.common.env_util import make_atari_env
import gymnasium as gym
from gymnasium import spaces
from gymnasium.envs.box2d.lunar_lander import *
from gymnasium.wrappers import RecordVideo
from ale_py import ALEInterface
import warnings
warnings.filterwarnings('ignore')
ale = ALEInterface()
Play Video function#
Show code cell source
# @title Play Video function
from IPython.display import HTML
from base64 import b64encode
from pyvirtualdisplay import Display
# create the directory to store the video(s)
os.makedirs("./video", exist_ok=True)
display = Display(visible=False, size=(1400, 900))
_ = display.start()
"""
Utility functions to enable video recording of gym environment
and displaying it.
To enable video, just do "env = wrap_env(env)""
"""
def render_mp4(videopath: str) -> str:
"""
Gets a string containing a b4-encoded version of the MP4 video
at the specified path.
"""
mp4 = open(videopath, 'rb').read()
base64_encoded_mp4 = b64encode(mp4).decode()
return f'<video width=400 controls><source src="data:video/mp4;' \
f'base64,{base64_encoded_mp4}" type="video/mp4"></video>'
Introduction#
In a standard RL setting, an agent learns optimal behavior from an environment through a feedback mechanism to maximize a given objective. Many algorithms have been proposed in the RL literature that an agent can apply to learn the optimal behavior. One such popular algorithm is the Deep Q-Network (DQN). This algorithm makes use of deep neural networks to compute optimal actions. In this project, your goal is to understand the effect of the number of neural network layers on the algorithm’s performance. The performance of the algorithm can be evaluated through two metrics - Speed and Stability.
Speed: How fast the algorithm reaches the maximum possible reward.
Stability In some applications (especially when online learning is involved), along with speed, stability of the algorithm, i.e., minimal fluctuations in performance, is equally important.
In this project, you should investigate the following question:
What is the impact of number of neural network layers on speed and stability of the algorithm?
You do not have to write the DQN code from scratch. We have provided a basic implementation of the DQN algorithm. You only have to tune the hyperparameters (neural network size, learning rate, etc), observe the performance, and analyze. More details on this are provided below.
Now, let us discuss the RL task we have chosen, i.e., Lunar Lander. This task consists of the lander and a landing pad marked by two flags. The episode starts with the lander moving downwards due to gravity. The objective is to land safely using different engines available on the lander with zero speed on the landing pad as quickly and fuel efficient as possible. Reward for moving from the top of the screen and landing on landing pad with zero speed is between 100 to 140 points. Each leg ground contact yields a reward of 10 points. Firing main engine leads to a reward of -0.3 points in each frame. Firing the side engine leads to a reward of -0.03 points in each frame. An additional reward of -100 or +100 points is received if the lander crashes or comes to rest respectively which also leads to end of the episode.
The input state of the Lunar Lander consists of following components:
Horizontal Position
Vertical Position
Horizontal Velocity
Vertical Velocity
Angle
Angular Velocity
Left Leg Contact
Right Leg Contact
The actions of the agents are:
Do Nothing
Fire Main Engine
Fire Left Engine
Fire Right Engine
Basic DQN Implementation#
We will now implement the DQN algorithm using the existing code base. We encourage you to understand this example and re-use it in an application/project of your choice!
Now, let us set some hyperparameters for our algorithm. This is the only part you would play around with, to solve the first part of the project.
nn_layers = [64, 64] # This is the configuration of your neural network. Currently, we have two layers, each consisting of 64 neurons.
# If you want three layers with 64 neurons each, set the value to [64,64,64] and so on.
learning_rate = 0.001 # This is the step-size with which the gradient descent is carried out.
