![]()

NMA Robolympics: Controlling robots using reinforcement learning#
By Neuromatch Academy
Content creators: Roman Vaxenburg, Diptodip Deb, Srinivas Turaga, Mobin Nesari
Production editors: Spiros Chavlis
Objectives#
Objective#
This notebook provides a comprehensive example of modern reinforcement learning infrastructure, training workflows, and performance analysis using state-of-the-art algorithms. We will use the Gymnasium MuJoCo locomotion environment and Stable Baselines 3 reinforcement learning agents to learn policies for the challenging 2D Hopper-v5 robot locomotion task.
We will demonstrate how to set up and analyze the environment, train multiple RL algorithms (A2C, DDPG, PPO, SAC, TD3), and visualize both learning curves and agent performance through video recordings. This example provides a solid foundation for understanding different RL paradigms - from on-policy methods like PPO to off-policy algorithms like SAC and TD3. The notebook includes a random agent baseline to clearly illustrate the learning progress and effectiveness of each algorithm.
Even though this example focuses on the Hopper locomotion task, you can easily extend it to more complex environments such as Ant-v5, Humanoid-v5, or Walker2d-v5 by simply changing the environment name. We encourage you to explore the Gymnasium MuJoCo environments documentation to understand the observation and action spaces of different robots.
We would also suggest exploring the Stable Baselines 3 documentation for advanced hyperparameter tuning and the PyTorch ecosystem for custom network architectures.
For a comprehensive introduction to Reinforcement Learning theory and practice, we recommend checking out the Spinning Up in Deep RL course by OpenAI and the classic Sutton & Barto textbook.
Colab limits#
Please note that due to the Colab usage limits on the one hand, and the compute requirements of the project on the other hand, most likely you won’t be able to leverage Colab’s GPU for a sufficient amount of time. Instead, we suggest working in CPU-only mode (it shouldn’t slow you down very much, typical RL workloads are CPU-bound anyway). Make sure you’re not using GPU by doing Runtime -> Change runtime type -> Hardware accelerator -> None. bold text
Setup#
# @title Install dependencies
# @markdown In the first cell we'll install all of the necessary dependencies.
!pip install gymnasium[mujoco] --quiet
!pip install stable-baselines3[extra] --quiet
!pip install torch torchvision torchaudio --quiet
!pip install imageio --quiet
!pip install imageio-ffmpeg --quiet
!pip install pyvirtualdisplay --quiet
!pip install pyglet==1.5.27 --quiet
!apt-get install -y xvfb python-opengl ffmpeg
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 44.4/44.4 kB 1.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 6.6/6.6 MB 76.7 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 243.5/243.5 kB 14.2 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 965.4/965.4 kB 23.1 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 363.4/363.4 MB 4.6 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 13.8/13.8 MB 93.8 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 24.6/24.6 MB 70.0 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 883.7/883.7 kB 47.1 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 664.8/664.8 MB 2.1 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 211.5/211.5 MB 4.7 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 56.3/56.3 MB 11.5 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 127.9/127.9 MB 7.0 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 207.5/207.5 MB 6.3 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 21.1/21.1 MB 64.0 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 184.5/184.5 kB 10.3 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 23.5 MB/s eta 0:00:00
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
E: Unable to locate package python-opengl
# @title Setup virtual display
# @markdown In this cell, we will setup a virtual display to capture image and videos
import os
os.system("Xvfb :1 -screen 0 1024x768x24 &")
os.environ['DISPLAY'] = ':1'
# @title Imports
# @markdown Imports required libraries and modules
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
from stable_baselines3 import A2C, DDPG, PPO, SAC, TD3
from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.results_plotter import load_results, ts2xy
from stable_baselines3.common.noise import NormalActionNoise, OrnsteinUhlenbeckActionNoise
from stable_baselines3.common.callbacks import BaseCallback
import torch
import imageio
from IPython.display import Video, display
import warnings
from IPython.display import HTML
import base64
warnings.filterwarnings('ignore')
# @title Training parameters
# @markdown `TOTAL_TIMESTEPS` has been set to 10000, feel free to change it
TOTAL_TIMESTEPS = 10000
LOG_DIR = "./logs/"
VIDEO_DIR = "./videos/"
# @title Create directories
os.makedirs(LOG_DIR, exist_ok=True)
os.makedirs(VIDEO_DIR, exist_ok=True)
# @title Figure settings
import ipywidgets as widgets # interactive display
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/content-creation/main/nma.mplstyle")
# @title Record and display videos utilities
# @markdown Using these two functions to record and display video inline
def record_video(model, env_name, video_filename, num_episodes=1):
"""Record video of trained model playing the environment"""
# Create environment for recording
env = gym.make(env_name, render_mode='rgb_array')
frames = []
for episode in range(num_episodes):
obs, info = env.reset()
done = False
truncated = False
episode_reward = 0
while not (done or truncated):
# Render frame
frame = env.render()
frames.append(frame)
# Get action from model
action, _ = model.predict(obs, deterministic=True)
# Take step in environment
obs, reward, done, truncated, info = env.step(action)
episode_reward += reward
print(f"Episode {episode + 1} reward: {episode_reward:.2f}")
env.close()
# Save video
imageio.mimsave(video_filename, frames, fps=30)
print(f"Video saved as {video_filename}")
return episode_reward
def display_video_html(video_path, title="Video"):
"""Display video using HTML5 video player"""
video = open(video_path, 'rb').read()
video_encoded = base64.b64encode(video).decode('ascii')
video_tag = f'''
<h3>{title}</h3>
<video width="600" height="400" controls>
<source src="data:video/mp4;base64,{video_encoded}" type="video/mp4">
Your browser does not support the video tag.
</video>
'''
return HTML(video_tag)
# @title Callback logging
# @markdown Callback for logging training progress
class TrainingCallback(BaseCallback):
def __init__(self, verbose=0):
super(TrainingCallback, self).__init__(verbose)
self.rewards = []
self.episode_lengths = []
def _on_step(self) -> bool:
if len(self.locals.get('infos', [])) > 0:
for info in self.locals['infos']:
if 'episode' in info:
self.rewards.append(info['episode']['r'])
self.episode_lengths.append(info['episode']['l'])
return True
🦗 Hopper-v5 Environment#
Overview#
The Hopper-v5 is a 2D one-legged robot locomotion task from the MuJoCo physics simulator, available through Gymnasium. The agent must learn to control a monopedal robot to hop forward as fast as possible while maintaining balance and avoiding falls. —bold text
Environment Specifications#
Action Space
Type:
Box(3,)- Continuous action spaceRange:
[-1, 1]for each action dimensionDescription: 3-dimensional continuous control vector representing torques applied to joints
action[0]: Torque applied to the hip joint (thigh-leg connection)action[1]: Torque applied to the knee joint (leg-foot connection)action[2]: Torque applied to the ankle joint (foot-ground interaction)
Observation Space
Type:
Box(11,)- 11-dimensional continuous observation vectorComponents:
obs[0]: z-coordinate of the torso (height)obs[1]: angle of the torso (pitch)obs[2]: angle of the thigh jointobs[3]: angle of the leg jointobs[4]: angle of the foot jointobs[5]: velocity of the z-coordinate of the torsoobs[6]: angular velocity of the torsoobs[7]: angular velocity of the thigh jointobs[8]: angular velocity of the leg jointobs[9]: angular velocity of the foot jointobs[10]: x-coordinate of the torso (horizontal position)
env_name = "Hopper-v5"
env = gym.make(env_name)
print(f"Environment: {env_name}")
print(f"Observation space: {env.observation_space}")
print(f"Action space: {env.action_space}")
print(f"Action space shape: {env.action_space.shape}")
print(f"Action space bounds: [{env.action_space.low}, {env.action_space.high}]")
Environment: Hopper-v5
Observation space: Box(-inf, inf, (11,), float64)
Action space: Box(-1.0, 1.0, (3,), float32)
Action space shape: (3,)
Action space bounds: [[-1. -1. -1.], [1. 1. 1.]]
Reward Function#
The reward function encourages forward locomotion while penalizing control effort:
reward = reward_forward + reward_control + reward_survive
Forward Reward:
reward_forward = (x_after - x_before) / dtEncourages forward movement by rewarding positive x-axis velocity
Typical range: 0.5 to 3.0 for successful hopping
Control Penalty:
reward_control = -0.001 * sum(action²)Penalizes large control inputs to encourage energy efficiency
Typical range: -0.003 to 0.0
Survival Reward:
reward_survive = 1.0Constant reward for staying alive (not terminating)
Encourages the agent to maintain balance
Termination Conditions#
The episode terminates when any of the following conditions are met:
Height Constraint:
z_torso < 0.7The robot falls below a minimum height threshold
Indicates the robot has fallen or collapsed
Angle Constraint:
|torso_angle| > 0.2The torso angle exceeds ±0.2 radians (~±11.5 degrees)
Prevents the robot from falling over backward or forward
Maximum Episode Length: 1000 timesteps
Episodes are truncated after 1000 steps to prevent infinite episodes
Corresponds to 1000 * 0.008 = 8 seconds of simulation time
Episode Information#
Physics Timestep: 0.008 seconds per step
Max Episode Steps: 1000
Max Episode Duration: ~8 seconds
Typical Episode Reward:
Random agent: -200 to 200
Well-trained agent: 1000 to 4000+
Environment Preview#
# Display environment image
print("\n🎮 Environment Preview:")
print("=" * 30)
# Capture and display a sample frame from the environment
env_preview = gym.make(env_name, render_mode='rgb_array')
obs, info = env_preview.reset()
frame = env_preview.render()
plt.figure(figsize=(10, 6))
plt.imshow(frame)
plt.title("Hopper-v5 Environment", fontsize=16, fontweight='bold')
plt.text(0.5, -0.1, "The Hopper is a 2D one-legged robot that must learn to hop forward.\n"
"Observation: 11-dimensional vector (position, velocity, joint angles)\n"
"Action: 3-dimensional continuous control (torques for hip, knee, foot joints)\n"
"Goal: Maximize forward velocity while maintaining balance",
transform=plt.gca().transAxes, ha='center', va='top', fontsize=12,
bbox=dict(boxstyle="round,pad=0.3", facecolor="lightblue", alpha=0.7))
plt.axis('off')
plt.tight_layout()
plt.show()
🎮 Environment Preview:
==============================
Agents#
🎲 Random Agent#
# Create random agent for comparison
class RandomAgent:
def __init__(self, action_space):
self.action_space = action_space
def predict(self, obs, deterministic=True):
return self.action_space.sample(), None
print("Generating random agent video for comparison...")
# Create random agent
random_agent = RandomAgent(env.action_space)
# Generate random agent video
video_path_random = os.path.join(VIDEO_DIR, "random_hopper.mp4")
reward_random = record_video(random_agent, env_name, video_path_random)
print("Random agent video generated successfully ✅")
print("\n🎲 Random Agent (Baseline):")
display(display_video_html(video_path_random, "Random Agent Playing Hopper-v5"))
print(f"Episode reward: {reward_random:.2f}")
print("📝 Note: Random agent takes completely random actions - this shows untrained performance")
Generating random agent video for comparison...
Episode 1 reward: 13.62
Video saved as ./videos/random_hopper.mp4
Random agent video generated successfully ✅
🎲 Random Agent (Baseline):
Random Agent Playing Hopper-v5
Episode reward: 13.62
📝 Note: Random agent takes completely random actions - this shows untrained performance
1️⃣ A2C (Advantage Actor-Critic)#
A2C is a synchronous, on-policy reinforcement learning algorithm that combines the benefits of both value-based and policy-based methods. It uses an actor-critic architecture where the actor learns a policy π(a|s) to select actions, while the critic learns a value function V(s) to estimate state values.
Key Features:#
Advantage Function: Uses the advantage A(s,a) = Q(s,a) - V(s) to reduce variance in policy gradient updates
On-Policy: Learns from actions taken by the current policy, ensuring stable learning
Synchronous Updates: All parallel environments step simultaneously before updating the model
Shared Networks: Actor and critic often share lower-level representations for efficiency
Algorithm Components:#
Actor Network: Outputs action probabilities for continuous control (via mean and std)
Critic Network: Estimates state values V(s) for advantage calculation
Advantage Estimation: A(s,a) = r + γV(s’) - V(s), where γ is the discount factor
Hyperparameters:#
Learning Rate: 0.0007 (balanced for stable convergence)
n_steps: 5 (number of steps before each update)
Gamma: 0.99 (discount factor for future rewards)
GAE Lambda: 1.0 (Generalized Advantage Estimation parameter)
A2C is particularly effective for continuous control tasks like Hopper due to its stable policy updates and efficient use of experience. It’s simpler than PPO but often achieves competitive performance with proper tuning.
print("Training A2C...")