# Tip: Use smaller step-sizes for larger networks.
Now, let us setup our model and the DQN algorithm.
log_dir = "/tmp/gym/"
os.makedirs(log_dir, exist_ok=True)
# Create environment
env_name = 'LunarLander-v3'
env = gym.make(env_name)
# You can also load other environments like cartpole, MountainCar, Acrobot.
# Refer to https://gym.openai.com/docs/ for descriptions.
# For example, if you would like to load Cartpole,
# just replace the above statement with "env = gym.make('CartPole-v1')".
env = stable_baselines3.common.monitor.Monitor(env, log_dir )
callback = EvalCallback(env, log_path=log_dir, deterministic=True) # For evaluating the performance of the agent periodically and logging the results.
policy_kwargs = dict(activation_fn=torch.nn.ReLU,
net_arch=nn_layers)
model = DQN("MlpPolicy", env,policy_kwargs = policy_kwargs,
learning_rate=learning_rate,
batch_size=1, # for simplicity, we are not doing batch update.
buffer_size=1, # size of experience of replay buffer. Set to 1 as batch update is not done
learning_starts=1, # learning starts immediately!
gamma=0.99, # discount facto. range is between 0 and 1.
tau = 1, # the soft update coefficient for updating the target network
target_update_interval=1, # update the target network immediately.
train_freq=(1,"step"), # train the network at every step.
max_grad_norm = 10, # the maximum value for the gradient clipping
exploration_initial_eps = 1, # initial value of random action probability
exploration_fraction = 0.5, # fraction of entire training period over which the exploration rate is reduced
gradient_steps = 1, # number of gradient steps
seed = 1, # seed for the pseudo random generators
verbose=0) # Set verbose to 1 to observe training logs. We encourage you to set the verbose to 1.
# You can also experiment with other RL algorithms like A2C, PPO, DDPG etc.
# Refer to https://stable-baselines3.readthedocs.io/en/master/guide/examples.html
# for documentation. For example, if you would like to run DDPG, just replace "DQN" above with "DDPG".
Before we train the model, let us look at an instance of Lunar Lander before training.
Note: The following code for rendering the video is taken from here.
env_name = 'LunarLander-v3'
env = gym.make(env_name)
print('State shape: ', env.observation_space.shape)
print('Number of actions: ', env.action_space.n)
State shape: (8,)
Number of actions: 4
env = gym.make(env_name, render_mode="rgb_array")
env = gym.wrappers.RecordVideo(
env,
video_folder="video",
name_prefix=f"{env_name}_pretraining",
episode_trigger=lambda episode_id: True
)
observation, _ = env.reset()
total_reward = 0
done = False
while not done:
action, states = model.predict(observation, deterministic=True)
observation, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
total_reward += reward
env.close()
print(f"\nTotal reward: {total_reward}")
# show video
html = render_mp4(f"video/{env_name}_pretraining-episode-0.mp4")
HTML(html)
Total reward: -557.177625601068
From the video above, we see that the lander has crashed! It is now the time for training!
model.learn(total_timesteps=100000, log_interval=10, callback=callback)
# The performance of the training will be printed every 10000 episodes. Change it to 1, if you wish to
# view the performance at every training episode.
Eval num_timesteps=10000, episode_reward=-316.03 +/- 96.76
Episode length: 87.40 +/- 8.11
New best mean reward!
Eval num_timesteps=20000, episode_reward=-72.12 +/- 28.46
Episode length: 88.20 +/- 3.87
New best mean reward!
Eval num_timesteps=30000, episode_reward=-464.56 +/- 68.66
Episode length: 156.40 +/- 48.96
Eval num_timesteps=40000, episode_reward=-252.16 +/- 13.86
Episode length: 595.80 +/- 114.32
Eval num_timesteps=50000, episode_reward=-27.78 +/- 83.38
Episode length: 894.00 +/- 130.32
New best mean reward!
Eval num_timesteps=60000, episode_reward=-67.35 +/- 103.69
Episode length: 441.60 +/- 75.51
Eval num_timesteps=70000, episode_reward=-154.81 +/- 74.24
Episode length: 485.20 +/- 310.82
Eval num_timesteps=80000, episode_reward=-100.42 +/- 40.64
Episode length: 844.20 +/- 200.15
Eval num_timesteps=90000, episode_reward=-40.68 +/- 17.53
Episode length: 1000.00 +/- 0.00
Eval num_timesteps=100000, episode_reward=137.78 +/- 96.34
Episode length: 275.40 +/- 185.90
New best mean reward!
<stable_baselines3.dqn.dqn.DQN at 0x7b9cf28afdd0>
The training takes time. We encourage you to analyze the output logs (set verbose to 1 to print the output logs). The main component of the logs that you should track is “ep_rew_mean” (mean of episode rewards). As the training proceeds, the value of “ep_rew_mean” should increase. The improvement need not be monotonic, but the trend should be upwards!
Along with training, we are also periodically evaluating the performance of the current model during the training. This was reported in logs as follows:
Eval num_timesteps=100000, episode_reward=63.41 +/- 130.02
Episode length: 259.80 +/- 47.47
Now, let us look at the visual performance of the lander.
Note: The performance varies across different seeds and runs. This code is not optimized to be stable across all runs and seeds. We hope you will be able to find an optimal configuration!
env = gym.make(env_name, render_mode="rgb_array")
env = gym.wrappers.RecordVideo(
env,
video_folder="video",
name_prefix=f"{env_name}_learned",
episode_trigger=lambda episode_id: True
)
observation, _ = env.reset()
total_reward = 0
done = False
while not done:
action, states = model.predict(observation, deterministic=True)
observation, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
total_reward += reward
env.close()
print(f"\nTotal reward: {total_reward}")
# show video
html = render_mp4(f"video/{env_name}_learned-episode-0.mp4")
HTML(html)
Total reward: 221.68495325461203
The lander has landed safely!!
Let us analyze its performance (speed and stability). For this purpose, we plot the number of time steps on the x-axis and the episodic reward given by the trained model on the y-axis.
x, y = ts2xy(load_results(log_dir), 'timesteps') # Organising the logged results in to a clean format for plotting.
plt.plot(x, y)
plt.ylim([-300, 300])
plt.xlabel('Timesteps')
plt.ylabel('Episode Rewards')
plt.show()
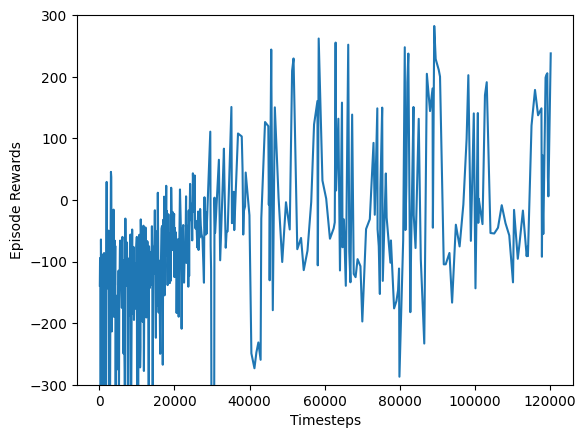
From the above plot, we observe that, although the maximum reward is achieved quickly. Achieving an episodic reward of > 200 is good. We see that the agent has achieved it in less than 50000 timesteps (speed is good!). However, there are a lot of fluctuations in the performance (stability is not good!).
Your objective now is to modify the model parameters (nn_layers, learning_rate in the code cell #2 above), run all the cells following it and investigate the stability and speed of the chosen configuration.
Additional Project Ideas#
1 Play with exploration-exploitation trade-off#
Exploration (selecting random actions) and exploitation (selecting greedy action) is a crucial component of the DQN algorithm. Explore random actions for a long time will slow down the training process. At the same time, if all actions are not explored enough, it might lead to a sub-optimal performance. In the DQN code above, we have used the following parameters:
exploration_initial_eps = 1 # initial value of random action probability. Range is between 0 and 1.
exploration_fraction = 0.5 # fraction of entire training period over which the exploration rate is reduced. Range is between 0 and 1.
exploration_final_eps = 0.05 # (set by defualt) final value of random action probability. Range is between 0 and 1.
Your objective is to play around with these parameters and analyze their performance (speed and stability). You can modify these parameters and set them as arguments in DQN(…,exploration_initial_eps = 1, exploration_fraction = 0.5, exploration_final_eps = 0.05,…).