# Create monitored environment
env_a2c = Monitor(gym.make(env_name), LOG_DIR + "a2c/")
env_a2c = DummyVecEnv([lambda: env_a2c])
# Initialize A2C model
model_a2c = A2C(
"MlpPolicy",
env_a2c,
verbose=1,
tensorboard_log=LOG_DIR + "a2c_tensorboard/",
learning_rate=0.0007,
n_steps=5,
gamma=0.99,
gae_lambda=1.0,
ent_coef=0.01,
vf_coef=0.5,
max_grad_norm=0.5,
use_rms_prop=True,
rms_prop_eps=1e-05,
use_sde=False,
sde_sample_freq=-1,
normalize_advantage=False,
device="auto"
)
# Train A2C
callback_a2c = TrainingCallback()
model_a2c.learn(total_timesteps=TOTAL_TIMESTEPS, callback=callback_a2c)
model_a2c.save("a2c_hopper")
video_path_a2c = os.path.join(VIDEO_DIR, "a2c_hopper.mp4")
reward_a2c = record_video(model_a2c, env_name, video_path_a2c)
print("A2C training completed! ✅")
Training A2C...
Using cpu device
Logging to ./logs/a2c_tensorboard/A2C_1
------------------------------------
| rollout/ | |
| ep_len_mean | 27.4 |
| ep_rew_mean | 24.5 |
| time/ | |
| fps | 301 |
| iterations | 100 |
| time_elapsed | 1 |
| total_timesteps | 500 |
| train/ | |
| entropy_loss | -4.19 |
| explained_variance | 0.214 |
| learning_rate | 0.0007 |
| n_updates | 99 |
| policy_loss | -8.99 |
| std | 0.978 |
| value_loss | 24 |
------------------------------------
------------------------------------
| rollout/ | |
| ep_len_mean | 33 |
| ep_rew_mean | 33.5 |
| time/ | |
| fps | 302 |
| iterations | 200 |
| time_elapsed | 3 |
| total_timesteps | 1000 |
| train/ | |
| entropy_loss | -4.18 |
| explained_variance | 0.0661 |
| learning_rate | 0.0007 |
| n_updates | 199 |
| policy_loss | -0.864 |
| std | 0.976 |
| value_loss | 28.6 |
------------------------------------
------------------------------------
| rollout/ | |
| ep_len_mean | 36.1 |
| ep_rew_mean | 38.8 |
| time/ | |
| fps | 335 |
| iterations | 300 |
| time_elapsed | 4 |
| total_timesteps | 1500 |
| train/ | |
| entropy_loss | -4.18 |
| explained_variance | 0.0403 |
| learning_rate | 0.0007 |
| n_updates | 299 |
| policy_loss | 6.36 |
| std | 0.976 |
| value_loss | 3.68 |
------------------------------------
------------------------------------
| rollout/ | |
| ep_len_mean | 37.7 |
| ep_rew_mean | 41.5 |
| time/ | |
| fps | 354 |
| iterations | 400 |
| time_elapsed | 5 |
| total_timesteps | 2000 |
| train/ | |
| entropy_loss | -4.17 |
| explained_variance | -0.0175 |
| learning_rate | 0.0007 |
| n_updates | 399 |
| policy_loss | 14.8 |
| std | 0.972 |
| value_loss | 12.2 |
------------------------------------
------------------------------------
| rollout/ | |
| ep_len_mean | 42.6 |
| ep_rew_mean | 50.4 |
| time/ | |
| fps | 368 |
| iterations | 500 |
| time_elapsed | 6 |
| total_timesteps | 2500 |
| train/ | |
| entropy_loss | -4.16 |
| explained_variance | 0.0533 |
| learning_rate | 0.0007 |
| n_updates | 499 |
| policy_loss | 11.6 |
| std | 0.968 |
| value_loss | 9.43 |
------------------------------------
-------------------------------------
| rollout/ | |
| ep_len_mean | 47.7 |
| ep_rew_mean | 59.6 |
| time/ | |
| fps | 374 |
| iterations | 600 |
| time_elapsed | 8 |
| total_timesteps | 3000 |
| train/ | |
| entropy_loss | -4.17 |
| explained_variance | -0.000703 |
| learning_rate | 0.0007 |
| n_updates | 599 |
| policy_loss | 19.8 |
| std | 0.972 |
| value_loss | 25 |
-------------------------------------
------------------------------------
| rollout/ | |
| ep_len_mean | 50.5 |
| ep_rew_mean | 65.5 |
| time/ | |
| fps | 378 |
| iterations | 700 |
| time_elapsed | 9 |
| total_timesteps | 3500 |
| train/ | |
| entropy_loss | -4.17 |
| explained_variance | 0.00241 |
| learning_rate | 0.0007 |
| n_updates | 699 |
| policy_loss | 8.74 |
| std | 0.972 |
| value_loss | 7.14 |
------------------------------------
------------------------------------
| rollout/ | |
| ep_len_mean | 55.8 |
| ep_rew_mean | 74.4 |
| time/ | |
| fps | 384 |
| iterations | 800 |
| time_elapsed | 10 |
| total_timesteps | 4000 |
| train/ | |
| entropy_loss | -4.18 |
| explained_variance | 0.000166 |
| learning_rate | 0.0007 |
| n_updates | 799 |
| policy_loss | 17.3 |
| std | 0.975 |
| value_loss | 20.1 |
------------------------------------
------------------------------------
| rollout/ | |
| ep_len_mean | 62.1 |
| ep_rew_mean | 85.5 |
| time/ | |
| fps | 385 |
| iterations | 900 |
| time_elapsed | 11 |
| total_timesteps | 4500 |
| train/ | |
| entropy_loss | -4.18 |
| explained_variance | 0.00555 |
| learning_rate | 0.0007 |
| n_updates | 899 |
| policy_loss | 8.82 |
| std | 0.976 |
| value_loss | 4.9 |
------------------------------------
------------------------------------
| rollout/ | |
| ep_len_mean | 66.2 |
| ep_rew_mean | 92.8 |
| time/ | |
| fps | 388 |
| iterations | 1000 |
| time_elapsed | 12 |
| total_timesteps | 5000 |
| train/ | |
| entropy_loss | -4.19 |
| explained_variance | -0.00486 |
| learning_rate | 0.0007 |
| n_updates | 999 |
| policy_loss | 2.31 |
| std | 0.979 |
| value_loss | 0.327 |
------------------------------------
------------------------------------
| rollout/ | |
| ep_len_mean | 69.4 |
| ep_rew_mean | 98.5 |
| time/ | |
| fps | 380 |
| iterations | 1100 |
| time_elapsed | 14 |
| total_timesteps | 5500 |
| train/ | |
| entropy_loss | -4.17 |
| explained_variance | 9.01e-05 |
| learning_rate | 0.0007 |
| n_updates | 1099 |
| policy_loss | 24 |
| std | 0.971 |
| value_loss | 43.5 |
------------------------------------
-------------------------------------
| rollout/ | |
| ep_len_mean | 72.9 |
| ep_rew_mean | 106 |
| time/ | |
| fps | 372 |
| iterations | 1200 |
| time_elapsed | 16 |
| total_timesteps | 6000 |
| train/ | |
| entropy_loss | -4.16 |
| explained_variance | -6.71e-05 |
| learning_rate | 0.0007 |
| n_updates | 1199 |
| policy_loss | 25.3 |
| std | 0.97 |
| value_loss | 34.2 |
-------------------------------------
------------------------------------
| rollout/ | |
| ep_len_mean | 75.3 |
| ep_rew_mean | 113 |
| time/ | |
| fps | 375 |
| iterations | 1300 |
| time_elapsed | 17 |
| total_timesteps | 6500 |
| train/ | |
| entropy_loss | -4.17 |
| explained_variance | 1.21e-05 |
| learning_rate | 0.0007 |
| n_updates | 1299 |
| policy_loss | 27.5 |
| std | 0.971 |
| value_loss | 49.8 |
------------------------------------
-------------------------------------
| rollout/ | |
| ep_len_mean | 76.7 |
| ep_rew_mean | 118 |
| time/ | |
| fps | 378 |
| iterations | 1400 |
| time_elapsed | 18 |
| total_timesteps | 7000 |
| train/ | |
| entropy_loss | -4.16 |
| explained_variance | -0.000594 |
| learning_rate | 0.0007 |
| n_updates | 1399 |
| policy_loss | 5.94 |
| std | 0.969 |
| value_loss | 1.94 |
-------------------------------------
------------------------------------
| rollout/ | |
| ep_len_mean | 76.5 |
| ep_rew_mean | 119 |
| time/ | |
| fps | 381 |
| iterations | 1500 |
| time_elapsed | 19 |
| total_timesteps | 7500 |
| train/ | |
| entropy_loss | -4.14 |
| explained_variance | -8.9e-05 |
| learning_rate | 0.0007 |
| n_updates | 1499 |
| policy_loss | 13.9 |
| std | 0.962 |
| value_loss | 14.6 |
------------------------------------
-------------------------------------
| rollout/ | |
| ep_len_mean | 78.9 |
| ep_rew_mean | 125 |
| time/ | |
| fps | 382 |
| iterations | 1600 |
| time_elapsed | 20 |
| total_timesteps | 8000 |
| train/ | |
| entropy_loss | -4.13 |
| explained_variance | -0.000144 |
| learning_rate | 0.0007 |
| n_updates | 1599 |
| policy_loss | 15.8 |
| std | 0.959 |
| value_loss | 19.4 |
-------------------------------------
-------------------------------------
| rollout/ | |
| ep_len_mean | 82.8 |
| ep_rew_mean | 134 |
| time/ | |
| fps | 385 |
| iterations | 1700 |
| time_elapsed | 22 |
| total_timesteps | 8500 |
| train/ | |
| entropy_loss | -4.13 |
| explained_variance | -6.91e-06 |
| learning_rate | 0.0007 |
| n_updates | 1699 |
| policy_loss | 9 |
| std | 0.958 |
| value_loss | 6.3 |
-------------------------------------
-------------------------------------
| rollout/ | |
| ep_len_mean | 85.2 |
| ep_rew_mean | 141 |
| time/ | |
| fps | 387 |
| iterations | 1800 |
| time_elapsed | 23 |
| total_timesteps | 9000 |
| train/ | |
| entropy_loss | -4.12 |
| explained_variance | -3.58e-07 |
| learning_rate | 0.0007 |
| n_updates | 1799 |
| policy_loss | 11.9 |
| std | 0.957 |
| value_loss | 8.69 |
-------------------------------------
-------------------------------------
| rollout/ | |
| ep_len_mean | 87.3 |
| ep_rew_mean | 147 |
| time/ | |
| fps | 390 |
| iterations | 1900 |
| time_elapsed | 24 |
| total_timesteps | 9500 |
| train/ | |
| entropy_loss | -4.13 |
| explained_variance | -4.05e-05 |
| learning_rate | 0.0007 |
| n_updates | 1899 |
| policy_loss | 14.6 |
| std | 0.959 |
| value_loss | 16.6 |
-------------------------------------
-------------------------------------
| rollout/ | |
| ep_len_mean | 88.4 |
| ep_rew_mean | 151 |
| time/ | |
| fps | 392 |
| iterations | 2000 |
| time_elapsed | 25 |
| total_timesteps | 10000 |
| train/ | |
| entropy_loss | -4.12 |
| explained_variance | -2.38e-07 |
| learning_rate | 0.0007 |
| n_updates | 1999 |
| policy_loss | 15.2 |
| std | 0.956 |
| value_loss | 5.41 |
-------------------------------------
Episode 1 reward: 75.55
Video saved as ./videos/a2c_hopper.mp4
A2C training completed! ✅
print("\n🤖 A2C Performance:")
display(display_video_html(video_path_a2c, "A2C Agent Playing Hopper-v5"))
print(f"Final episode reward: {reward_a2c:.2f}")
🤖 A2C Performance:
A2C Agent Playing Hopper-v5
Final episode reward: 75.55
2️⃣ DDPG (Deep Deterministic Policy Gradient)#
DDPG is an off-policy reinforcement learning algorithm designed for continuous action spaces. It combines the actor-critic architecture with deep neural networks and borrows ideas from Deep Q-Networks (DQN) to create a deterministic policy gradient method that can handle high-dimensional, continuous control tasks.