2 Reward Shaping#
Your objective here is to construct a modified reward function that improves the performance of the Lunar Lander. To this end, you would have to create your own custom environment. An example of a custom environment is given below:
# Taken from https://stable-baselines3.readthedocs.io/en/master/guide/custom_env.html
class CustomEnv(gym.Env):
"""Custom Environment that follows gym interface"""
metadata = {'render.modes': ['human']}
def __init__(self, arg1, arg2):
super(CustomEnv, self).__init__()
# Define action and observation space
# They must be gym.spaces objects
# Example when using discrete actions:
self.action_space = spaces.Discrete(N_DISCRETE_ACTIONS)
# Example for using image as input (channel-first; channel-last also works):
self.observation_space = spaces.Box(low=0, high=255,
shape=(N_CHANNELS, HEIGHT, WIDTH), dtype=np.uint8)
def step(self, action):
...
return observation, reward, done, info
def reset(self):
...
return observation # reward, done, info can't be included
def render(self, mode='human'):
...
def close (self):
...
As you are only changing the reward structure, you can inherit the original Lunar Lander environment and modify just the “step” function. Focus on modifying the following part of the code in the “step” function.
class Custom_LunarLander(LunarLander):
def step(self, action):
assert self.lander is not None
# Update wind
assert self.lander is not None, "You forgot to call reset()"
if self.enable_wind and not (
self.legs[0].ground_contact or self.legs[1].ground_contact
):
# the function used for wind is tanh(sin(2 k x) + sin(pi k x)),
# which is proven to never be periodic, k = 0.01
wind_mag = (
math.tanh(
math.sin(0.02 * self.wind_idx)
+ (math.sin(math.pi * 0.01 * self.wind_idx))
)
* self.wind_power
)
self.wind_idx += 1
self.lander.ApplyForceToCenter(
(wind_mag, 0.0),
True,
)
# the function used for torque is tanh(sin(2 k x) + sin(pi k x)),
# which is proven to never be periodic, k = 0.01
torque_mag = math.tanh(
math.sin(0.02 * self.torque_idx)
+ (math.sin(math.pi * 0.01 * self.torque_idx))
) * (self.turbulence_power)
self.torque_idx += 1
self.lander.ApplyTorque(
(torque_mag),
True,
)
if self.continuous:
action = np.clip(action, -1, +1).astype(np.float32)
else:
assert self.action_space.contains(
action
), f"{action!r} ({type(action)}) invalid "
# Engines
tip = (math.sin(self.lander.angle), math.cos(self.lander.angle))
side = (-tip[1], tip[0])
dispersion = [self.np_random.uniform(-1.0, +1.0) / SCALE for _ in range(2)]
m_power = 0.0
if (self.continuous and action[0] > 0.0) or (
not self.continuous and action == 2
):
# Main engine
if self.continuous:
m_power = (np.clip(action[0], 0.0, 1.0) + 1.0) * 0.5 # 0.5..1.0
assert m_power >= 0.5 and m_power <= 1.0
else:
m_power = 1.0
# 4 is move a bit downwards, +-2 for randomness
ox = tip[0] * (4 / SCALE + 2 * dispersion[0]) + side[0] * dispersion[1]
oy = -tip[1] * (4 / SCALE + 2 * dispersion[0]) - side[1] * dispersion[1]
impulse_pos = (self.lander.position[0] + ox, self.lander.position[1] + oy)
p = self._create_particle(
3.5, # 3.5 is here to make particle speed adequate
impulse_pos[0],
impulse_pos[1],
m_power,
) # particles are just a decoration
p.ApplyLinearImpulse(
(ox * MAIN_ENGINE_POWER * m_power, oy * MAIN_ENGINE_POWER * m_power),
impulse_pos,
True,
)
self.lander.ApplyLinearImpulse(
(-ox * MAIN_ENGINE_POWER * m_power, -oy * MAIN_ENGINE_POWER * m_power),
impulse_pos,
True,
)
s_power = 0.0
if (self.continuous and np.abs(action[1]) > 0.5) or (
not self.continuous and action in [1, 3]
):
# Orientation engines
if self.continuous:
direction = np.sign(action[1])
s_power = np.clip(np.abs(action[1]), 0.5, 1.0)
assert s_power >= 0.5 and s_power <= 1.0
else:
direction = action - 2
s_power = 1.0
ox = tip[0] * dispersion[0] + side[0] * (
3 * dispersion[1] + direction * SIDE_ENGINE_AWAY / SCALE
)
oy = -tip[1] * dispersion[0] - side[1] * (
3 * dispersion[1] + direction * SIDE_ENGINE_AWAY / SCALE
)
impulse_pos = (
self.lander.position[0] + ox - tip[0] * 17 / SCALE,
self.lander.position[1] + oy + tip[1] * SIDE_ENGINE_HEIGHT / SCALE,
)
p = self._create_particle(0.7, impulse_pos[0], impulse_pos[1], s_power)
p.ApplyLinearImpulse(
(ox * SIDE_ENGINE_POWER * s_power, oy * SIDE_ENGINE_POWER * s_power),
impulse_pos,
True,
)
self.lander.ApplyLinearImpulse(
(-ox * SIDE_ENGINE_POWER * s_power, -oy * SIDE_ENGINE_POWER * s_power),
impulse_pos,
True,
)
self.world.Step(1.0 / FPS, 6 * 30, 2 * 30)
pos = self.lander.position
vel = self.lander.linearVelocity
state = [
(pos.x - VIEWPORT_W / SCALE / 2) / (VIEWPORT_W / SCALE / 2),
(pos.y - (self.helipad_y + LEG_DOWN / SCALE)) / (VIEWPORT_H / SCALE / 2),
vel.x * (VIEWPORT_W / SCALE / 2) / FPS,
vel.y * (VIEWPORT_H / SCALE / 2) / FPS,
self.lander.angle,
20.0 * self.lander.angularVelocity / FPS,
1.0 if self.legs[0].ground_contact else 0.0,
1.0 if self.legs[1].ground_contact else 0.0,
]
assert len(state) == 8
# Compare with / without shaping, referring the state description below
'''
state[0]: the horizontal coordinate
state[1]: the vertical coordinate
state[2]: the horizontal speed
state[3]: the vertical speed
state[4]: the angle
state[5]: the angular speed
state[6]: first leg contact
state[7]: second leg contact
'''
reward = 0
shaping = (
-100 * np.sqrt(state[0] * state[0] + state[1] * state[1])
- 100 * np.sqrt(state[2] * state[2] + state[3] * state[3])
- 100 * abs(state[4])
+ 10 * state[6]
+ 10 * state[7]
) # And ten points for legs contact, the idea is if you
# lose contact again after landing, you get negative reward
if self.prev_shaping is not None:
reward = shaping - self.prev_shaping
self.prev_shaping = shaping
reward -= (
m_power * 0.30
) # less fuel spent is better, about -30 for heuristic landing
reward -= s_power * 0.03
terminated = False
if self.game_over or abs(state[0]) >= 1.0:
terminated = True
reward = -100
if not self.lander.awake:
terminated = True
reward = +100
if self.render_mode == "human":
self.render()
return np.array(state, dtype=np.float32), reward, terminated, False, {}
Once you have cutomized your own environment, you can execute that environment by just calling:
## Enter the name of the custome environment you created and uncomment the line below.
# env = Custom_LunarLander()
Note: Refer to this page, if you would like to create more complex environments.
3 Identify the state information crucial to its performance.#
Your objective here is to alter the input state information and analyze the performance. The input state of the Lunar Lander consists of following components:
Horizontal Position
Vertical Position
Horizontal Velocity
Vertical Velocity
Angle
Angular Velocity
Left Leg Contact
Right Leg Contact
You can train the algorithm by masking one of the eight components at a time and understand how that affects the performance of the algorithm. Similar to the reward shaping task, you would have to create a custom environment and modify the state space. Again, you can inherit all the necessary functions and modify the following portion of the “Step” function:
def step(self, actions):
...
...
...
state = [ # Remove one component at a time to investigate the effect on performance!