Key Features:#
Deterministic Policy: Learns a deterministic policy μ(s) that directly outputs actions rather than action probabilities
Off-Policy Learning: Uses experience replay to learn from past experiences, improving sample efficiency
Target Networks: Employs slowly-updating target networks for both actor and critic to stabilize training
Exploration Strategy: Uses noise injection (typically Ornstein-Uhlenbeck) during training for exploration
Algorithm Components:#
Actor Network: Outputs deterministic actions μ(s|θ^μ) for continuous control
Critic Network: Estimates action-value function Q(s,a|θ^Q) for given state-action pairs
Target Networks: Soft-updated copies of actor (μ’) and critic (Q’) networks for stable learning
Experience Replay Buffer: Stores transitions (s,a,r,s’) for off-policy learning
Learning Process:#
Critic Update: Minimize TD error using target Q-values: L = E[(Q(s,a) - y)²] where y = r + γQ’(s’,μ’(s’))
Actor Update: Maximize expected Q-value: ∇θ^μ J ≈ E[∇aQ(s,a)|s,a=μ(s) ∇θ^μ μ(s)]
Target Update: Soft update both target networks: θ’ ← τθ + (1-τ)θ’
Hyperparameters:#
Learning Rate: 0.001 (actor), 0.002 (critic) - typically different rates for actor and critic
Batch Size: 64-256 (size of minibatch sampled from replay buffer)
Replay Buffer Size: 1e6 (maximum number of transitions stored)
Tau: 0.005 (soft update parameter for target networks)
Gamma: 0.99 (discount factor for future rewards)
Noise: Ornstein-Uhlenbeck or Gaussian noise for exploration
DDPG is particularly effective for continuous control tasks like robotic manipulation and locomotion due to its ability to learn deterministic policies in high-dimensional action spaces. While it can be sensitive to hyperparameters and may suffer from overestimation bias, it remains a foundational algorithm for continuous control.
print("Training DDPG...")
# Create monitored environment
env_ddpg = Monitor(gym.make(env_name), LOG_DIR + "ddpg/")
# Action noise for exploration
n_actions = env.action_space.shape[-1]
action_noise = NormalActionNoise(mean=np.zeros(n_actions), sigma=0.1 * np.ones(n_actions))
# Initialize DDPG model
model_ddpg = DDPG(
"MlpPolicy",
env_ddpg,
action_noise=action_noise,
verbose=1,
tensorboard_log=LOG_DIR + "ddpg_tensorboard/",
learning_rate=0.001,
buffer_size=2000,
learning_starts=100,
batch_size=100,
tau=0.005,
gamma=0.98,
train_freq=1,
gradient_steps=1,
device="auto"
)
# Train DDPG
callback_ddpg = TrainingCallback()
model_ddpg.learn(total_timesteps=TOTAL_TIMESTEPS, callback=callback_ddpg)
model_ddpg.save("ddpg_hopper")
Training DDPG...
Using cpu device
Wrapping the env in a DummyVecEnv.
Logging to ./logs/ddpg_tensorboard/DDPG_1
---------------------------------
| rollout/ | |
| ep_len_mean | 26.2 |
| ep_rew_mean | 22.1 |
| time/ | |
| episodes | 4 |
| fps | 481 |
| time_elapsed | 0 |
| total_timesteps | 105 |
| train/ | |
| actor_loss | -1.09 |
| critic_loss | 0.248 |
| learning_rate | 0.001 |
| n_updates | 4 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 16.2 |
| ep_rew_mean | 11.6 |
| time/ | |
| episodes | 8 |
| fps | 183 |
| time_elapsed | 0 |
| total_timesteps | 130 |
| train/ | |
| actor_loss | -0.757 |
| critic_loss | 0.0696 |
| learning_rate | 0.001 |
| n_updates | 29 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 12.8 |
| ep_rew_mean | 8.04 |
| time/ | |
| episodes | 12 |
| fps | 133 |
| time_elapsed | 1 |
| total_timesteps | 154 |
| train/ | |
| actor_loss | -0.674 |
| critic_loss | 0.032 |
| learning_rate | 0.001 |
| n_updates | 53 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 11.1 |
| ep_rew_mean | 6.3 |
| time/ | |
| episodes | 16 |
| fps | 113 |
| time_elapsed | 1 |
| total_timesteps | 178 |
| train/ | |
| actor_loss | -0.746 |
| critic_loss | 0.0242 |
| learning_rate | 0.001 |
| n_updates | 77 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 10.1 |
| ep_rew_mean | 5.28 |
| time/ | |
| episodes | 20 |
| fps | 100 |
| time_elapsed | 2 |
| total_timesteps | 202 |
| train/ | |
| actor_loss | -0.966 |
| critic_loss | 0.0178 |
| learning_rate | 0.001 |
| n_updates | 101 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 9.42 |
| ep_rew_mean | 4.78 |
| time/ | |
| episodes | 24 |
| fps | 91 |
| time_elapsed | 2 |
| total_timesteps | 226 |
| train/ | |
| actor_loss | -0.865 |
| critic_loss | 0.127 |
| learning_rate | 0.001 |
| n_updates | 125 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 9 |
| ep_rew_mean | 4.64 |
| time/ | |
| episodes | 28 |
| fps | 83 |
| time_elapsed | 3 |
| total_timesteps | 252 |
| train/ | |
| actor_loss | -1.27 |
| critic_loss | 0.102 |
| learning_rate | 0.001 |
| n_updates | 151 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.75 |
| ep_rew_mean | 4.69 |
| time/ | |
| episodes | 32 |
| fps | 76 |
| time_elapsed | 3 |
| total_timesteps | 280 |
| train/ | |
| actor_loss | -1.34 |
| critic_loss | 0.06 |
| learning_rate | 0.001 |
| n_updates | 179 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.56 |
| ep_rew_mean | 4.71 |
| time/ | |
| episodes | 36 |
| fps | 69 |
| time_elapsed | 4 |
| total_timesteps | 308 |
| train/ | |
| actor_loss | -1.43 |
| critic_loss | 0.164 |
| learning_rate | 0.001 |
| n_updates | 207 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.4 |
| ep_rew_mean | 4.74 |
| time/ | |
| episodes | 40 |
| fps | 63 |
| time_elapsed | 5 |
| total_timesteps | 336 |
| train/ | |
| actor_loss | -1.58 |
| critic_loss | 0.0511 |
| learning_rate | 0.001 |
| n_updates | 235 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.27 |
| ep_rew_mean | 4.76 |
| time/ | |
| episodes | 44 |
| fps | 60 |
| time_elapsed | 6 |
| total_timesteps | 364 |
| train/ | |
| actor_loss | -1.63 |
| critic_loss | 0.0459 |
| learning_rate | 0.001 |
| n_updates | 263 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.17 |
| ep_rew_mean | 4.77 |
| time/ | |
| episodes | 48 |
| fps | 58 |
| time_elapsed | 6 |
| total_timesteps | 392 |
| train/ | |
| actor_loss | -1.48 |
| critic_loss | 0.0582 |
| learning_rate | 0.001 |
| n_updates | 291 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.08 |
| ep_rew_mean | 4.79 |
| time/ | |
| episodes | 52 |
| fps | 58 |
| time_elapsed | 7 |
| total_timesteps | 420 |
| train/ | |
| actor_loss | -1.74 |
| critic_loss | 0.0381 |
| learning_rate | 0.001 |
| n_updates | 319 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8 |
| ep_rew_mean | 4.8 |
| time/ | |
| episodes | 56 |
| fps | 57 |
| time_elapsed | 7 |
| total_timesteps | 448 |
| train/ | |
| actor_loss | -1.86 |
| critic_loss | 0.0726 |
| learning_rate | 0.001 |
| n_updates | 347 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.93 |
| ep_rew_mean | 4.81 |
| time/ | |
| episodes | 60 |
| fps | 57 |
| time_elapsed | 8 |
| total_timesteps | 476 |
| train/ | |
| actor_loss | -1.97 |
| critic_loss | 0.00849 |
| learning_rate | 0.001 |
| n_updates | 375 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.88 |
| ep_rew_mean | 4.82 |
| time/ | |
| episodes | 64 |
| fps | 57 |
| time_elapsed | 8 |
| total_timesteps | 504 |
| train/ | |
| actor_loss | -2.01 |
| critic_loss | 0.0112 |
| learning_rate | 0.001 |
| n_updates | 403 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.82 |
| ep_rew_mean | 4.83 |
| time/ | |
| episodes | 68 |
| fps | 57 |
| time_elapsed | 9 |
| total_timesteps | 532 |
| train/ | |
| actor_loss | -2.2 |
| critic_loss | 0.0483 |
| learning_rate | 0.001 |
| n_updates | 431 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.78 |
| ep_rew_mean | 4.83 |
| time/ | |
| episodes | 72 |
| fps | 57 |
| time_elapsed | 9 |
| total_timesteps | 560 |
| train/ | |
| actor_loss | -1.87 |
| critic_loss | 0.00432 |
| learning_rate | 0.001 |
| n_updates | 459 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.74 |
| ep_rew_mean | 4.84 |
| time/ | |
| episodes | 76 |
| fps | 56 |
| time_elapsed | 10 |
| total_timesteps | 588 |
| train/ | |
| actor_loss | -1.94 |
| critic_loss | 0.00992 |
| learning_rate | 0.001 |
| n_updates | 487 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.7 |
| ep_rew_mean | 4.84 |
| time/ | |
| episodes | 80 |
| fps | 56 |
| time_elapsed | 10 |
| total_timesteps | 616 |
| train/ | |
| actor_loss | -2.18 |
| critic_loss | 0.00453 |
| learning_rate | 0.001 |
| n_updates | 515 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.67 |
| ep_rew_mean | 4.85 |
| time/ | |
| episodes | 84 |
| fps | 56 |
| time_elapsed | 11 |
| total_timesteps | 644 |
| train/ | |
| actor_loss | -2.11 |
| critic_loss | 0.00335 |
| learning_rate | 0.001 |
| n_updates | 543 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.64 |
| ep_rew_mean | 4.85 |
| time/ | |
| episodes | 88 |
| fps | 56 |
| time_elapsed | 11 |
| total_timesteps | 672 |
| train/ | |
| actor_loss | -1.92 |
| critic_loss | 0.00476 |
| learning_rate | 0.001 |
| n_updates | 571 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.61 |
| ep_rew_mean | 4.86 |
| time/ | |
| episodes | 92 |
| fps | 56 |
| time_elapsed | 12 |
| total_timesteps | 700 |
| train/ | |
| actor_loss | -2.38 |
| critic_loss | 0.0113 |
| learning_rate | 0.001 |
| n_updates | 599 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.58 |
| ep_rew_mean | 4.86 |
| time/ | |
| episodes | 96 |
| fps | 56 |
| time_elapsed | 12 |
| total_timesteps | 728 |
| train/ | |
| actor_loss | -2.11 |
| critic_loss | 0.00631 |
| learning_rate | 0.001 |
| n_updates | 627 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.56 |
| ep_rew_mean | 4.86 |
| time/ | |
| episodes | 100 |
| fps | 55 |
| time_elapsed | 13 |
| total_timesteps | 756 |
| train/ | |
| actor_loss | -2.49 |
| critic_loss | 0.0149 |
| learning_rate | 0.001 |
| n_updates | 655 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 6.79 |
| ep_rew_mean | 4.17 |
| time/ | |
| episodes | 104 |
| fps | 55 |
| time_elapsed | 14 |
| total_timesteps | 784 |
| train/ | |
| actor_loss | -2.56 |
| critic_loss | 0.0221 |
| learning_rate | 0.001 |
| n_updates | 683 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 6.82 |
| ep_rew_mean | 4.33 |
| time/ | |
| episodes | 108 |
| fps | 55 |
| time_elapsed | 14 |
| total_timesteps | 812 |
| train/ | |
| actor_loss | -2.34 |
| critic_loss | 0.00384 |
| learning_rate | 0.001 |
| n_updates | 711 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 6.86 |
| ep_rew_mean | 4.49 |
| time/ | |
| episodes | 112 |
| fps | 54 |
| time_elapsed | 15 |
| total_timesteps | 840 |
| train/ | |
| actor_loss | -2.09 |
| critic_loss | 0.00363 |
| learning_rate | 0.001 |
| n_updates | 739 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 6.9 |
| ep_rew_mean | 4.64 |
| time/ | |
| episodes | 116 |
| fps | 54 |
| time_elapsed | 15 |
| total_timesteps | 868 |
| train/ | |
| actor_loss | -2.43 |
| critic_loss | 0.00258 |
| learning_rate | 0.001 |
| n_updates | 767 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 6.94 |
| ep_rew_mean | 4.79 |
| time/ | |
| episodes | 120 |
| fps | 53 |
| time_elapsed | 16 |
| total_timesteps | 896 |
| train/ | |
| actor_loss | -2.1 |
| critic_loss | 0.00301 |
| learning_rate | 0.001 |
| n_updates | 795 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 6.98 |
| ep_rew_mean | 4.9 |
| time/ | |
| episodes | 124 |
| fps | 52 |
| time_elapsed | 17 |
| total_timesteps | 924 |
| train/ | |
| actor_loss | -2.29 |
| critic_loss | 0.00289 |
| learning_rate | 0.001 |
| n_updates | 823 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7 |
| ep_rew_mean | 4.94 |
| time/ | |
| episodes | 128 |
| fps | 51 |
| time_elapsed | 18 |
| total_timesteps | 952 |
| train/ | |
| actor_loss | -2.36 |
| critic_loss | 0.00218 |
| learning_rate | 0.001 |
| n_updates | 851 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7 |
| ep_rew_mean | 4.94 |
| time/ | |
| episodes | 132 |
| fps | 50 |
| time_elapsed | 19 |
| total_timesteps | 980 |
| train/ | |
| actor_loss | -2.31 |
| critic_loss | 0.0252 |
| learning_rate | 0.001 |
| n_updates | 879 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.22 |
| ep_rew_mean | 5.27 |
| time/ | |
| episodes | 136 |
| fps | 50 |
| time_elapsed | 20 |
| total_timesteps | 1030 |
| train/ | |
| actor_loss | -3.48 |
| critic_loss | 0.0191 |
| learning_rate | 0.001 |
| n_updates | 929 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.34 |
| ep_rew_mean | 5.25 |
| time/ | |
| episodes | 140 |
| fps | 50 |
| time_elapsed | 21 |
| total_timesteps | 1070 |
| train/ | |
| actor_loss | -3.75 |
| critic_loss | 0.366 |
| learning_rate | 0.001 |
| n_updates | 969 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.46 |
| ep_rew_mean | 5.23 |
| time/ | |
| episodes | 144 |
| fps | 50 |
| time_elapsed | 22 |
| total_timesteps | 1110 |
| train/ | |
| actor_loss | -3.53 |
| critic_loss | 0.0252 |
| learning_rate | 0.001 |
| n_updates | 1009 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.58 |
| ep_rew_mean | 5.22 |
| time/ | |
| episodes | 148 |
| fps | 49 |
| time_elapsed | 23 |
| total_timesteps | 1150 |
| train/ | |
| actor_loss | -4.85 |
| critic_loss | 0.0367 |
| learning_rate | 0.001 |
| n_updates | 1049 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.7 |
| ep_rew_mean | 5.2 |
| time/ | |
| episodes | 152 |
| fps | 49 |
| time_elapsed | 23 |
| total_timesteps | 1190 |
| train/ | |
| actor_loss | -4.36 |
| critic_loss | 0.0359 |
| learning_rate | 0.001 |
| n_updates | 1089 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.82 |
| ep_rew_mean | 5.19 |
| time/ | |
| episodes | 156 |
| fps | 49 |
| time_elapsed | 24 |
| total_timesteps | 1230 |
| train/ | |
| actor_loss | -4.35 |
| critic_loss | 0.0217 |
| learning_rate | 0.001 |
| n_updates | 1129 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 7.94 |
| ep_rew_mean | 5.17 |
| time/ | |
| episodes | 160 |
| fps | 49 |
| time_elapsed | 25 |
| total_timesteps | 1270 |
| train/ | |
| actor_loss | -4.45 |
| critic_loss | 0.0309 |
| learning_rate | 0.001 |
| n_updates | 1169 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.06 |
| ep_rew_mean | 5.16 |
| time/ | |
| episodes | 164 |
| fps | 49 |
| time_elapsed | 26 |
| total_timesteps | 1310 |
| train/ | |
| actor_loss | -5.08 |
| critic_loss | 0.0266 |
| learning_rate | 0.001 |
| n_updates | 1209 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.18 |
| ep_rew_mean | 5.15 |
| time/ | |
| episodes | 168 |
| fps | 49 |
| time_elapsed | 27 |
| total_timesteps | 1350 |
| train/ | |
| actor_loss | -4.98 |
| critic_loss | 0.0112 |
| learning_rate | 0.001 |
| n_updates | 1249 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.3 |
| ep_rew_mean | 5.14 |
| time/ | |
| episodes | 172 |
| fps | 49 |
| time_elapsed | 28 |
| total_timesteps | 1390 |
| train/ | |
| actor_loss | -5.36 |
| critic_loss | 0.0287 |
| learning_rate | 0.001 |
| n_updates | 1289 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.42 |
| ep_rew_mean | 5.13 |
| time/ | |
| episodes | 176 |
| fps | 49 |
| time_elapsed | 29 |
| total_timesteps | 1430 |
| train/ | |
| actor_loss | -4.99 |
| critic_loss | 0.0518 |
| learning_rate | 0.001 |
| n_updates | 1329 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.54 |
| ep_rew_mean | 5.12 |
| time/ | |
| episodes | 180 |
| fps | 48 |
| time_elapsed | 30 |
| total_timesteps | 1470 |
| train/ | |
| actor_loss | -4.87 |
| critic_loss | 0.0332 |
| learning_rate | 0.001 |
| n_updates | 1369 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.66 |
| ep_rew_mean | 5.11 |
| time/ | |
| episodes | 184 |
| fps | 48 |
| time_elapsed | 31 |
| total_timesteps | 1510 |
| train/ | |
| actor_loss | -5.57 |
| critic_loss | 0.0183 |
| learning_rate | 0.001 |
| n_updates | 1409 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.78 |
| ep_rew_mean | 5.1 |
| time/ | |
| episodes | 188 |
| fps | 47 |
| time_elapsed | 32 |
| total_timesteps | 1550 |
| train/ | |
| actor_loss | -5.22 |
| critic_loss | 0.00843 |
| learning_rate | 0.001 |
| n_updates | 1449 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 8.9 |
| ep_rew_mean | 5.07 |
| time/ | |
| episodes | 192 |
| fps | 47 |
| time_elapsed | 33 |
| total_timesteps | 1590 |
| train/ | |
| actor_loss | -4.75 |
| critic_loss | 0.0212 |
| learning_rate | 0.001 |
| n_updates | 1489 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 9.02 |
| ep_rew_mean | 5.06 |
| time/ | |
| episodes | 196 |
| fps | 47 |
| time_elapsed | 34 |
| total_timesteps | 1630 |
| train/ | |
| actor_loss | -5.51 |
| critic_loss | 0.0212 |
| learning_rate | 0.001 |
| n_updates | 1529 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 9.14 |
| ep_rew_mean | 5.05 |
| time/ | |
| episodes | 200 |
| fps | 47 |
| time_elapsed | 35 |
| total_timesteps | 1670 |
| train/ | |
| actor_loss | -5.22 |
| critic_loss | 0.033 |
| learning_rate | 0.001 |
| n_updates | 1569 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 9.26 |
| ep_rew_mean | 5.04 |
| time/ | |
| episodes | 204 |
| fps | 47 |
| time_elapsed | 35 |
| total_timesteps | 1710 |
| train/ | |
| actor_loss | -4.84 |
| critic_loss | 0.00927 |
| learning_rate | 0.001 |
| n_updates | 1609 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 9.38 |
| ep_rew_mean | 5.03 |
| time/ | |
| episodes | 208 |
| fps | 47 |
| time_elapsed | 37 |
| total_timesteps | 1750 |
| train/ | |
| actor_loss | -4.8 |
| critic_loss | 0.0179 |
| learning_rate | 0.001 |
| n_updates | 1649 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 9.5 |
| ep_rew_mean | 5.01 |
| time/ | |
| episodes | 212 |
| fps | 46 |
| time_elapsed | 38 |
| total_timesteps | 1790 |
| train/ | |
| actor_loss | -4.99 |
| critic_loss | 0.0114 |
| learning_rate | 0.001 |
| n_updates | 1689 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 9.62 |
| ep_rew_mean | 5.01 |
| time/ | |
| episodes | 216 |
| fps | 46 |
| time_elapsed | 39 |
| total_timesteps | 1830 |
| train/ | |
| actor_loss | -4.2 |
| critic_loss | 0.00429 |
| learning_rate | 0.001 |
| n_updates | 1729 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 9.74 |
| ep_rew_mean | 4.99 |
| time/ | |
| episodes | 220 |
| fps | 46 |
| time_elapsed | 40 |
| total_timesteps | 1870 |
| train/ | |
| actor_loss | -4.49 |
| critic_loss | 0.00654 |
| learning_rate | 0.001 |
| n_updates | 1769 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 9.86 |
| ep_rew_mean | 4.98 |
| time/ | |
| episodes | 224 |
| fps | 46 |
| time_elapsed | 41 |
| total_timesteps | 1910 |
| train/ | |
| actor_loss | -4.78 |
| critic_loss | 0.00467 |
| learning_rate | 0.001 |
| n_updates | 1809 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 9.98 |
| ep_rew_mean | 4.96 |
| time/ | |
| episodes | 228 |
| fps | 46 |
| time_elapsed | 42 |
| total_timesteps | 1950 |
| train/ | |
| actor_loss | -4.68 |
| critic_loss | 0.011 |
| learning_rate | 0.001 |
| n_updates | 1849 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 10.1 |
| ep_rew_mean | 4.95 |
| time/ | |
| episodes | 232 |
| fps | 46 |
| time_elapsed | 43 |
| total_timesteps | 1990 |
| train/ | |
| actor_loss | -5.32 |
| critic_loss | 0.0201 |
| learning_rate | 0.001 |
| n_updates | 1889 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 10 |
| ep_rew_mean | 4.62 |
| time/ | |
| episodes | 236 |
| fps | 45 |
| time_elapsed | 44 |
| total_timesteps | 2030 |
| train/ | |
| actor_loss | -4.64 |
| critic_loss | 0.00767 |
| learning_rate | 0.001 |
| n_updates | 1929 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 10 |
| ep_rew_mean | 4.61 |
| time/ | |
| episodes | 240 |
| fps | 45 |
| time_elapsed | 45 |
| total_timesteps | 2070 |
| train/ | |
| actor_loss | -4.35 |
| critic_loss | 0.013 |
| learning_rate | 0.001 |
| n_updates | 1969 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 10 |
| ep_rew_mean | 4.62 |
| time/ | |
| episodes | 244 |
| fps | 45 |
| time_elapsed | 46 |
| total_timesteps | 2110 |
| train/ | |
| actor_loss | -4.45 |
| critic_loss | 0.00757 |
| learning_rate | 0.001 |
| n_updates | 2009 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 10 |
| ep_rew_mean | 4.63 |
| time/ | |
| episodes | 248 |
| fps | 45 |
| time_elapsed | 47 |
| total_timesteps | 2150 |
| train/ | |
| actor_loss | -4.6 |
| critic_loss | 0.00681 |
| learning_rate | 0.001 |
| n_updates | 2049 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 10 |
| ep_rew_mean | 4.63 |
| time/ | |
| episodes | 252 |
| fps | 45 |
| time_elapsed | 48 |
| total_timesteps | 2190 |
| train/ | |
| actor_loss | -4.17 |
| critic_loss | 0.0277 |
| learning_rate | 0.001 |
| n_updates | 2089 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 10 |
| ep_rew_mean | 4.63 |
| time/ | |
| episodes | 256 |
| fps | 45 |
| time_elapsed | 49 |
| total_timesteps | 2230 |
| train/ | |
| actor_loss | -4.22 |
| critic_loss | 0.0151 |
| learning_rate | 0.001 |
| n_updates | 2129 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 10 |
| ep_rew_mean | 4.63 |
| time/ | |
| episodes | 260 |
| fps | 45 |
| time_elapsed | 49 |
| total_timesteps | 2270 |
| train/ | |
| actor_loss | -3.52 |
| critic_loss | 0.018 |
| learning_rate | 0.001 |
| n_updates | 2169 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 10.1 |
| ep_rew_mean | 4.93 |
| time/ | |
| episodes | 264 |
| fps | 45 |
| time_elapsed | 51 |
| total_timesteps | 2320 |
| train/ | |
| actor_loss | -5.25 |
| critic_loss | 0.0165 |
| learning_rate | 0.001 |
| n_updates | 2219 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 11.2 |
| ep_rew_mean | 7.2 |
| time/ | |
| episodes | 268 |
| fps | 44 |
| time_elapsed | 54 |
| total_timesteps | 2465 |
| train/ | |
| actor_loss | -6.53 |
| critic_loss | 0.142 |
| learning_rate | 0.001 |
| n_updates | 2364 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 13.9 |
| ep_rew_mean | 13.1 |
| time/ | |
| episodes | 272 |
| fps | 44 |
| time_elapsed | 63 |
| total_timesteps | 2782 |
| train/ | |
| actor_loss | -8.84 |
| critic_loss | 1.05 |
| learning_rate | 0.001 |
| n_updates | 2681 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 16.8 |
| ep_rew_mean | 19.4 |
| time/ | |
| episodes | 276 |
| fps | 43 |
| time_elapsed | 71 |
| total_timesteps | 3113 |
| train/ | |
| actor_loss | -10.8 |
| critic_loss | 1.78 |
| learning_rate | 0.001 |
| n_updates | 3012 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 19.9 |
| ep_rew_mean | 26.1 |
| time/ | |
| episodes | 280 |
| fps | 43 |
| time_elapsed | 78 |
| total_timesteps | 3457 |
| train/ | |
| actor_loss | -14.5 |
| critic_loss | 0.748 |
| learning_rate | 0.001 |
| n_updates | 3356 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 22.9 |
| ep_rew_mean | 32.7 |
| time/ | |
| episodes | 284 |
| fps | 43 |
| time_elapsed | 87 |
| total_timesteps | 3802 |
| train/ | |
| actor_loss | -19.9 |
| critic_loss | 0.525 |
| learning_rate | 0.001 |
| n_updates | 3701 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 26 |
| ep_rew_mean | 39.4 |
| time/ | |
| episodes | 288 |
| fps | 43 |
| time_elapsed | 95 |
| total_timesteps | 4148 |
| train/ | |
| actor_loss | -24.8 |
| critic_loss | 0.302 |
| learning_rate | 0.001 |
| n_updates | 4047 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 29 |
| ep_rew_mean | 46.1 |
| time/ | |
| episodes | 292 |
| fps | 43 |
| time_elapsed | 103 |
| total_timesteps | 4493 |
| train/ | |
| actor_loss | -26.3 |
| critic_loss | 4.33 |
| learning_rate | 0.001 |
| n_updates | 4392 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 29.3 |
| ep_rew_mean | 46.4 |
| time/ | |
| episodes | 296 |
| fps | 43 |
| time_elapsed | 105 |
| total_timesteps | 4562 |
| train/ | |
| actor_loss | -26.9 |
| critic_loss | 9.07 |
| learning_rate | 0.001 |
| n_updates | 4461 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 29.3 |
| ep_rew_mean | 46.3 |
| time/ | |
| episodes | 300 |
| fps | 43 |
| time_elapsed | 105 |
| total_timesteps | 4597 |
| train/ | |
| actor_loss | -28.5 |
| critic_loss | 10.6 |
| learning_rate | 0.001 |
| n_updates | 4496 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 29.1 |
| ep_rew_mean | 46.3 |
| time/ | |
| episodes | 304 |
| fps | 43 |
| time_elapsed | 106 |
| total_timesteps | 4624 |
| train/ | |
| actor_loss | -28.5 |
| critic_loss | 2.65 |
| learning_rate | 0.001 |
| n_updates | 4523 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 29 |
| ep_rew_mean | 46.2 |
| time/ | |
| episodes | 308 |
| fps | 43 |
| time_elapsed | 107 |
| total_timesteps | 4652 |
| train/ | |
| actor_loss | -28.5 |
| critic_loss | 2.16 |
| learning_rate | 0.001 |
| n_updates | 4551 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 28.9 |
| ep_rew_mean | 46.1 |
| time/ | |
| episodes | 312 |
| fps | 43 |
| time_elapsed | 107 |
| total_timesteps | 4680 |
| train/ | |
| actor_loss | -27.7 |
| critic_loss | 2.35 |
| learning_rate | 0.001 |
| n_updates | 4579 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 28.8 |
| ep_rew_mean | 46 |
| time/ | |
| episodes | 316 |
| fps | 43 |
| time_elapsed | 108 |
| total_timesteps | 4708 |
| train/ | |
| actor_loss | -30.1 |
| critic_loss | 2.65 |
| learning_rate | 0.001 |
| n_updates | 4607 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 28.7 |
| ep_rew_mean | 46 |
| time/ | |
| episodes | 320 |
| fps | 43 |
| time_elapsed | 109 |
| total_timesteps | 4737 |
| train/ | |
| actor_loss | -28.2 |
| critic_loss | 8.7 |
| learning_rate | 0.001 |
| n_updates | 4636 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 28.6 |
| ep_rew_mean | 45.9 |
| time/ | |
| episodes | 324 |
| fps | 43 |
| time_elapsed | 110 |
| total_timesteps | 4770 |
| train/ | |
| actor_loss | -29.2 |
| critic_loss | 0.835 |
| learning_rate | 0.001 |
| n_updates | 4669 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 28.6 |
| ep_rew_mean | 45.8 |
| time/ | |
| episodes | 328 |
| fps | 43 |
| time_elapsed | 111 |
| total_timesteps | 4812 |
| train/ | |
| actor_loss | -31.1 |
| critic_loss | 3.59 |
| learning_rate | 0.001 |
| n_updates | 4711 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 28.9 |
| ep_rew_mean | 45.6 |
| time/ | |
| episodes | 332 |
| fps | 43 |
| time_elapsed | 112 |
| total_timesteps | 4885 |
| train/ | |
| actor_loss | -31.2 |
| critic_loss | 0.603 |
| learning_rate | 0.001 |
| n_updates | 4784 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 29.4 |
| ep_rew_mean | 45.3 |
| time/ | |
| episodes | 336 |
| fps | 43 |
| time_elapsed | 114 |
| total_timesteps | 4966 |
| train/ | |
| actor_loss | -31 |
| critic_loss | 1.52 |
| learning_rate | 0.001 |
| n_updates | 4865 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 29.8 |
| ep_rew_mean | 45.2 |
| time/ | |
| episodes | 340 |
| fps | 43 |
| time_elapsed | 116 |
| total_timesteps | 5053 |
| train/ | |
| actor_loss | -31.1 |
| critic_loss | 0.801 |
| learning_rate | 0.001 |
| n_updates | 4952 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 30.6 |
| ep_rew_mean | 45.7 |
| time/ | |
| episodes | 344 |
| fps | 43 |
| time_elapsed | 119 |
| total_timesteps | 5166 |
| train/ | |
| actor_loss | -30.8 |
| critic_loss | 1.46 |
| learning_rate | 0.001 |
| n_updates | 5065 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 33.1 |
| ep_rew_mean | 51.1 |
| time/ | |
| episodes | 348 |
| fps | 43 |
| time_elapsed | 126 |
| total_timesteps | 5458 |
| train/ | |
| actor_loss | -29.4 |
| critic_loss | 3.2 |
| learning_rate | 0.001 |
| n_updates | 5357 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 33.9 |
| ep_rew_mean | 53.1 |
| time/ | |
| episodes | 352 |
| fps | 43 |
| time_elapsed | 129 |
| total_timesteps | 5579 |
| train/ | |
| actor_loss | -32 |
| critic_loss | 1.33 |
| learning_rate | 0.001 |
| n_updates | 5478 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 36.9 |
| ep_rew_mean | 59.8 |
| time/ | |
| episodes | 356 |
| fps | 43 |
| time_elapsed | 137 |
| total_timesteps | 5920 |
| train/ | |
| actor_loss | -32.4 |
| critic_loss | 1.36 |
| learning_rate | 0.001 |
| n_updates | 5819 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 39.9 |
| ep_rew_mean | 66.5 |
| time/ | |
| episodes | 360 |
| fps | 43 |
| time_elapsed | 145 |
| total_timesteps | 6263 |
| train/ | |
| actor_loss | -36.8 |
| critic_loss | 1.18 |
| learning_rate | 0.001 |
| n_updates | 6162 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 42.9 |
| ep_rew_mean | 73 |
| time/ | |
| episodes | 364 |
| fps | 43 |
| time_elapsed | 153 |
| total_timesteps | 6605 |
| train/ | |
| actor_loss | -35.4 |
| critic_loss | 1.02 |
| learning_rate | 0.001 |
| n_updates | 6504 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 44.8 |
| ep_rew_mean | 77.5 |
| time/ | |
| episodes | 368 |
| fps | 42 |
| time_elapsed | 161 |
| total_timesteps | 6947 |
| train/ | |
| actor_loss | -43.1 |
| critic_loss | 0.898 |
| learning_rate | 0.001 |
| n_updates | 6846 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 45 |
| ep_rew_mean | 78.3 |
| time/ | |
| episodes | 372 |
| fps | 43 |
| time_elapsed | 169 |
| total_timesteps | 7286 |
| train/ | |
| actor_loss | -46.2 |
| critic_loss | 1.25 |
| learning_rate | 0.001 |
| n_updates | 7185 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 45.1 |
| ep_rew_mean | 78.5 |
| time/ | |
| episodes | 376 |
| fps | 42 |
| time_elapsed | 177 |
| total_timesteps | 7622 |
| train/ | |
| actor_loss | -50.1 |
| critic_loss | 0.702 |
| learning_rate | 0.001 |
| n_updates | 7521 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 44.9 |
| ep_rew_mean | 78.1 |
| time/ | |
| episodes | 380 |
| fps | 43 |
| time_elapsed | 184 |
| total_timesteps | 7949 |
| train/ | |
| actor_loss | -50.2 |
| critic_loss | 8.99 |
| learning_rate | 0.001 |
| n_updates | 7848 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 44.1 |
| ep_rew_mean | 76.1 |
| time/ | |
| episodes | 384 |
| fps | 42 |
| time_elapsed | 190 |
| total_timesteps | 8209 |
| train/ | |
| actor_loss | -59.2 |
| critic_loss | 43.4 |
| learning_rate | 0.001 |
| n_updates | 8108 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 42.6 |
| ep_rew_mean | 72.4 |
| time/ | |
| episodes | 388 |
| fps | 43 |
| time_elapsed | 195 |
| total_timesteps | 8405 |
| train/ | |
| actor_loss | -62.5 |
| critic_loss | 39.9 |
| learning_rate | 0.001 |
| n_updates | 8304 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 42 |
| ep_rew_mean | 71.3 |
| time/ | |
| episodes | 392 |
| fps | 42 |
| time_elapsed | 202 |
| total_timesteps | 8688 |
| train/ | |
| actor_loss | -64.1 |
| critic_loss | 28.3 |
| learning_rate | 0.001 |
| n_updates | 8587 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 43.5 |
| ep_rew_mean | 74.7 |
| time/ | |
| episodes | 396 |
| fps | 43 |
| time_elapsed | 207 |
| total_timesteps | 8907 |
| train/ | |
| actor_loss | -65.1 |
| critic_loss | 65.8 |
| learning_rate | 0.001 |
| n_updates | 8806 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 46.2 |
| ep_rew_mean | 81.4 |
| time/ | |
| episodes | 400 |
| fps | 42 |
| time_elapsed | 214 |
| total_timesteps | 9216 |
| train/ | |
| actor_loss | -74.1 |
| critic_loss | 43.9 |
| learning_rate | 0.001 |
| n_updates | 9115 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 48.3 |
| ep_rew_mean | 85.6 |
| time/ | |
| episodes | 404 |
| fps | 42 |
| time_elapsed | 219 |
| total_timesteps | 9451 |
| train/ | |
| actor_loss | -76.7 |
| critic_loss | 22.7 |
| learning_rate | 0.001 |
| n_updates | 9350 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 49.7 |
| ep_rew_mean | 88.4 |
| time/ | |
| episodes | 408 |
| fps | 43 |
| time_elapsed | 223 |
| total_timesteps | 9619 |
| train/ | |
| actor_loss | -69.8 |
| critic_loss | 14.8 |
| learning_rate | 0.001 |
| n_updates | 9518 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 51 |
| ep_rew_mean | 91.2 |
| time/ | |
| episodes | 412 |
| fps | 42 |
| time_elapsed | 228 |
| total_timesteps | 9785 |
| train/ | |
| actor_loss | -76.3 |
| critic_loss | 12.3 |
| learning_rate | 0.001 |
| n_updates | 9684 |
---------------------------------
print("\n🤖 DDPG Performance:")
video_path_ddpg = os.path.join(VIDEO_DIR, "ddpg_hopper.mp4")
reward_ddpg = record_video(model_ddpg, env_name, video_path_ddpg)
display(display_video_html(video_path_ddpg, "DDPG Agent Playing Hopper-v5"))
print(f"Final episode reward: {reward_ddpg:.2f}")
🤖 DDPG Performance:
Episode 1 reward: 185.40
Video saved as ./videos/ddpg_hopper.mp4
DDPG Agent Playing Hopper-v5
Final episode reward: 185.40
3️⃣ PPO (Proximal Policy Optimization)#
PPO is an on-policy reinforcement learning algorithm that strikes a balance between sample efficiency and ease of implementation. It’s designed to address the instability issues of policy gradient methods by constraining policy updates to prevent destructively large changes while maintaining good performance across a wide range of tasks.
Key Features:#
Clipped Surrogate Objective: Prevents policy updates from being too large by clipping the probability ratio
On-Policy with Multiple Epochs: Reuses collected data for multiple gradient steps while staying approximately on-policy
Adaptive KL Penalty: Optional mechanism to adaptively control the magnitude of policy updates
Robust Performance: Reliable across diverse environments with minimal hyperparameter tuning
Algorithm Components:#
Actor Network: Outputs action probabilities π(a|s) for stochastic policy
Critic Network: Estimates state values V(s) for advantage calculation
Clipped Objective: L^CLIP(θ) = E[min(r_t(θ)A_t, clip(r_t(θ), 1-ε, 1+ε)A_t)]
Probability Ratio: r_t(θ) = π_θ(a_t|s_t) / π_θ_old(a_t|s_t)
Learning Process:#
Data Collection: Collect trajectories using current policy for n_steps
Advantage Estimation: Compute advantages using GAE: A_t = Σ(γλ)^l δ_{t+l}
Policy Update: Optimize clipped objective for multiple epochs on collected data
Value Function Update: Minimize squared error between V(s) and returns
Hyperparameters:#
Learning Rate: 0.0003 (often uses learning rate scheduling)
n_steps: 2048 (number of steps collected before each update)
Batch Size: 64 (minibatch size for SGD updates)
n_epochs: 10 (number of optimization epochs per data collection)
Clip Range: 0.2 (ε parameter for clipping the probability ratio)
Gamma: 0.99 (discount factor for future rewards)
GAE Lambda: 0.95 (parameter for Generalized Advantage Estimation)
PPO is considered the gold standard for many reinforcement learning applications due to its reliability and consistent performance. It’s particularly effective for both discrete and continuous control tasks, making it a popular choice for robotics, game playing, and other complex decision-making problems.
print("Training PPO...")
# Create monitored environment
env_ppo = Monitor(gym.make(env_name), LOG_DIR + "ppo/")
env_ppo = DummyVecEnv([lambda: env_ppo])
# Initialize PPO model
model_ppo = PPO(
"MlpPolicy",
env_ppo,
verbose=1,
tensorboard_log=LOG_DIR + "ppo_tensorboard/",
learning_rate=0.0003,
n_steps=2048,
batch_size=64,
n_epochs=10,
gamma=0.99,
gae_lambda=0.95,
clip_range=0.2,
clip_range_vf=None,
ent_coef=0.0,
vf_coef=0.5,
max_grad_norm=0.5,
use_sde=False,
sde_sample_freq=-1,
device="auto"
)
# Train PPO
callback_ppo = TrainingCallback()
model_ppo.learn(total_timesteps=TOTAL_TIMESTEPS, callback=callback_ppo)
model_ppo.save("ppo_hopper")
print("PPO training completed! ✅")
Training PPO...
Using cpu device
Logging to ./logs/ppo_tensorboard/PPO_1
---------------------------------
| rollout/ | |
| ep_len_mean | 20.8 |
| ep_rew_mean | 16.5 |
| time/ | |
| fps | 815 |
| iterations | 1 |
| time_elapsed | 2 |
| total_timesteps | 2048 |
---------------------------------
----------------------------------------
| rollout/ | |
| ep_len_mean | 25.8 |
| ep_rew_mean | 23.4 |
| time/ | |
| fps | 556 |
| iterations | 2 |
| time_elapsed | 7 |
| total_timesteps | 4096 |
| train/ | |
| approx_kl | 0.02066369 |
| clip_fraction | 0.23 |
| clip_range | 0.2 |
| entropy_loss | -4.22 |
| explained_variance | 0.0304 |
| learning_rate | 0.0003 |
| loss | 15.7 |
| n_updates | 10 |
| policy_gradient_loss | -0.0232 |
| std | 0.98 |
| value_loss | 52.7 |
----------------------------------------
-----------------------------------------
| rollout/ | |
| ep_len_mean | 36.1 |
| ep_rew_mean | 44.5 |
| time/ | |
| fps | 506 |
| iterations | 3 |
| time_elapsed | 12 |
| total_timesteps | 6144 |
| train/ | |
| approx_kl | 0.014870105 |
| clip_fraction | 0.176 |
| clip_range | 0.2 |
| entropy_loss | -4.18 |
| explained_variance | 0.283 |
| learning_rate | 0.0003 |
| loss | 46.3 |
| n_updates | 20 |
| policy_gradient_loss | -0.0226 |
| std | 0.97 |
| value_loss | 86.7 |
-----------------------------------------
-----------------------------------------
| rollout/ | |
| ep_len_mean | 47.6 |
| ep_rew_mean | 68.5 |
| time/ | |
| fps | 498 |
| iterations | 4 |
| time_elapsed | 16 |
| total_timesteps | 8192 |
| train/ | |
| approx_kl | 0.011019922 |
| clip_fraction | 0.101 |
| clip_range | 0.2 |
| entropy_loss | -4.16 |
| explained_variance | 0.24 |
| learning_rate | 0.0003 |
| loss | 124 |
| n_updates | 30 |
| policy_gradient_loss | -0.0187 |
| std | 0.966 |
| value_loss | 247 |
-----------------------------------------
print("\n🤖 PPO Performance:")
video_path_ppo = os.path.join(VIDEO_DIR, "ppo_hopper.mp4")
reward_ppo = record_video(model_ppo, env_name, video_path_ppo)
display(display_video_html(video_path_ppo, "PPO Agent Playing Hopper-v5"))
print(f"Final episode reward: {reward_ppo:.2f}")
4️⃣ SAC (Soft Actor-Critic)#
SAC is an off-policy reinforcement learning algorithm that maximizes both expected return and entropy of the policy. It combines the sample efficiency of off-policy methods with the stability of entropy regularization, making it particularly effective for continuous control tasks where exploration is crucial.
Key Features:#
Maximum Entropy Framework: Optimizes a trade-off between reward maximization and policy entropy
Off-Policy Learning: Uses experience replay for sample-efficient learning from past experiences
Stochastic Policy: Learns a stochastic policy that naturally handles exploration
Automatic Temperature Tuning: Adaptively adjusts the entropy regularization coefficient
Algorithm Components:#
Actor Network: Outputs mean and log-std for a stochastic policy π(a|s)
Twin Critic Networks: Two Q-networks (Q₁, Q₂) to mitigate overestimation bias
Target Critics: Soft-updated target networks for stable learning
Temperature Parameter: α controls the entropy-reward trade-off in the objective
Learning Process:#
Entropy-Regularized Objective: J(π) = E[Σ(r_t + α log π(a_t|s_t))]
Critic Update: Minimize TD error using minimum of twin Q-values for target
Actor Update: Maximize entropy-regularized Q-value: E[Q(s,a) - α log π(a|s)]
Temperature Update: Adjust α to maintain target entropy automatically
Hyperparameters:#
Learning Rate: 0.0003 (typically same for actor, critics, and temperature)
Batch Size: 256 (larger batches often beneficial for stability)
Replay Buffer Size: 1e6 (large buffer for diverse experience)
Tau: 0.005 (soft update coefficient for target networks)
Gamma: 0.99 (discount factor for future rewards)
Target Entropy: -dim(action_space) (automatic temperature tuning target)
Update Frequency: 1 (gradient steps per environment step)
SAC is particularly effective for continuous control tasks requiring exploration, such as robotic manipulation and locomotion. Its entropy regularization encourages exploration while the off-policy nature provides sample efficiency. The algorithm is robust to hyperparameters and often achieves state-of-the-art performance on continuous control benchmarks.
print("Training SAC...")
# Create monitored environment
env_sac = Monitor(gym.make(env_name), LOG_DIR + "sac/")
# Initialize SAC model
model_sac = SAC(
"MlpPolicy",
env_sac,
verbose=1,
tensorboard_log=LOG_DIR + "sac_tensorboard/",
learning_rate=0.0003,
buffer_size=300000,
learning_starts=100,
batch_size=256,
tau=0.005,
gamma=0.99,
train_freq=1,
gradient_steps=1,
ent_coef="auto",
target_update_interval=1,
target_entropy="auto",
use_sde=False,
sde_sample_freq=-1,
use_sde_at_warmup=False,
device="auto"
)
# Train SAC
callback_sac = TrainingCallback()
model_sac.learn(total_timesteps=TOTAL_TIMESTEPS, callback=callback_sac)
model_sac.save("sac_hopper")
print("SAC training completed! ✅")
Training SAC...
Using cpu device
Wrapping the env in a DummyVecEnv.
Logging to ./logs/sac_tensorboard/SAC_1
---------------------------------
| rollout/ | |
| ep_len_mean | 26 |
| ep_rew_mean | 16.3 |
| time/ | |
| episodes | 4 |
| fps | 589 |
| time_elapsed | 0 |
| total_timesteps | 104 |
| train/ | |
| actor_loss | -2.23 |
| critic_loss | 6.01 |
| ent_coef | 0.999 |
| ent_coef_loss | -0.00299 |
| learning_rate | 0.0003 |
| n_updates | 3 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 21.1 |
| ep_rew_mean | 14.1 |
| time/ | |
| episodes | 8 |
| fps | 77 |
| time_elapsed | 2 |
| total_timesteps | 169 |
| train/ | |
| actor_loss | -4.92 |
| critic_loss | 0.922 |
| ent_coef | 0.98 |
| ent_coef_loss | -0.102 |
| learning_rate | 0.0003 |
| n_updates | 68 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 26.3 |
| ep_rew_mean | 20.9 |
| time/ | |
| episodes | 12 |
| fps | 46 |
| time_elapsed | 6 |
| total_timesteps | 316 |
| train/ | |
| actor_loss | -6.18 |
| critic_loss | 0.552 |
| ent_coef | 0.938 |
| ent_coef_loss | -0.321 |
| learning_rate | 0.0003 |
| n_updates | 215 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 28.8 |
| ep_rew_mean | 22.3 |
| time/ | |
| episodes | 16 |
| fps | 37 |
| time_elapsed | 12 |
| total_timesteps | 460 |
| train/ | |
| actor_loss | -7.29 |
| critic_loss | 0.687 |
| ent_coef | 0.898 |
| ent_coef_loss | -0.529 |
| learning_rate | 0.0003 |
| n_updates | 359 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 33.1 |
| ep_rew_mean | 25.9 |
| time/ | |
| episodes | 20 |
| fps | 35 |
| time_elapsed | 18 |
| total_timesteps | 662 |
| train/ | |
| actor_loss | -8.93 |
| critic_loss | 0.704 |
| ent_coef | 0.846 |
| ent_coef_loss | -0.82 |
| learning_rate | 0.0003 |
| n_updates | 561 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 37.4 |
| ep_rew_mean | 35.7 |
| time/ | |
| episodes | 24 |
| fps | 33 |
| time_elapsed | 26 |
| total_timesteps | 897 |
| train/ | |
| actor_loss | -11.7 |
| critic_loss | 0.831 |
| ent_coef | 0.79 |
| ent_coef_loss | -1.15 |
| learning_rate | 0.0003 |
| n_updates | 796 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 45.1 |
| ep_rew_mean | 48.7 |
| time/ | |
| episodes | 28 |
| fps | 31 |
| time_elapsed | 39 |
| total_timesteps | 1262 |
| train/ | |
| actor_loss | -15.4 |
| critic_loss | 2.82 |
| ent_coef | 0.71 |
| ent_coef_loss | -1.59 |
| learning_rate | 0.0003 |
| n_updates | 1161 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 49.6 |
| ep_rew_mean | 57.4 |
| time/ | |
| episodes | 32 |
| fps | 30 |
| time_elapsed | 51 |
| total_timesteps | 1587 |
| train/ | |
| actor_loss | -19.1 |
| critic_loss | 2.75 |
| ent_coef | 0.646 |
| ent_coef_loss | -1.99 |
| learning_rate | 0.0003 |
| n_updates | 1486 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 52.9 |
| ep_rew_mean | 66.7 |
| time/ | |
| episodes | 36 |
| fps | 30 |
| time_elapsed | 62 |
| total_timesteps | 1906 |
| train/ | |
| actor_loss | -23.1 |
| critic_loss | 4.85 |
| ent_coef | 0.59 |
| ent_coef_loss | -2.36 |
| learning_rate | 0.0003 |
| n_updates | 1805 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 55.6 |
| ep_rew_mean | 74.6 |
| time/ | |
| episodes | 40 |
| fps | 30 |
| time_elapsed | 73 |
| total_timesteps | 2223 |
| train/ | |
| actor_loss | -26.5 |
| critic_loss | 3.33 |
| ent_coef | 0.539 |
| ent_coef_loss | -2.7 |
| learning_rate | 0.0003 |
| n_updates | 2122 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 59.3 |
| ep_rew_mean | 84.3 |
| time/ | |
| episodes | 44 |
| fps | 29 |
| time_elapsed | 87 |
| total_timesteps | 2611 |
| train/ | |
| actor_loss | -30.8 |
| critic_loss | 3.02 |
| ent_coef | 0.484 |
| ent_coef_loss | -2.95 |
| learning_rate | 0.0003 |
| n_updates | 2510 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 63 |
| ep_rew_mean | 92.5 |
| time/ | |
| episodes | 48 |
| fps | 29 |
| time_elapsed | 102 |
| total_timesteps | 3022 |
| train/ | |
| actor_loss | -34.6 |
| critic_loss | 5.01 |
| ent_coef | 0.432 |
| ent_coef_loss | -3.37 |
| learning_rate | 0.0003 |
| n_updates | 2921 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 66.1 |
| ep_rew_mean | 100 |
| time/ | |
| episodes | 52 |
| fps | 29 |
| time_elapsed | 116 |
| total_timesteps | 3438 |
| train/ | |
| actor_loss | -38.4 |
| critic_loss | 4.94 |
| ent_coef | 0.386 |
| ent_coef_loss | -3.66 |
| learning_rate | 0.0003 |
| n_updates | 3337 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 68.6 |
| ep_rew_mean | 106 |
| time/ | |
| episodes | 56 |
| fps | 29 |
| time_elapsed | 130 |
| total_timesteps | 3843 |
| train/ | |
| actor_loss | -41.6 |
| critic_loss | 5.98 |
| ent_coef | 0.346 |
| ent_coef_loss | -3.74 |
| learning_rate | 0.0003 |
| n_updates | 3742 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 71.2 |
| ep_rew_mean | 113 |
| time/ | |
| episodes | 60 |
| fps | 29 |
| time_elapsed | 145 |
| total_timesteps | 4274 |
| train/ | |
| actor_loss | -45.7 |
| critic_loss | 11.3 |
| ent_coef | 0.309 |
| ent_coef_loss | -3.97 |
| learning_rate | 0.0003 |
| n_updates | 4173 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 73.3 |
| ep_rew_mean | 118 |
| time/ | |
| episodes | 64 |
| fps | 29 |
| time_elapsed | 161 |
| total_timesteps | 4690 |
| train/ | |
| actor_loss | -48.6 |
| critic_loss | 4.11 |
| ent_coef | 0.277 |
| ent_coef_loss | -4 |
| learning_rate | 0.0003 |
| n_updates | 4589 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 75.7 |
| ep_rew_mean | 124 |
| time/ | |
| episodes | 68 |
| fps | 28 |
| time_elapsed | 177 |
| total_timesteps | 5148 |
| train/ | |
| actor_loss | -52.7 |
| critic_loss | 3.6 |
| ent_coef | 0.245 |
| ent_coef_loss | -4.12 |
| learning_rate | 0.0003 |
| n_updates | 5047 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 78 |
| ep_rew_mean | 129 |
| time/ | |
| episodes | 72 |
| fps | 28 |
| time_elapsed | 194 |
| total_timesteps | 5618 |
| train/ | |
| actor_loss | -54.8 |
| critic_loss | 2.11 |
| ent_coef | 0.217 |
| ent_coef_loss | -4.42 |
| learning_rate | 0.0003 |
| n_updates | 5517 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 79.7 |
| ep_rew_mean | 134 |
| time/ | |
| episodes | 76 |
| fps | 28 |
| time_elapsed | 209 |
| total_timesteps | 6056 |
| train/ | |
| actor_loss | -57.5 |
| critic_loss | 3.08 |
| ent_coef | 0.193 |
| ent_coef_loss | -4.5 |
| learning_rate | 0.0003 |
| n_updates | 5955 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 80.1 |
| ep_rew_mean | 135 |
| time/ | |
| episodes | 80 |
| fps | 28 |
| time_elapsed | 222 |
| total_timesteps | 6411 |
| train/ | |
| actor_loss | -60.5 |
| critic_loss | 3.15 |
| ent_coef | 0.176 |
| ent_coef_loss | -4.62 |
| learning_rate | 0.0003 |
| n_updates | 6310 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 82 |
| ep_rew_mean | 140 |
| time/ | |
| episodes | 84 |
| fps | 28 |
| time_elapsed | 238 |
| total_timesteps | 6888 |
| train/ | |
| actor_loss | -62.6 |
| critic_loss | 6.16 |
| ent_coef | 0.155 |
| ent_coef_loss | -3.72 |
| learning_rate | 0.0003 |
| n_updates | 6787 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 84.1 |
| ep_rew_mean | 143 |
| time/ | |
| episodes | 88 |
| fps | 28 |
| time_elapsed | 257 |
| total_timesteps | 7399 |
| train/ | |
| actor_loss | -64.2 |
| critic_loss | 3.59 |
| ent_coef | 0.136 |
| ent_coef_loss | -3.96 |
| learning_rate | 0.0003 |
| n_updates | 7298 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 85.4 |
| ep_rew_mean | 147 |
| time/ | |
| episodes | 92 |
| fps | 28 |
| time_elapsed | 273 |
| total_timesteps | 7860 |
| train/ | |
| actor_loss | -66.6 |
| critic_loss | 5.15 |
| ent_coef | 0.121 |
| ent_coef_loss | -4.37 |
| learning_rate | 0.0003 |
| n_updates | 7759 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 86.6 |
| ep_rew_mean | 150 |
| time/ | |
| episodes | 96 |
| fps | 28 |
| time_elapsed | 288 |
| total_timesteps | 8315 |
| train/ | |
| actor_loss | -66.6 |
| critic_loss | 10 |
| ent_coef | 0.109 |
| ent_coef_loss | -3.13 |
| learning_rate | 0.0003 |
| n_updates | 8214 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 88.6 |
| ep_rew_mean | 154 |
| time/ | |
| episodes | 100 |
| fps | 28 |
| time_elapsed | 308 |
| total_timesteps | 8861 |
| train/ | |
| actor_loss | -72.1 |
| critic_loss | 6.77 |
| ent_coef | 0.0967 |
| ent_coef_loss | -3.7 |
| learning_rate | 0.0003 |
| n_updates | 8760 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 92.4 |
| ep_rew_mean | 162 |
| time/ | |
| episodes | 104 |
| fps | 28 |
| time_elapsed | 324 |
| total_timesteps | 9345 |
| train/ | |
| actor_loss | -74.3 |
| critic_loss | 7.74 |
| ent_coef | 0.0876 |
| ent_coef_loss | -3.5 |
| learning_rate | 0.0003 |
| n_updates | 9244 |
---------------------------------
---------------------------------
| rollout/ | |
| ep_len_mean | 96.3 |
| ep_rew_mean | 171 |
| time/ | |
| episodes | 108 |
| fps | 28 |
| time_elapsed | 340 |
| total_timesteps | 9803 |
| train/ | |
| actor_loss | -77.3 |
| critic_loss | 7.43 |
| ent_coef | 0.0799 |
| ent_coef_loss | -3.14 |
| learning_rate | 0.0003 |
| n_updates | 9702 |
---------------------------------
SAC training completed! ✅
print("\n🤖 SAC Performance:")
video_path_sac = os.path.join(VIDEO_DIR, "sac_hopper.mp4")
reward_sac = record_video(model_sac, env_name, video_path_sac)
display(display_video_html(video_path_sac, "SAC Agent Playing Hopper-v5"))
print(f"Final episode reward: {reward_sac:.2f}")
🤖 SAC Performance:
Episode 1 reward: 221.52
Video saved as ./videos/sac_hopper.mp4
SAC Agent Playing Hopper-v5
Final episode reward: 221.52
5️⃣ TD3 (Twin Delayed Deep Deterministic Policy Gradient)#
TD3 is an off-policy reinforcement learning algorithm that addresses the overestimation bias and instability issues of DDPG. It introduces three key improvements: twin critic networks, delayed policy updates, and target policy smoothing to achieve more stable and reliable learning in continuous control tasks.
Key Features:#
Twin Critic Networks: Uses two Q-networks and takes the minimum to reduce overestimation bias
Delayed Policy Updates: Updates the actor less frequently than critics to reduce error accumulation
Target Policy Smoothing: Adds noise to target actions to prevent overfitting to narrow peaks
Deterministic Policy: Learns a deterministic policy with explicit exploration noise during training
Algorithm Components:#
Actor Network: Outputs deterministic actions μ(s|θ^μ) for continuous control
Twin Critic Networks: Two Q-networks (Q₁, Q₂) that estimate action-value functions
Target Networks: Soft-updated copies of actor (μ’) and both critics (Q₁’, Q₂’)
Experience Replay Buffer: Stores transitions for off-policy learning
Learning Process:#
Critic Update: Minimize TD error using minimum of twin target Q-values: y = r + γ min(Q₁’(s’,ã), Q₂’(s’,ã))
Target Action: ã = μ’(s’) + clip(ε, -c, c) where ε ~ N(0,σ) for smoothing
Actor Update: Maximize Q₁(s,μ(s)) every d steps (delayed updates)
Target Update: Soft update all target networks: θ’ ← τθ + (1-τ)θ’
Three Key Innovations:#
Clipped Double Q-Learning: Use min(Q₁’(s’,ã), Q₂’(s’,ã)) for target computation
Delayed Policy Updates: Update actor every d=2 steps while updating critics every step
Target Policy Smoothing: Add clipped noise to target actions to regularize learning
Hyperparameters:#
Learning Rate: 0.001 (actor), 0.001 (critics) - often same for both
Batch Size: 256 (larger batches typically beneficial)
Replay Buffer Size: 1e6 (large buffer for diverse experience)
Tau: 0.005 (soft update coefficient for target networks)
Gamma: 0.99 (discount factor for future rewards)
Policy Delay: 2 (update actor every 2 critic updates)
Target Noise: 0.2 (standard deviation of target policy smoothing noise)
Noise Clip: 0.5 (clipping range for target policy smoothing)
TD3 is particularly effective for continuous control tasks where DDPG struggles with instability. It’s simpler than SAC but often achieves competitive performance with better sample efficiency than vanilla DDPG. The algorithm is robust and reliable, making it a popular choice for robotics and control applications.
print("Training TD3...")
# Create monitored environment
env_td3 = Monitor(gym.make(env_name), LOG_DIR + "td3/")
# Action noise for exploration
action_noise = NormalActionNoise(mean=np.zeros(n_actions), sigma=0.1 * np.ones(n_actions))
# Initialize TD3 model
model_td3 = TD3(
"MlpPolicy",
env_td3,
action_noise=action_noise,
verbose=1,
tensorboard_log=LOG_DIR + "td3_tensorboard/",
learning_rate=0.001,
buffer_size=200000,
learning_starts=100,
batch_size=100,
tau=0.005,
gamma=0.98,
train_freq=1,
gradient_steps=1,
policy_delay=2,
target_policy_noise=0.2,
target_noise_clip=0.5,
device="auto"
)
# Train TD3
callback_td3 = TrainingCallback()
model_td3.learn(total_timesteps=TOTAL_TIMESTEPS, callback=callback_td3)
model_td3.save("td3_hopper")
print("TD3 training completed! ✅")
print("\n🤖 TD3 Performance:")
video_path_td3 = os.path.join(VIDEO_DIR, "td3_hopper.mp4")
reward_td3 = record_video(model_td3, env_name, video_path_td3)
display(display_video_html(video_path_td3, "TD3 Agent Playing Hopper-v5"))
print(f"Final episode reward: {reward_td3:.2f}")
🤖 TD3 Performance:
Episode 1 reward: 163.29
Video saved as ./videos/td3_hopper.mp4
TD3 Agent Playing Hopper-v5
Final episode reward: 163.29
📊 Learning Curves#
# @title Plot learning curves
# @markdown Plot a comparable learning curves for each algorithm
def plot_learning_curves():
"""Plot learning curves for all algorithms"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
axes = axes.flatten()
algorithms = ['A2C', 'DDPG', 'PPO', 'SAC', 'TD3']
callbacks = [callback_a2c, callback_ddpg, callback_ppo, callback_sac, callback_td3]
for i, (alg, callback) in enumerate(zip(algorithms, callbacks)):
if i < 5: # Only plot first 5 algorithms
ax = axes[i]
if len(callback.rewards) > 0:
# Calculate moving average for smoother curves
window_size = min(50, len(callback.rewards) // 10)
if window_size > 0:
rewards_smooth = np.convolve(callback.rewards,
np.ones(window_size)/window_size,
mode='valid')
episodes_smooth = np.arange(window_size-1, len(callback.rewards))
ax.plot(episodes_smooth, rewards_smooth, label=f'{alg} (smoothed)', linewidth=2)
ax.plot(callback.rewards, alpha=0.3, label=f'{alg} (raw)')
else:
ax.plot(callback.rewards, label=alg)
ax.set_title(f'{alg} Learning Curve')
ax.set_xlabel('Episode')
ax.set_ylabel('Episode Reward')
ax.legend()
ax.grid(True, alpha=0.3)
else:
ax.text(0.5, 0.5, f'No data for {alg}',
ha='center', va='center', transform=ax.transAxes)
# Remove empty subplot
axes[5].remove()
plt.tight_layout()
plt.suptitle('Learning Curves - All Algorithms', fontsize=16, y=1.02)
plt.show()
# Plot learning curves
plot_learning_curves()
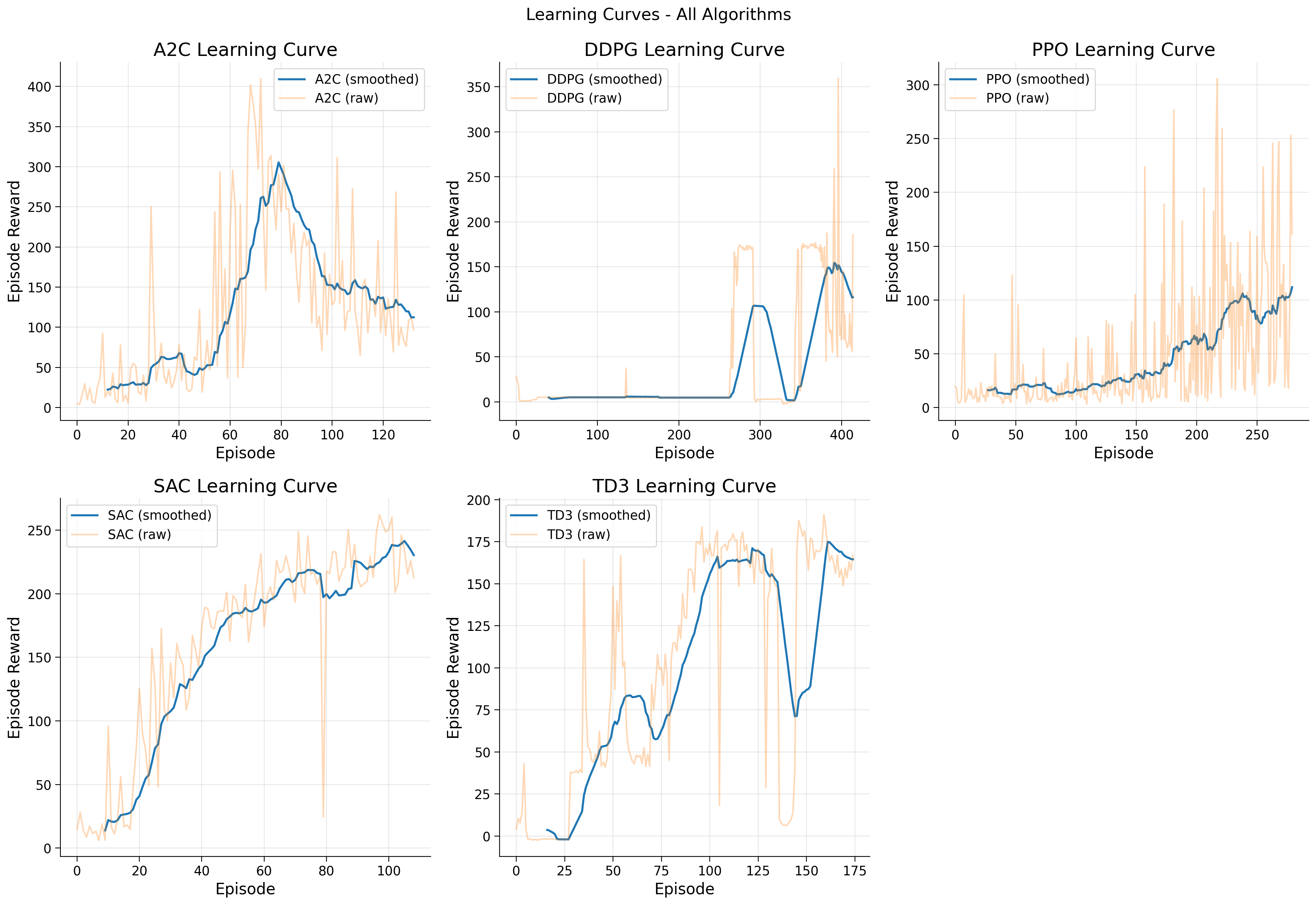
🎥 Performance Videos#
print("🎥 Trained Agent Performances:")
print("=" * 50)
print("\n🎲 Random Agent (Baseline):")
display(display_video_html(video_path_random, "Random Agent Playing Hopper-v5"))
print(f"Episode reward: {reward_random:.2f}")
print("📝 Note: Random agent takes completely random actions - this shows untrained performance")
print("\n🤖 A2C Performance:")
display(display_video_html(video_path_a2c, "A2C Agent Playing Hopper-v5"))
print(f"Final episode reward: {reward_a2c:.2f}")
print("\n🤖 DDPG Performance:")
display(display_video_html(video_path_ddpg, "DDPG Agent Playing Hopper-v5"))
print(f"Final episode reward: {reward_ddpg:.2f}")
print("\n🤖 PPO Performance:")
display(display_video_html(video_path_ppo, "PPO Agent Playing Hopper-v5"))
print(f"Final episode reward: {reward_ppo:.2f}")
print("\n🤖 SAC Performance:")
display(display_video_html(video_path_sac, "SAC Agent Playing Hopper-v5"))
print(f"Final episode reward: {reward_sac:.2f}")
print("\n🤖 TD3 Performance:")
display(display_video_html(video_path_td3, "TD3 Agent Playing Hopper-v5"))
print(f"Final episode reward: {reward_td3:.2f}")
🎥 Trained Agent Performances:
==================================================
🎲 Random Agent (Baseline):
Random Agent Playing Hopper-v5
Episode reward: 13.62
📝 Note: Random agent takes completely random actions - this shows untrained performance
🤖 A2C Performance:
A2C Agent Playing Hopper-v5
Final episode reward: 75.55
🤖 DDPG Performance:
DDPG Agent Playing Hopper-v5
Final episode reward: 185.40
🤖 PPO Performance:
PPO Agent Playing Hopper-v5
Final episode reward: 104.71
🤖 SAC Performance:
SAC Agent Playing Hopper-v5
Final episode reward: 221.52
🤖 TD3 Performance:
TD3 Agent Playing Hopper-v5
Final episode reward: 163.29
🧮 Models Evaluation#
# @title Load trained models
algorithms = ['A2C', 'DDPG', 'PPO', 'SAC', 'TD3']
models = []
print("Loading trained models...")
# Load A2C model
model_a2c_loaded = A2C.load("a2c_hopper")
models.append(model_a2c_loaded)
# Load DDPG model
model_ddpg_loaded = DDPG.load("ddpg_hopper")
models.append(model_ddpg_loaded)
# Load PPO model
model_ppo_loaded = PPO.load("ppo_hopper")
models.append(model_ppo_loaded)
# Load SAC model
model_sac_loaded = SAC.load("sac_hopper")
models.append(model_sac_loaded)
# Load TD3 model
model_td3_loaded = TD3.load("td3_hopper")
models.append(model_td3_loaded)
print("\nAll videos generated successfully! ✅")
Loading trained models...
All videos generated successfully! ✅
def evaluate_all_models():
"""Evaluate all trained models"""
evaluation_env = gym.make(env_name)
results = {}
for alg, model in zip(algorithms, models):
print(f"\nEvaluating {alg}...")
mean_reward, std_reward = evaluate_policy(
model,
evaluation_env,
n_eval_episodes=10,
deterministic=True
)
results[alg] = {
'mean_reward': mean_reward,
'std_reward': std_reward
}
print(f"{alg}: {mean_reward:.2f} ± {std_reward:.2f}")
evaluation_env.close()
return results
# Evaluate all models
evaluation_results = evaluate_all_models()
Evaluating A2C...
def plot_performance_comparison(results):
"""Plot performance comparison bar chart"""
algorithms = list(results.keys())
mean_rewards = [results[alg]['mean_reward'] for alg in algorithms]
std_rewards = [results[alg]['std_reward'] for alg in algorithms]
plt.figure(figsize=(12, 8))
bars = plt.bar(algorithms, mean_rewards, yerr=std_rewards,
capsize=5, color=['blue', 'red', 'green', 'orange', 'purple'])
plt.title('Performance Comparison - All Algorithms on Hopper-v5', fontsize=14)
plt.xlabel('Algorithm', fontsize=12)
plt.ylabel('Average Episode Reward', fontsize=12)
plt.xticks(rotation=45)
# Add value labels on bars
for bar, mean_reward in zip(bars, mean_rewards):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 10,
f'{mean_reward:.1f}', ha='center', va='bottom', fontsize=10)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# Plot performance comparison
plot_performance_comparison(evaluation_results)
📑 Training Summary and Discussion#
print("=" * 60)
print("TRAINING SUMMARY")
print("=" * 60)
print(f"Environment: {env_name}")
print(f"Training timesteps: {TOTAL_TIMESTEPS}")
print(f"Algorithms trained: {', '.join(algorithms)}")
print("\nFinal Performance (10 episodes average):")
print("-" * 40)
for alg in algorithms:
mean_reward = evaluation_results[alg]['mean_reward']
std_reward = evaluation_results[alg]['std_reward']
print(f"{alg:>8}: {mean_reward:>8.2f} ± {std_reward:>6.2f}")
print("\nAll models have been trained and evaluated successfully!")
print("Videos have been recorded and are available for viewing above.")
============================================================
TRAINING SUMMARY
============================================================
Environment: Hopper-v5
Training timesteps: 10000
Algorithms trained: A2C, DDPG, PPO, SAC, TD3
Final Performance (10 episodes average):
----------------------------------------
A2C: 77.62 ± 2.98
DDPG: 187.78 ± 5.83
PPO: 111.50 ± 5.07
SAC: 219.85 ± 2.28
TD3: 164.23 ± 2.78
All models have been trained and evaluated successfully!
Videos have been recorded and are available for viewing above.