(pos.x - VIEWPORT_W / SCALE / 2) / (VIEWPORT_W / SCALE / 2),
(pos.y - (self.helipad_y + LEG_DOWN / SCALE)) / (VIEWPORT_H / SCALE / 2),
vel.x * (VIEWPORT_W / SCALE / 2) / FPS,
vel.y * (VIEWPORT_H / SCALE / 2) / FPS,
self.lander.angle,
20.0 * self.lander.angularVelocity / FPS,
1.0 if self.legs[0].ground_contact else 0.0,
1.0 if self.legs[1].ground_contact else 0.0,
]
4 Extension to Atari Games#
In the Lunar Lander task, the input to the algorithm is a vector of state information. Deep RL algorithms can also be applied when the input to the training is image frames, which is the case in the Atari games. For example, consider an Atari game - Pong. In this environment, the observation is an RGB image of the screen, which is an array of shape (210, 160, 3). To train the Pong game, you can start with the following sample code:
## Taken from: https://colab.research.google.com/github/Stable-Baselines-Team/rl-colab-notebooks/blob/sb3/atari_games.ipynb#scrollTo=f3K4rMXwimBO
env = make_atari_env('PongNoFrameskip-v4', n_envs=4, seed=0)
## Atari Games take a lot of memory. Following commands crash on Coalb. Run the following code on Colab Pro or your local Jupyter notebook!
# env = VecFrameStack(env, n_stack=4)
# model = DQN('CnnPolicy', env, verbose=1) # Note the difference here! We use 'CnnPolicy" here instead of 'MlpPolicy' as the input is frames.
# model.learn(total_timesteps=1) #change the number of timesteps as desired and run this command!
5 Obstacle Avoidance and Transfer Learning#
Your obstacle here is to add an obstacle in the path of the lunar lander (by creating a custom environment as described in point 2 above) and train the model such that the lander lands safely, avoiding collisions.
You would first want to devise a mechansim for adding obstacles. For example, you could have an imaginary obstacle at some horizantal and vertical position cooridnates and modify the reward function such that a penalty is levied if the lander comes close to it.
An interesting approach to solve this problem is to apply the techniques of transfer learning. For example, you could initialise the neural network model with the weights of the trained model on the original problem to improve the sample effeciency. This can be done using the following code:
## Specify the load path and uncomment below:
# model = load(load_path,
# env=gym.make('LunarLander-v2'),
# custom_objects=None, **kwargs)
Following are some of the resources on transfer learning that you would want to start with.
Research Papers
Surveys:
Taylor, M. E., et al. (2009). Transfer learning for reinforcement learning domains. url: www.jmlr.org/papers/volume10/taylor09a/taylor09a
Long, Old, Highly cited
Lazaric, A. (2012). Transfer in reinforcement learning: a framework and a survey. url: hal.inria.fr/docs/00/77/26/26/PDF/transfer
Medium, Old, Good for a quick read
Zhu, Z., Lin, K., & Zhou, J. (2020). Transfer learning in deep reinforcement learning. arxiv:2009.07888
Medium, Recent, Good for a quick read
Barreto, A., et al. (2016). Successor features for transfer in reinforcement learning. arxiv:1606.05312
Specific example
5(b) Transfer Learning in minigrid environment#
These are some simple gridworld gym environments designed to be particularly simple, lightweight and fast. Refer to this repo for a description of the environments. An example to load a minigrid environment is given below.
env = gym.make('MiniGrid-Empty-5x5-v0', render_mode='rgb_array')
You can train a standard DQN agent in this env by wrapping the env with full image observation wrappers:
env = minigrid.wrappers.ImgObsWrapper(minigrid.wrappers.RGBImgObsWrapper(env))
Note that with full image observations, the shape of the image observations may differ between envs. For e.g., MiniGrid-Empty-5x5-v0 is (40,40,3) while MiniGrid-Empty-8x8-v0 is (64,64,3). So you may need to resize the observations for transfer learning to work with the same DQN architecture.
Now try training a DQN (or another method) in one (or multiple) minigrid env(s),and see if that knowledge transfers to another (or multiple other) minigrid env(s).
6 Preference-Based RL (PBRL)#
PBRL is an exciting sub-area in RL where the traditional reward structure is replaced with human preferences. This setting is very useful in applications where it is difficult to construct a reward function.
In the earlier section, we have successfully trained the lunar lander to land safely. Here, the path that the lander follows to land safely can be arbitrary. In this project, using the techniques of PBRL, you will solve the lunar lander problem with an additional requirement that the lander should follow a specially curated path (for example, a straight line path). Following are some of the resources that will help you to get started with this project.
Research papers:
Code Bases: