![]()

Using RL to Model Cognitive Tasks#
By Neurmatch Academy
Content creators: Morteza Ansarinia, Yamil Vidal, Mobin Nesari
Production editor: Spiros Chavlis
Objective#
This project aims to use behavioral data to train an agent and then use the agent to investigate data produced by human subjects. Having a computational agent that mimics humans in such tests, we will be able to compare its mechanics with human data.
In another conception, we could fit an agent that learns many cognitive tasks that require abstract-level constructs such as executive functions. This is a multi-task control problem.
Setup#
# @title Install dependencies
!pip install gymnasium stable-baselines3[extra] matplotlib --quiet
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 965.4/965.4 kB 13.1 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 363.4/363.4 MB 4.0 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 13.8/13.8 MB 132.7 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 24.6/24.6 MB 98.3 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 883.7/883.7 kB 54.2 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 664.8/664.8 MB 2.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 211.5/211.5 MB 5.7 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 56.3/56.3 MB 16.6 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 127.9/127.9 MB 8.0 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 207.5/207.5 MB 5.6 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 21.1/21.1 MB 43.6 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 184.5/184.5 kB 15.5 MB/s eta 0:00:00
?25h
# @title Imports
# Standard Library Imports
import os
import time
# Third-Party Library Imports
import gymnasium as gym
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import torch
# Specific Submodule Imports
from gymnasium import spaces
from IPython.display import clear_output, display, HTML
from stable_baselines3 import DQN
from stable_baselines3.common.callbacks import BaseCallback
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.results_plotter import load_results, ts2xy
from stable_baselines3 import DQN
from stable_baselines3.common.env_checker import check_env
# @title Figure configs
from IPython.display import clear_output, display, HTML
%matplotlib inline
sns.set()
# @title Make directories
log_dir = "./tmp/gym/"
os.makedirs(log_dir, exist_ok=True)
# @title Plotter function
def plot_training_results(log_folder, title='Learning Curve'):
"""
Plots the training results from a Monitor log file.
:param log_folder: (str) the save location of the results to plot
:param title: (str) the title of the task to plot
"""
x, y = ts2xy(load_results(log_folder), 'timesteps')
# The reward in our env is max 32 (1 per step)
# We can calculate accuracy from this
y_acc = (np.array(y) / 32.0) * 100
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10), sharex=True)
# Plot 1: Episode Rewards
ax1.plot(x, y, color='blue')
ax1.set_title(title)
ax1.set_ylabel('Episode Reward')
ax1.grid(True)
# Plot a rolling average for rewards
y_rolling = pd.Series(y).rolling(50).mean()
ax1.plot(x, y_rolling, color='red', linewidth=2, label='Rolling Avg (50 episodes)')
ax1.legend()
# Plot 2: Episode Accuracy
ax2.plot(x, y_acc, color='green')
ax2.set_ylabel('Episode Accuracy (%)')
ax2.set_xlabel('Timesteps')
ax2.grid(True)
# Plot a rolling average for accuracy
y_acc_rolling = pd.Series(y_acc).rolling(50).mean()
ax2.plot(x, y_acc_rolling, color='orange', linewidth=2, label='Rolling Avg (50 episodes)')
ax2.legend()
plt.tight_layout()
plt.show()
Background#
Cognitive scientists use standard lab tests to tap into specific processes in the brain and behavior. Some examples of those tests are Stroop, N-back, Digit Span, TMT (Trail making tests), and WCST (Wisconsin Card Sorting Tests).
Despite an extensive body of research that explains human performance using descriptive what-models, we still need a more sophisticated approach to gain a better understanding of the underlying processes (i.e., a how-model).
Interestingly, many of such tests can be thought of as a continuous stream of stimuli and corresponding actions, that is in consonant with the RL formulation. In fact, RL itself is in part motivated by how the brain enables goal-directed behaviors using reward systems, making it a good choice to explain human performance.
One behavioral test example would be the N-back task.
In the N-back, participants view a sequence of stimuli, one by one, and are asked to categorize each stimulus as being either match or non-match. Stimuli are usually numbers, and feedback is given at both timestep and trajectory levels.
The agent is rewarded when its response matches the stimulus that was shown N steps back in the episode. A simpler version of the N-back uses two-choice action schema, that is match vs non-match. Once the present stimulus matches the one presented N step back, then the agent is expected to respond to it as being a
match.
Given a trained RL agent, we then find correlates of its fitted parameters with the brain mechanisms. The most straightforward composition could be the correlation of model parameters with the brain activities.
Datasets#
HCP WM task (NMA-CN HCP notebooks)
Any dataset that used cognitive tests would work. Question: limit to behavioral data vs fMRI? Question: Which stimuli and actions to use? classic tests can be modeled using 1) bounded symbolic stimuli/actions (e.g., A, B, C), but more sophisticated one would require texts or images (e.g., face vs neutral images in social stroop dataset) The HCP dataset from NMA-CN contains behavioral and imaging data for 7 cognitive tests including various versions of N-back.
Cognitive Tests Environment#
First we develop an environment in that agents perform a cognitive test, here the N-back.
Human dataset#
We need a dataset of human perfoming a N-back test, with the following features:
participant_id: following the BIDS format, it contains a unique identifier for each participant.trial_index: same astime_step.stimulus: same asobservation.response: same asaction, recorded response by the human subject.expected_response: correct response.is_correct: same asreward, whether the human subject responded correctly.response_time: won’t be used here.
Here we generate a mock dataset with those features, but remember to replace this with real human data.
def generate_mock_nback_dataset(N=2,
n_participants=10,
n_trials=32,
stimulus_choices=list('ABCDEF'),
response_choices=['match', 'non-match']):
"""Generate a mock dataset for the N-back task."""
n_rows = n_participants * n_trials
participant_ids = sorted([f'sub-{pid}' for pid in range(1, n_participants + 1)] * n_trials)
trial_indices = list(range(1, n_trials + 1)) * n_participants
stimulus_sequence = np.random.choice(stimulus_choices, n_rows)
responses = np.random.choice(response_choices, n_rows)
response_times = np.random.exponential(size=n_rows)
df = pd.DataFrame({
'participant_id': participant_ids,
'trial_index': trial_indices,
'stimulus': stimulus_sequence,
'response': responses,
'response_time': response_times
})
# Mark matching stimuli
nbackstim = df['stimulus'].shift(N)
df['expected_response'] = (df['stimulus'] == nbackstim).map({True: 'match', False: 'non-match'})
df['is_correct'] = (df['response'] == df['expected_response'])
# We don't care about burn-in trials (trial < N)
df.loc[df['trial_index'] <= N, 'is_correct'] = True
df.loc[df['trial_index'] <= N, ['response', 'response_time', 'expected_response']] = None
return df
# ========
# Generate the actual data with the provided function and plot some of its features
mock_nback_data = generate_mock_nback_dataset()
mock_nback_data['is_correct'] = mock_nback_data['is_correct'].astype(int)
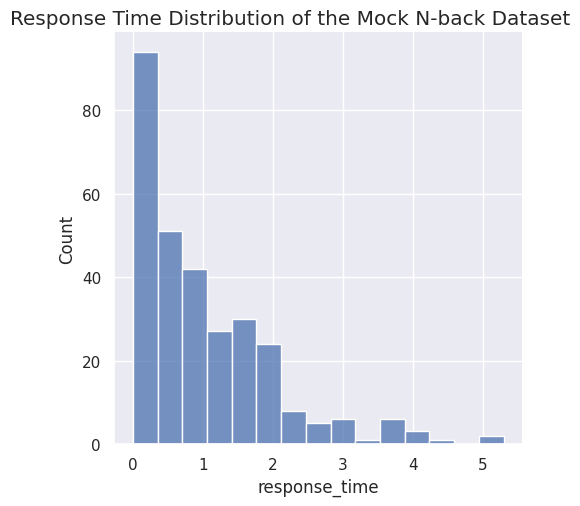
# Plot response time distribution
sns.displot(data=mock_nback_data, x='response_time')
plt.suptitle('Response Time Distribution of the Mock N-back Dataset', y=1.01)
plt.show()
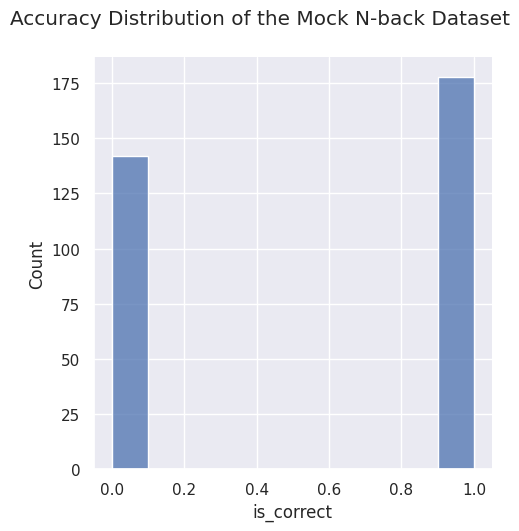
# Plot accuracy distribution
sns.displot(data=mock_nback_data, x='is_correct')
plt.suptitle('Accuracy Distribution of the Mock N-back Dataset', y=1.06)
plt.show()
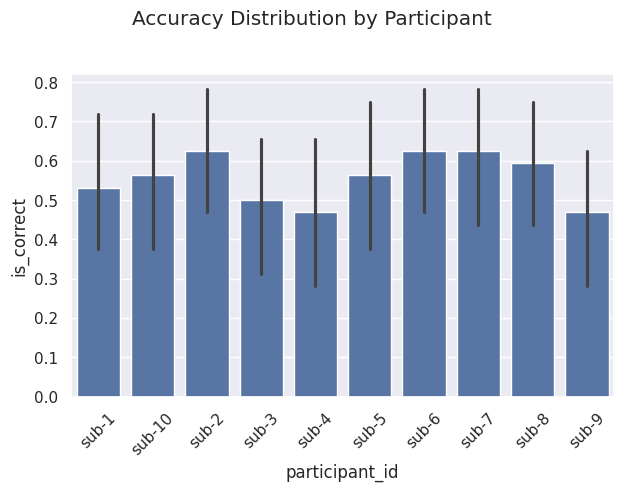
# Plot accuracy by participant
sns.barplot(data=mock_nback_data, y='is_correct', x='participant_id')
plt.suptitle('Accuracy Distribution by Participant', y=1.02)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# Display the first few rows of the dataframe
mock_nback_data.head()
| participant_id | trial_index | stimulus | response | response_time | expected_response | is_correct | |
|---|---|---|---|---|---|---|---|
| 0 | sub-1 | 1 | D | None | NaN | None | 1 |
| 1 | sub-1 | 2 | C | None | NaN | None | 1 |
| 2 | sub-1 | 3 | F | match | 0.081122 | non-match | 0 |
| 3 | sub-1 | 4 | E | match | 1.267059 | non-match | 0 |
| 4 | sub-1 | 5 | B | non-match | 0.432648 | non-match | 1 |
Environment#
The following cell implments N-back envinronment, that we later use to train a RL agent on human data. It is capable of performing two kinds of simulation:
rewards the agent once the action was correct (i.e., a normative model of the environment).
receives human data (or mock data if you prefer), and returns what participants performed as the observation. This is more useful for preference-based RL.
class NBack(gym.Env):
"""
An N-Back task environment compatible with the Gymnasium API.
The agent's goal is to determine if the current stimulus matches the one
presented N steps ago.
Observation:
A numpy array of size (episode_steps,), containing the stimuli
presented up to the current step, padded with zeros for future steps.
Stimuli are encoded as integers.
Actions:
0: 'non-match'
1: 'match'
Reward:
+1 for each correct action.
0 for each incorrect action.
"""
metadata = {'render_modes': ['human']}
ACTIONS = {0: 'non-match', 1: 'match'} # Flipped for easier indexing
def __init__(self,
N=2,
episode_steps=32,
stimuli_choices=6, # Number of distinct stimuli, e.g., 6 for 'A'-'F'
human_data=None,
seed=None):
"""
Args:
N (int): The 'N' in N-back. Number of steps to look back.
episode_steps (int): The total number of trials in an episode.
stimuli_choices (int): The number of unique stimuli.
human_data (pd.DataFrame, optional): A DataFrame with human performance
data. If provided, the environment can run in imitation mode.
Defaults to None.
seed (int, optional): Seed for the random number generator. Defaults to None.
"""
super().__init__()
self.N = N
self.episode_steps = episode_steps
self.num_stimuli = stimuli_choices
# --- Define action and observation spaces ---
# Action space: 0 for 'non-match', 1 for 'match'
self.action_space = spaces.Discrete(len(self.ACTIONS))
# Observation space: The sequence of stimuli seen so far.
# We use a Box space, where each element is an integer representing a stimulus.
# The shape is the full episode length.
self.observation_space = spaces.Box(
low=0,
high=self.num_stimuli - 1,
shape=(episode_steps,),
dtype=np.float32
)
self._stimuli = np.zeros(self.episode_steps, dtype=np.float32)
self._action_history = []
self._current_step = 0
# --- Human imitation logic (optional) ---
self._imitate_human = human_data is not None
self.human_data = human_data
self.human_subject_data = None
# Seed the random number generator
if seed is not None:
self._np_random, _ = gym.utils.seeding.np_random(seed)
else:
self._np_random = np.random.RandomState()
def reset(self, seed=None, options=None):
"""Resets the environment to the beginning of a new episode."""
super().reset(seed=seed)
self._current_step = 0
self._action_history = []
# Generate a new sequence of stimuli for the episode
self._stimuli = self._np_random.choice(self.num_stimuli, self.episode_steps).astype(np.float32)
# TODO: The human imitation logic from the original code can be ported here
# if you need it. For now, it's simplified to generating random sequences.
observation = self._get_observation()
info = self._get_info()
return observation, info
def step(self, action: int):
"""Processes one step of the environment."""
# Determine the expected correct action
is_match = False
if self._current_step >= self.N:
if self._stimuli[self._current_step] == self._stimuli[self._current_step - self.N]:
is_match = True
expected_action = 1 if is_match else 0
# The first N trials don't have a correct answer, so any action is "correct"
# to avoid penalizing the agent.
if self._current_step < self.N:
reward = 1.0
else:
reward = 1.0 if action == expected_action else 0.0
self._action_history.append(self.ACTIONS[action])
self._current_step += 1
# Check for episode termination
terminated = self._current_step >= self.episode_steps
truncated = False # Not using truncation here
observation = self._get_observation()
info = self._get_info()
return observation, reward, terminated, truncated, info
def _get_observation(self):
"""Returns the current observation for the agent."""
obs = np.zeros_like(self._stimuli)
# Agent observes stimuli up to the current trial
obs[:self._current_step] = self._stimuli[:self._current_step]
return obs.astype(np.float32)
def _get_info(self):
"""Returns auxiliary diagnostic information."""
return {
"step": self._current_step,
"stimuli_sequence": self._stimuli
}
def render(self, mode='human'):
"""Renders the current state of the environment for visualization."""
if mode == 'human':
stimuli_str = "".join(map(str, map(int, self._stimuli[:self._current_step])))
actions_str = "".join(['M' if a == 'match' else '.' for a in self._action_history])
html_content = (
f'<b>Environment ({self.N}-back) | Step: {self._current_step}/{self.episode_steps}</b><br />'
f'<pre style="font-family: monospace; font-size: 16px;"><b>Stimuli:</b> {stimuli_str}</pre>'
f'<pre style="font-family: monospace; font-size: 16px;"><b>Actions:</b> {actions_str}</pre>'
)
return HTML(html_content)
else:
super().render(mode=mode)
# Example of how to create and test the environment
print("Testing the NBack Gymnasium Environment...")
# Create the environment
env = NBack(N=2, episode_steps=10)
# Reset the environment
obs, info = env.reset()
print(f"Initial Observation Shape: {obs.shape}")
print(f"Action Space: {env.action_space}")
terminated = False
total_reward = 0
step_count = 0
# Run one episode with random actions
while not terminated:
action = env.action_space.sample() # Take a random action
obs, reward, terminated, truncated, info = env.step(action)
total_reward += reward
step_count += 1
print(f"Step {step_count}: Action={NBack.ACTIONS[action]}, Reward={reward:.1f}")
print("\nEpisode Finished.")
print(f"Total Steps: {step_count}")
print(f"Total Reward: {total_reward}")
# Display final state
display(env.render())
Testing the NBack Gymnasium Environment...
Initial Observation Shape: (10,)
Action Space: Discrete(2)
Step 1: Action=non-match, Reward=1.0
Step 2: Action=match, Reward=1.0
Step 3: Action=match, Reward=1.0
Step 4: Action=non-match, Reward=1.0
Step 5: Action=non-match, Reward=1.0
Step 6: Action=match, Reward=0.0
Step 7: Action=non-match, Reward=1.0
Step 8: Action=non-match, Reward=0.0
Step 9: Action=non-match, Reward=1.0
Step 10: Action=non-match, Reward=1.0
Episode Finished.
Total Steps: 10
Total Reward: 8.0
Stimuli: 2024013113
Actions: .MM..M....
Define a random agent#
For more information you can refer to NMA-DL W3D2 Basic Reinforcement learning.
def run_random_agent_episode(env, render=True):
"""
Runs a single episode in the given Gymnasium environment using random actions.
Args:
env (gym.Env): The Gymnasium environment to run.
render (bool): If True, renders the environment state at each step.
Returns:
tuple: A tuple containing the total reward and the number of steps.
"""
print("🚀 Starting new episode with Random Agent...")
total_reward = 0
obs, info = env.reset()
terminated = False
while not terminated:
# The core of the random agent: sample a random action!
action = env.action_space.sample()
# Take the action in the environment
obs, reward, terminated, truncated, info = env.step(action)
total_reward += reward
if render:
clear_output(wait=True)
display(env.render())
time.sleep(0.1) # Pause for visibility
print(f"🏁 Episode finished in {info['step']} steps.")
print(f"🏆 Total Reward: {total_reward}")
return total_reward, info['step']
# --- Let's run it! ---
# Create the NBack environment
nback_env = NBack(N=2, episode_steps=32)
# Run one full episode with our random agent
run_random_agent_episode(nback_env, render=True)
Stimuli: 13443143523400243433200225254031
Actions: M..M.M.MM.M.MMMM.M..MM....MM.MMM
🏁 Episode finished in 32 steps.
🏆 Total Reward: 17.0
(17.0, 32)
Initialize the environment#
# Create an instance of the N-Back environment
env = NBack(N=2, episode_steps=32)
# The 'agent' is now just the logic that interacts with the environment,
# not a separate class instance.
# Print the environment's specifications
print('Action Space:')
print(env.action_space)
print('\nObservation Space:')
print(env.observation_space)
Action Space:
Discrete(2)
Observation Space:
Box(0.0, 5.0, (32,), float32)
Run the loop#
# Training parameters
n_episodes = 1000
all_returns = []
total_steps = 0
print(f"Running {n_episodes} episodes with a Random Agent...")
# --- Main Loop ---
for episode in range(n_episodes):
episode_return = 0
# Reset the environment for a new episode
observation, info = env.reset()
terminated = False
truncated = False
# Run the episode
while not terminated and not truncated:
# 1. Select a random action (our "Random Agent")
action = env.action_space.sample()
# 2. Step the environment with the action
observation, reward, terminated, truncated, info = env.step(action)
# 3. Book-keeping
episode_return += reward
total_steps += 1
# --- End of Episode ---
all_returns.append(episode_return)
# Log results every 100 episodes to avoid too much output
if (episode + 1) % 100 == 0:
print(f"Episode: {episode + 1}/{n_episodes} | Return: {episode_return:.2f} | Total Steps: {total_steps}")
clear_output(wait=True)
print("✅ All episodes completed.")
print(f"Total steps taken: {total_steps}")
print(f"Average return per episode: {np.mean(all_returns):.2f}")
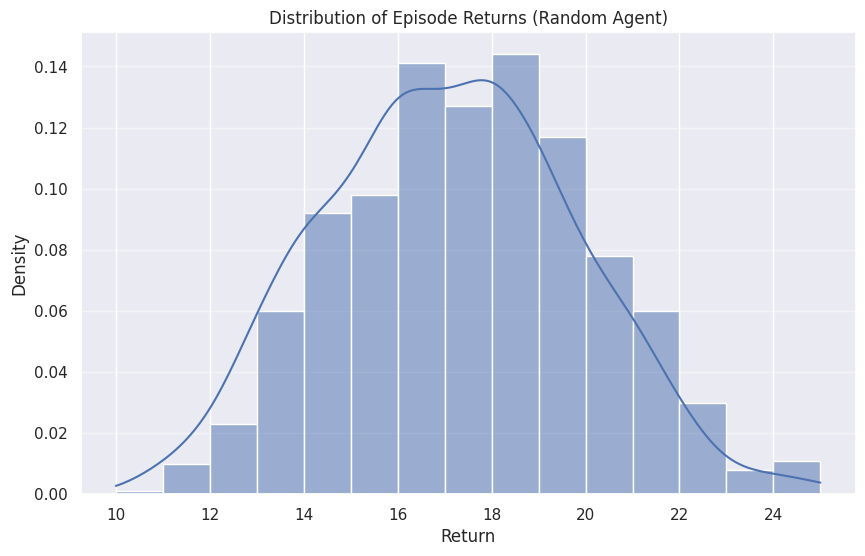
# --- Final Plot ---
# Histogram of all returns
plt.figure(figsize=(10, 6))
sns.histplot(all_returns, stat="density", kde=True, bins=15)
plt.title('Distribution of Episode Returns (Random Agent)')
plt.xlabel('Return')
plt.ylabel('Density')
plt.grid(axis='y', alpha=0.5)
plt.show()
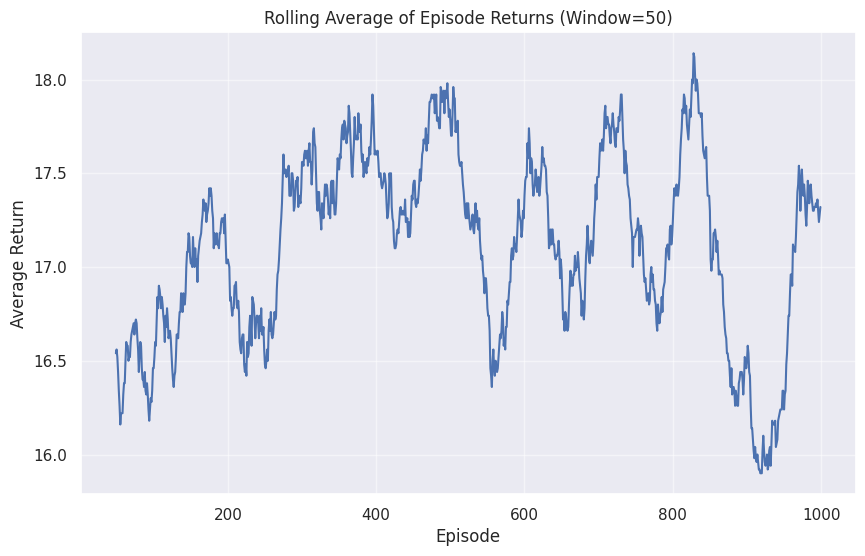
# Also show a rolling average of returns to see if there was any learning
# (There won't be for a random agent, but this is good practice)
rolling_avg = pd.Series(all_returns).rolling(window=50).mean()
plt.figure(figsize=(10, 6))
plt.plot(rolling_avg)
plt.title('Rolling Average of Episode Returns (Window=50)')
plt.xlabel('Episode')
plt.ylabel('Average Return')
plt.grid(True, alpha=0.5)
plt.show()
✅ All episodes completed.
Total steps taken: 32000
Average return per episode: 17.10
Note: You can simplify the environment loop using Stable-Baselines3.
env = NBack(N=2, episode_steps=32)
monitored_env = Monitor(env, log_dir)
Define the network architecture
policy_kwargs = dict(
net_arch=[50, 50] # Two hidden layers with 50 neurons each
)
Construct the DQN agent
# - 'MlpPolicy': Use a standard Multi-Layer Perceptron policy.
# - env: The environment instance for the agent to learn in.
# - policy_kwargs: Our custom network architecture.
# - learning_rate: The step size for the optimizer.
# - buffer_size: The size of the replay buffer.
# - exploration_initial_eps/exploration_final_eps: To mimic the original
# constant epsilon=0.5, we set both to 0.5. For real training, you would
# typically anneal this from 1.0 down to a small value.
# - verbose=1: To print training information.
# - tensorboard_log: Directory for saving TensorBoard logs.
#
agent = DQN(
policy='MlpPolicy',
env=monitored_env,
policy_kwargs=policy_kwargs,
learning_rate=1e-4,
buffer_size=10000,
learning_starts=100, # Number of steps to collect before training starts
batch_size=32,
train_freq=(1, "step"),
target_update_interval=250,
exploration_fraction=0.5, # Not very relevant if initial and final eps are the same
exploration_initial_eps=0.5,
exploration_final_eps=0.5,
verbose=1,
tensorboard_log="./nback_dqn_tensorboard/"
)
Using cpu device
Wrapping the env in a DummyVecEnv.
Inspect the agent
print("\n--- Agent's Network Architecture ---")
print(agent.policy)
print("\nAgent created successfully!")
--- Agent's Network Architecture ---
DQNPolicy(
(q_net): QNetwork(
(features_extractor): FlattenExtractor(
(flatten): Flatten(start_dim=1, end_dim=-1)
)
(q_net): Sequential(
(0): Linear(in_features=32, out_features=50, bias=True)
(1): ReLU()
(2): Linear(in_features=50, out_features=50, bias=True)
(3): ReLU()
(4): Linear(in_features=50, out_features=2, bias=True)
)
)
(q_net_target): QNetwork(
(features_extractor): FlattenExtractor(
(flatten): Flatten(start_dim=1, end_dim=-1)
)
(q_net): Sequential(
(0): Linear(in_features=32, out_features=50, bias=True)
(1): ReLU()
(2): Linear(in_features=50, out_features=50, bias=True)
(3): ReLU()
(4): Linear(in_features=50, out_features=2, bias=True)
)
)
)
Agent created successfully!
Train the agent
n_episodes = 1000
episode_steps = 32
total_timesteps = n_episodes * episode_steps
print(f"🚀 Starting training for {total_timesteps} timesteps...")
agent.learn(total_timesteps=total_timesteps)
print("✅ Training complete.")
🚀 Starting training for 32000 timesteps...
Logging to ./nback_dqn_tensorboard/DQN_1
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 15.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 4 |
| fps | 567 |
| time_elapsed | 0 |
| total_timesteps | 128 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.259 |
| n_updates | 27 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 17.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 8 |
| fps | 480 |
| time_elapsed | 0 |
| total_timesteps | 256 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.305 |
| n_updates | 155 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 19.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 12 |
| fps | 491 |
| time_elapsed | 0 |
| total_timesteps | 384 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.0962 |
| n_updates | 283 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 16 |
| fps | 490 |
| time_elapsed | 1 |
| total_timesteps | 512 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.272 |
| n_updates | 411 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 20 |
| fps | 496 |
| time_elapsed | 1 |
| total_timesteps | 640 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.198 |
| n_updates | 539 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 24 |
| fps | 508 |
| time_elapsed | 1 |
| total_timesteps | 768 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.188 |
| n_updates | 667 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 28 |
| fps | 513 |
| time_elapsed | 1 |
| total_timesteps | 896 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.221 |
| n_updates | 795 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 32 |
| fps | 516 |
| time_elapsed | 1 |
| total_timesteps | 1024 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.212 |
| n_updates | 923 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 36 |
| fps | 522 |
| time_elapsed | 2 |
| total_timesteps | 1152 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.111 |
| n_updates | 1051 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 40 |
| fps | 526 |
| time_elapsed | 2 |
| total_timesteps | 1280 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.401 |
| n_updates | 1179 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.5 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 44 |
| fps | 531 |
| time_elapsed | 2 |
| total_timesteps | 1408 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.208 |
| n_updates | 1307 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 48 |
| fps | 534 |
| time_elapsed | 2 |
| total_timesteps | 1536 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.189 |
| n_updates | 1435 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 52 |
| fps | 532 |
| time_elapsed | 3 |
| total_timesteps | 1664 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.251 |
| n_updates | 1563 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 56 |
| fps | 535 |
| time_elapsed | 3 |
| total_timesteps | 1792 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.145 |
| n_updates | 1691 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 60 |
| fps | 528 |
| time_elapsed | 3 |
| total_timesteps | 1920 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.183 |
| n_updates | 1819 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 64 |
| fps | 521 |
| time_elapsed | 3 |
| total_timesteps | 2048 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.325 |
| n_updates | 1947 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 68 |
| fps | 510 |
| time_elapsed | 4 |
| total_timesteps | 2176 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.11 |
| n_updates | 2075 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 72 |
| fps | 494 |
| time_elapsed | 4 |
| total_timesteps | 2304 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.211 |
| n_updates | 2203 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 76 |
| fps | 482 |
| time_elapsed | 5 |
| total_timesteps | 2432 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.186 |
| n_updates | 2331 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 80 |
| fps | 484 |
| time_elapsed | 5 |
| total_timesteps | 2560 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.272 |
| n_updates | 2459 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 20.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 84 |
| fps | 487 |
| time_elapsed | 5 |
| total_timesteps | 2688 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.524 |
| n_updates | 2587 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 88 |
| fps | 488 |
| time_elapsed | 5 |
| total_timesteps | 2816 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.2 |
| n_updates | 2715 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 92 |
| fps | 491 |
| time_elapsed | 5 |
| total_timesteps | 2944 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.106 |
| n_updates | 2843 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 96 |
| fps | 492 |
| time_elapsed | 6 |
| total_timesteps | 3072 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.545 |
| n_updates | 2971 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 100 |
| fps | 493 |
| time_elapsed | 6 |
| total_timesteps | 3200 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.233 |
| n_updates | 3099 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 104 |
| fps | 495 |
| time_elapsed | 6 |
| total_timesteps | 3328 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.256 |
| n_updates | 3227 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 108 |
| fps | 497 |
| time_elapsed | 6 |
| total_timesteps | 3456 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.47 |
| n_updates | 3355 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 112 |
| fps | 496 |
| time_elapsed | 7 |
| total_timesteps | 3584 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.225 |
| n_updates | 3483 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 116 |
| fps | 498 |
| time_elapsed | 7 |
| total_timesteps | 3712 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.241 |
| n_updates | 3611 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 120 |
| fps | 501 |
| time_elapsed | 7 |
| total_timesteps | 3840 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.185 |
| n_updates | 3739 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 124 |
| fps | 504 |
| time_elapsed | 7 |
| total_timesteps | 3968 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.48 |
| n_updates | 3867 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 128 |
| fps | 505 |
| time_elapsed | 8 |
| total_timesteps | 4096 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.325 |
| n_updates | 3995 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 132 |
| fps | 507 |
| time_elapsed | 8 |
| total_timesteps | 4224 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.362 |
| n_updates | 4123 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 136 |
| fps | 507 |
| time_elapsed | 8 |
| total_timesteps | 4352 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.266 |
| n_updates | 4251 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 140 |
| fps | 504 |
| time_elapsed | 8 |
| total_timesteps | 4480 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.319 |
| n_updates | 4379 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 144 |
| fps | 504 |
| time_elapsed | 9 |
| total_timesteps | 4608 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.192 |
| n_updates | 4507 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 148 |
| fps | 505 |
| time_elapsed | 9 |
| total_timesteps | 4736 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.207 |
| n_updates | 4635 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 152 |
| fps | 506 |
| time_elapsed | 9 |
| total_timesteps | 4864 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.624 |
| n_updates | 4763 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.5 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 156 |
| fps | 508 |
| time_elapsed | 9 |
| total_timesteps | 4992 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.183 |
| n_updates | 4891 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 160 |
| fps | 510 |
| time_elapsed | 10 |
| total_timesteps | 5120 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.255 |
| n_updates | 5019 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 164 |
| fps | 510 |
| time_elapsed | 10 |
| total_timesteps | 5248 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.478 |
| n_updates | 5147 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 168 |
| fps | 509 |
| time_elapsed | 10 |
| total_timesteps | 5376 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.191 |
| n_updates | 5275 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 172 |
| fps | 510 |
| time_elapsed | 10 |
| total_timesteps | 5504 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.32 |
| n_updates | 5403 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 176 |
| fps | 511 |
| time_elapsed | 11 |
| total_timesteps | 5632 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.264 |
| n_updates | 5531 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 180 |
| fps | 512 |
| time_elapsed | 11 |
| total_timesteps | 5760 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.305 |
| n_updates | 5659 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 184 |
| fps | 512 |
| time_elapsed | 11 |
| total_timesteps | 5888 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.252 |
| n_updates | 5787 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 188 |
| fps | 512 |
| time_elapsed | 11 |
| total_timesteps | 6016 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.531 |
| n_updates | 5915 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 192 |
| fps | 513 |
| time_elapsed | 11 |
| total_timesteps | 6144 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.267 |
| n_updates | 6043 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 196 |
| fps | 514 |
| time_elapsed | 12 |
| total_timesteps | 6272 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.476 |
| n_updates | 6171 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 200 |
| fps | 513 |
| time_elapsed | 12 |
| total_timesteps | 6400 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.164 |
| n_updates | 6299 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 204 |
| fps | 512 |
| time_elapsed | 12 |
| total_timesteps | 6528 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.209 |
| n_updates | 6427 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.5 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 208 |
| fps | 513 |
| time_elapsed | 12 |
| total_timesteps | 6656 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.242 |
| n_updates | 6555 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 212 |
| fps | 513 |
| time_elapsed | 13 |
| total_timesteps | 6784 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.424 |
| n_updates | 6683 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 216 |
| fps | 513 |
| time_elapsed | 13 |
| total_timesteps | 6912 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.234 |
| n_updates | 6811 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 220 |
| fps | 514 |
| time_elapsed | 13 |
| total_timesteps | 7040 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.329 |
| n_updates | 6939 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 224 |
| fps | 514 |
| time_elapsed | 13 |
| total_timesteps | 7168 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.338 |
| n_updates | 7067 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 228 |
| fps | 515 |
| time_elapsed | 14 |
| total_timesteps | 7296 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.389 |
| n_updates | 7195 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 232 |
| fps | 516 |
| time_elapsed | 14 |
| total_timesteps | 7424 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.287 |
| n_updates | 7323 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 236 |
| fps | 517 |
| time_elapsed | 14 |
| total_timesteps | 7552 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.267 |
| n_updates | 7451 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 240 |
| fps | 518 |
| time_elapsed | 14 |
| total_timesteps | 7680 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.216 |
| n_updates | 7579 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 244 |
| fps | 517 |
| time_elapsed | 15 |
| total_timesteps | 7808 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.284 |
| n_updates | 7707 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 248 |
| fps | 515 |
| time_elapsed | 15 |
| total_timesteps | 7936 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.291 |
| n_updates | 7835 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 252 |
| fps | 514 |
| time_elapsed | 15 |
| total_timesteps | 8064 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.278 |
| n_updates | 7963 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 256 |
| fps | 512 |
| time_elapsed | 15 |
| total_timesteps | 8192 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.181 |
| n_updates | 8091 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 260 |
| fps | 508 |
| time_elapsed | 16 |
| total_timesteps | 8320 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.321 |
| n_updates | 8219 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 264 |
| fps | 508 |
| time_elapsed | 16 |
| total_timesteps | 8448 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.313 |
| n_updates | 8347 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 268 |
| fps | 509 |
| time_elapsed | 16 |
| total_timesteps | 8576 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.275 |
| n_updates | 8475 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 272 |
| fps | 510 |
| time_elapsed | 17 |
| total_timesteps | 8704 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.279 |
| n_updates | 8603 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 276 |
| fps | 511 |
| time_elapsed | 17 |
| total_timesteps | 8832 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.157 |
| n_updates | 8731 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 280 |
| fps | 512 |
| time_elapsed | 17 |
| total_timesteps | 8960 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.355 |
| n_updates | 8859 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 284 |
| fps | 512 |
| time_elapsed | 17 |
| total_timesteps | 9088 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.246 |
| n_updates | 8987 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 288 |
| fps | 513 |
| time_elapsed | 17 |
| total_timesteps | 9216 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.262 |
| n_updates | 9115 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 292 |
| fps | 513 |
| time_elapsed | 18 |
| total_timesteps | 9344 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.461 |
| n_updates | 9243 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 296 |
| fps | 513 |
| time_elapsed | 18 |
| total_timesteps | 9472 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.353 |
| n_updates | 9371 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 300 |
| fps | 512 |
| time_elapsed | 18 |
| total_timesteps | 9600 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.346 |
| n_updates | 9499 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 304 |
| fps | 513 |
| time_elapsed | 18 |
| total_timesteps | 9728 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.281 |
| n_updates | 9627 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 308 |
| fps | 514 |
| time_elapsed | 19 |
| total_timesteps | 9856 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.299 |
| n_updates | 9755 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 312 |
| fps | 513 |
| time_elapsed | 19 |
| total_timesteps | 9984 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.181 |
| n_updates | 9883 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 316 |
| fps | 513 |
| time_elapsed | 19 |
| total_timesteps | 10112 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.386 |
| n_updates | 10011 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 320 |
| fps | 514 |
| time_elapsed | 19 |
| total_timesteps | 10240 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.269 |
| n_updates | 10139 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 324 |
| fps | 515 |
| time_elapsed | 20 |
| total_timesteps | 10368 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.402 |
| n_updates | 10267 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 328 |
| fps | 515 |
| time_elapsed | 20 |
| total_timesteps | 10496 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.268 |
| n_updates | 10395 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 332 |
| fps | 516 |
| time_elapsed | 20 |
| total_timesteps | 10624 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.266 |
| n_updates | 10523 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 336 |
| fps | 516 |
| time_elapsed | 20 |
| total_timesteps | 10752 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.219 |
| n_updates | 10651 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 340 |
| fps | 516 |
| time_elapsed | 21 |
| total_timesteps | 10880 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.37 |
| n_updates | 10779 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 344 |
| fps | 516 |
| time_elapsed | 21 |
| total_timesteps | 11008 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.241 |
| n_updates | 10907 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 348 |
| fps | 516 |
| time_elapsed | 21 |
| total_timesteps | 11136 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.299 |
| n_updates | 11035 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 352 |
| fps | 516 |
| time_elapsed | 21 |
| total_timesteps | 11264 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.311 |
| n_updates | 11163 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 356 |
| fps | 517 |
| time_elapsed | 22 |
| total_timesteps | 11392 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.0982 |
| n_updates | 11291 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 360 |
| fps | 517 |
| time_elapsed | 22 |
| total_timesteps | 11520 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.267 |
| n_updates | 11419 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 364 |
| fps | 518 |
| time_elapsed | 22 |
| total_timesteps | 11648 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.287 |
| n_updates | 11547 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 368 |
| fps | 517 |
| time_elapsed | 22 |
| total_timesteps | 11776 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.311 |
| n_updates | 11675 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 372 |
| fps | 518 |
| time_elapsed | 22 |
| total_timesteps | 11904 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.259 |
| n_updates | 11803 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 376 |
| fps | 518 |
| time_elapsed | 23 |
| total_timesteps | 12032 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.249 |
| n_updates | 11931 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 380 |
| fps | 519 |
| time_elapsed | 23 |
| total_timesteps | 12160 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.302 |
| n_updates | 12059 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 384 |
| fps | 519 |
| time_elapsed | 23 |
| total_timesteps | 12288 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.31 |
| n_updates | 12187 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 388 |
| fps | 520 |
| time_elapsed | 23 |
| total_timesteps | 12416 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.248 |
| n_updates | 12315 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 392 |
| fps | 520 |
| time_elapsed | 24 |
| total_timesteps | 12544 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.152 |
| n_updates | 12443 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 396 |
| fps | 520 |
| time_elapsed | 24 |
| total_timesteps | 12672 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.2 |
| n_updates | 12571 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 400 |
| fps | 520 |
| time_elapsed | 24 |
| total_timesteps | 12800 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.139 |
| n_updates | 12699 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 404 |
| fps | 520 |
| time_elapsed | 24 |
| total_timesteps | 12928 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.289 |
| n_updates | 12827 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 408 |
| fps | 521 |
| time_elapsed | 25 |
| total_timesteps | 13056 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.357 |
| n_updates | 12955 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 412 |
| fps | 521 |
| time_elapsed | 25 |
| total_timesteps | 13184 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.33 |
| n_updates | 13083 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 416 |
| fps | 521 |
| time_elapsed | 25 |
| total_timesteps | 13312 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.377 |
| n_updates | 13211 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 420 |
| fps | 522 |
| time_elapsed | 25 |
| total_timesteps | 13440 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.217 |
| n_updates | 13339 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 424 |
| fps | 522 |
| time_elapsed | 25 |
| total_timesteps | 13568 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.333 |
| n_updates | 13467 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 428 |
| fps | 523 |
| time_elapsed | 26 |
| total_timesteps | 13696 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.183 |
| n_updates | 13595 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 432 |
| fps | 522 |
| time_elapsed | 26 |
| total_timesteps | 13824 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.216 |
| n_updates | 13723 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 436 |
| fps | 521 |
| time_elapsed | 26 |
| total_timesteps | 13952 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.33 |
| n_updates | 13851 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 440 |
| fps | 521 |
| time_elapsed | 27 |
| total_timesteps | 14080 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.231 |
| n_updates | 13979 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 444 |
| fps | 520 |
| time_elapsed | 27 |
| total_timesteps | 14208 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.387 |
| n_updates | 14107 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 448 |
| fps | 518 |
| time_elapsed | 27 |
| total_timesteps | 14336 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.294 |
| n_updates | 14235 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 452 |
| fps | 518 |
| time_elapsed | 27 |
| total_timesteps | 14464 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.267 |
| n_updates | 14363 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 456 |
| fps | 518 |
| time_elapsed | 28 |
| total_timesteps | 14592 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.392 |
| n_updates | 14491 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 460 |
| fps | 519 |
| time_elapsed | 28 |
| total_timesteps | 14720 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.185 |
| n_updates | 14619 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 464 |
| fps | 519 |
| time_elapsed | 28 |
| total_timesteps | 14848 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.177 |
| n_updates | 14747 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 468 |
| fps | 519 |
| time_elapsed | 28 |
| total_timesteps | 14976 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.261 |
| n_updates | 14875 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 472 |
| fps | 519 |
| time_elapsed | 29 |
| total_timesteps | 15104 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.254 |
| n_updates | 15003 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 476 |
| fps | 519 |
| time_elapsed | 29 |
| total_timesteps | 15232 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.225 |
| n_updates | 15131 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 480 |
| fps | 520 |
| time_elapsed | 29 |
| total_timesteps | 15360 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.204 |
| n_updates | 15259 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 484 |
| fps | 519 |
| time_elapsed | 29 |
| total_timesteps | 15488 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.248 |
| n_updates | 15387 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 488 |
| fps | 519 |
| time_elapsed | 30 |
| total_timesteps | 15616 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.267 |
| n_updates | 15515 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 492 |
| fps | 519 |
| time_elapsed | 30 |
| total_timesteps | 15744 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.191 |
| n_updates | 15643 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 496 |
| fps | 518 |
| time_elapsed | 30 |
| total_timesteps | 15872 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.176 |
| n_updates | 15771 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 500 |
| fps | 519 |
| time_elapsed | 30 |
| total_timesteps | 16000 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.246 |
| n_updates | 15899 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 504 |
| fps | 519 |
| time_elapsed | 31 |
| total_timesteps | 16128 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.23 |
| n_updates | 16027 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 508 |
| fps | 519 |
| time_elapsed | 31 |
| total_timesteps | 16256 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.305 |
| n_updates | 16155 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 512 |
| fps | 519 |
| time_elapsed | 31 |
| total_timesteps | 16384 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.294 |
| n_updates | 16283 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 516 |
| fps | 520 |
| time_elapsed | 31 |
| total_timesteps | 16512 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.235 |
| n_updates | 16411 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 520 |
| fps | 520 |
| time_elapsed | 31 |
| total_timesteps | 16640 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.273 |
| n_updates | 16539 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 524 |
| fps | 521 |
| time_elapsed | 32 |
| total_timesteps | 16768 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.264 |
| n_updates | 16667 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 528 |
| fps | 521 |
| time_elapsed | 32 |
| total_timesteps | 16896 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.254 |
| n_updates | 16795 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 532 |
| fps | 522 |
| time_elapsed | 32 |
| total_timesteps | 17024 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.253 |
| n_updates | 16923 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 536 |
| fps | 517 |
| time_elapsed | 33 |
| total_timesteps | 17152 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.237 |
| n_updates | 17051 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 540 |
| fps | 518 |
| time_elapsed | 33 |
| total_timesteps | 17280 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.236 |
| n_updates | 17179 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 544 |
| fps | 514 |
| time_elapsed | 33 |
| total_timesteps | 17408 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.301 |
| n_updates | 17307 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 548 |
| fps | 514 |
| time_elapsed | 34 |
| total_timesteps | 17536 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.237 |
| n_updates | 17435 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 552 |
| fps | 514 |
| time_elapsed | 34 |
| total_timesteps | 17664 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.303 |
| n_updates | 17563 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 556 |
| fps | 511 |
| time_elapsed | 34 |
| total_timesteps | 17792 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.411 |
| n_updates | 17691 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 560 |
| fps | 511 |
| time_elapsed | 35 |
| total_timesteps | 17920 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.352 |
| n_updates | 17819 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 564 |
| fps | 511 |
| time_elapsed | 35 |
| total_timesteps | 18048 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.345 |
| n_updates | 17947 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 568 |
| fps | 512 |
| time_elapsed | 35 |
| total_timesteps | 18176 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.327 |
| n_updates | 18075 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 572 |
| fps | 512 |
| time_elapsed | 35 |
| total_timesteps | 18304 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.255 |
| n_updates | 18203 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 576 |
| fps | 512 |
| time_elapsed | 35 |
| total_timesteps | 18432 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.233 |
| n_updates | 18331 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 580 |
| fps | 512 |
| time_elapsed | 36 |
| total_timesteps | 18560 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.173 |
| n_updates | 18459 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 584 |
| fps | 513 |
| time_elapsed | 36 |
| total_timesteps | 18688 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.297 |
| n_updates | 18587 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 588 |
| fps | 513 |
| time_elapsed | 36 |
| total_timesteps | 18816 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.176 |
| n_updates | 18715 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 592 |
| fps | 513 |
| time_elapsed | 36 |
| total_timesteps | 18944 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.273 |
| n_updates | 18843 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 596 |
| fps | 512 |
| time_elapsed | 37 |
| total_timesteps | 19072 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.33 |
| n_updates | 18971 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 600 |
| fps | 512 |
| time_elapsed | 37 |
| total_timesteps | 19200 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.231 |
| n_updates | 19099 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 604 |
| fps | 510 |
| time_elapsed | 37 |
| total_timesteps | 19328 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.235 |
| n_updates | 19227 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 608 |
| fps | 508 |
| time_elapsed | 38 |
| total_timesteps | 19456 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.255 |
| n_updates | 19355 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 612 |
| fps | 507 |
| time_elapsed | 38 |
| total_timesteps | 19584 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.287 |
| n_updates | 19483 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 616 |
| fps | 505 |
| time_elapsed | 39 |
| total_timesteps | 19712 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.192 |
| n_updates | 19611 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 620 |
| fps | 503 |
| time_elapsed | 39 |
| total_timesteps | 19840 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.227 |
| n_updates | 19739 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 624 |
| fps | 503 |
| time_elapsed | 39 |
| total_timesteps | 19968 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.292 |
| n_updates | 19867 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 628 |
| fps | 503 |
| time_elapsed | 39 |
| total_timesteps | 20096 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.313 |
| n_updates | 19995 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 632 |
| fps | 504 |
| time_elapsed | 40 |
| total_timesteps | 20224 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.202 |
| n_updates | 20123 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 636 |
| fps | 504 |
| time_elapsed | 40 |
| total_timesteps | 20352 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.238 |
| n_updates | 20251 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 640 |
| fps | 504 |
| time_elapsed | 40 |
| total_timesteps | 20480 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.328 |
| n_updates | 20379 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 644 |
| fps | 504 |
| time_elapsed | 40 |
| total_timesteps | 20608 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.299 |
| n_updates | 20507 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 648 |
| fps | 505 |
| time_elapsed | 41 |
| total_timesteps | 20736 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.246 |
| n_updates | 20635 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 652 |
| fps | 505 |
| time_elapsed | 41 |
| total_timesteps | 20864 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.24 |
| n_updates | 20763 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 656 |
| fps | 506 |
| time_elapsed | 41 |
| total_timesteps | 20992 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.301 |
| n_updates | 20891 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 660 |
| fps | 506 |
| time_elapsed | 41 |
| total_timesteps | 21120 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.275 |
| n_updates | 21019 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 664 |
| fps | 506 |
| time_elapsed | 41 |
| total_timesteps | 21248 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.322 |
| n_updates | 21147 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 668 |
| fps | 506 |
| time_elapsed | 42 |
| total_timesteps | 21376 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.167 |
| n_updates | 21275 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 672 |
| fps | 506 |
| time_elapsed | 42 |
| total_timesteps | 21504 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.21 |
| n_updates | 21403 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 676 |
| fps | 506 |
| time_elapsed | 42 |
| total_timesteps | 21632 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.21 |
| n_updates | 21531 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 680 |
| fps | 507 |
| time_elapsed | 42 |
| total_timesteps | 21760 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.227 |
| n_updates | 21659 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 684 |
| fps | 507 |
| time_elapsed | 43 |
| total_timesteps | 21888 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.172 |
| n_updates | 21787 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 688 |
| fps | 507 |
| time_elapsed | 43 |
| total_timesteps | 22016 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.321 |
| n_updates | 21915 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 692 |
| fps | 507 |
| time_elapsed | 43 |
| total_timesteps | 22144 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.185 |
| n_updates | 22043 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 696 |
| fps | 507 |
| time_elapsed | 43 |
| total_timesteps | 22272 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.292 |
| n_updates | 22171 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 700 |
| fps | 507 |
| time_elapsed | 44 |
| total_timesteps | 22400 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.452 |
| n_updates | 22299 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 704 |
| fps | 508 |
| time_elapsed | 44 |
| total_timesteps | 22528 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.389 |
| n_updates | 22427 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 708 |
| fps | 508 |
| time_elapsed | 44 |
| total_timesteps | 22656 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.256 |
| n_updates | 22555 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 712 |
| fps | 508 |
| time_elapsed | 44 |
| total_timesteps | 22784 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.312 |
| n_updates | 22683 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 716 |
| fps | 508 |
| time_elapsed | 45 |
| total_timesteps | 22912 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.317 |
| n_updates | 22811 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 720 |
| fps | 508 |
| time_elapsed | 45 |
| total_timesteps | 23040 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.307 |
| n_updates | 22939 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 724 |
| fps | 509 |
| time_elapsed | 45 |
| total_timesteps | 23168 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.289 |
| n_updates | 23067 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 728 |
| fps | 509 |
| time_elapsed | 45 |
| total_timesteps | 23296 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.233 |
| n_updates | 23195 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 732 |
| fps | 509 |
| time_elapsed | 45 |
| total_timesteps | 23424 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.269 |
| n_updates | 23323 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 736 |
| fps | 509 |
| time_elapsed | 46 |
| total_timesteps | 23552 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.389 |
| n_updates | 23451 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 740 |
| fps | 509 |
| time_elapsed | 46 |
| total_timesteps | 23680 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.198 |
| n_updates | 23579 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 744 |
| fps | 509 |
| time_elapsed | 46 |
| total_timesteps | 23808 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.184 |
| n_updates | 23707 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 748 |
| fps | 510 |
| time_elapsed | 46 |
| total_timesteps | 23936 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.204 |
| n_updates | 23835 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 752 |
| fps | 510 |
| time_elapsed | 47 |
| total_timesteps | 24064 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.336 |
| n_updates | 23963 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 756 |
| fps | 511 |
| time_elapsed | 47 |
| total_timesteps | 24192 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.231 |
| n_updates | 24091 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 760 |
| fps | 511 |
| time_elapsed | 47 |
| total_timesteps | 24320 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.308 |
| n_updates | 24219 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 764 |
| fps | 511 |
| time_elapsed | 47 |
| total_timesteps | 24448 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.36 |
| n_updates | 24347 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 768 |
| fps | 511 |
| time_elapsed | 48 |
| total_timesteps | 24576 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.269 |
| n_updates | 24475 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 772 |
| fps | 512 |
| time_elapsed | 48 |
| total_timesteps | 24704 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.294 |
| n_updates | 24603 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 776 |
| fps | 512 |
| time_elapsed | 48 |
| total_timesteps | 24832 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.319 |
| n_updates | 24731 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.4 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 780 |
| fps | 511 |
| time_elapsed | 48 |
| total_timesteps | 24960 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.229 |
| n_updates | 24859 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 784 |
| fps | 511 |
| time_elapsed | 49 |
| total_timesteps | 25088 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.319 |
| n_updates | 24987 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.3 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 788 |
| fps | 510 |
| time_elapsed | 49 |
| total_timesteps | 25216 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.301 |
| n_updates | 25115 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 792 |
| fps | 508 |
| time_elapsed | 49 |
| total_timesteps | 25344 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.282 |
| n_updates | 25243 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 796 |
| fps | 508 |
| time_elapsed | 50 |
| total_timesteps | 25472 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.203 |
| n_updates | 25371 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 800 |
| fps | 507 |
| time_elapsed | 50 |
| total_timesteps | 25600 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.284 |
| n_updates | 25499 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 804 |
| fps | 506 |
| time_elapsed | 50 |
| total_timesteps | 25728 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.225 |
| n_updates | 25627 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 808 |
| fps | 506 |
| time_elapsed | 51 |
| total_timesteps | 25856 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.168 |
| n_updates | 25755 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 812 |
| fps | 507 |
| time_elapsed | 51 |
| total_timesteps | 25984 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.352 |
| n_updates | 25883 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.2 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 816 |
| fps | 507 |
| time_elapsed | 51 |
| total_timesteps | 26112 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.309 |
| n_updates | 26011 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 820 |
| fps | 507 |
| time_elapsed | 51 |
| total_timesteps | 26240 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.213 |
| n_updates | 26139 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22.1 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 824 |
| fps | 507 |
| time_elapsed | 51 |
| total_timesteps | 26368 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.217 |
| n_updates | 26267 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 828 |
| fps | 507 |
| time_elapsed | 52 |
| total_timesteps | 26496 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.269 |
| n_updates | 26395 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 832 |
| fps | 508 |
| time_elapsed | 52 |
| total_timesteps | 26624 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.29 |
| n_updates | 26523 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 836 |
| fps | 508 |
| time_elapsed | 52 |
| total_timesteps | 26752 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.235 |
| n_updates | 26651 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 22 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 840 |
| fps | 508 |
| time_elapsed | 52 |
| total_timesteps | 26880 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.334 |
| n_updates | 26779 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 844 |
| fps | 508 |
| time_elapsed | 53 |
| total_timesteps | 27008 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.324 |
| n_updates | 26907 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 848 |
| fps | 509 |
| time_elapsed | 53 |
| total_timesteps | 27136 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.256 |
| n_updates | 27035 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 852 |
| fps | 508 |
| time_elapsed | 53 |
| total_timesteps | 27264 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.256 |
| n_updates | 27163 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 856 |
| fps | 508 |
| time_elapsed | 53 |
| total_timesteps | 27392 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.326 |
| n_updates | 27291 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 860 |
| fps | 508 |
| time_elapsed | 54 |
| total_timesteps | 27520 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.166 |
| n_updates | 27419 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 864 |
| fps | 508 |
| time_elapsed | 54 |
| total_timesteps | 27648 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.322 |
| n_updates | 27547 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 868 |
| fps | 508 |
| time_elapsed | 54 |
| total_timesteps | 27776 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.258 |
| n_updates | 27675 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 872 |
| fps | 508 |
| time_elapsed | 54 |
| total_timesteps | 27904 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.413 |
| n_updates | 27803 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 876 |
| fps | 508 |
| time_elapsed | 55 |
| total_timesteps | 28032 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.228 |
| n_updates | 27931 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.9 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 880 |
| fps | 508 |
| time_elapsed | 55 |
| total_timesteps | 28160 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.302 |
| n_updates | 28059 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 884 |
| fps | 508 |
| time_elapsed | 55 |
| total_timesteps | 28288 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.415 |
| n_updates | 28187 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 888 |
| fps | 508 |
| time_elapsed | 55 |
| total_timesteps | 28416 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.284 |
| n_updates | 28315 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 892 |
| fps | 508 |
| time_elapsed | 56 |
| total_timesteps | 28544 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.308 |
| n_updates | 28443 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 896 |
| fps | 508 |
| time_elapsed | 56 |
| total_timesteps | 28672 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.28 |
| n_updates | 28571 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 900 |
| fps | 508 |
| time_elapsed | 56 |
| total_timesteps | 28800 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.208 |
| n_updates | 28699 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 904 |
| fps | 507 |
| time_elapsed | 56 |
| total_timesteps | 28928 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.165 |
| n_updates | 28827 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 908 |
| fps | 507 |
| time_elapsed | 57 |
| total_timesteps | 29056 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.268 |
| n_updates | 28955 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 912 |
| fps | 507 |
| time_elapsed | 57 |
| total_timesteps | 29184 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.221 |
| n_updates | 29083 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 916 |
| fps | 508 |
| time_elapsed | 57 |
| total_timesteps | 29312 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.356 |
| n_updates | 29211 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 920 |
| fps | 507 |
| time_elapsed | 57 |
| total_timesteps | 29440 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.343 |
| n_updates | 29339 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 924 |
| fps | 507 |
| time_elapsed | 58 |
| total_timesteps | 29568 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.208 |
| n_updates | 29467 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 928 |
| fps | 507 |
| time_elapsed | 58 |
| total_timesteps | 29696 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.305 |
| n_updates | 29595 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 932 |
| fps | 507 |
| time_elapsed | 58 |
| total_timesteps | 29824 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.323 |
| n_updates | 29723 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 936 |
| fps | 507 |
| time_elapsed | 59 |
| total_timesteps | 29952 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.397 |
| n_updates | 29851 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 940 |
| fps | 507 |
| time_elapsed | 59 |
| total_timesteps | 30080 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.506 |
| n_updates | 29979 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 944 |
| fps | 507 |
| time_elapsed | 59 |
| total_timesteps | 30208 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.308 |
| n_updates | 30107 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 948 |
| fps | 507 |
| time_elapsed | 59 |
| total_timesteps | 30336 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.351 |
| n_updates | 30235 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 952 |
| fps | 507 |
| time_elapsed | 59 |
| total_timesteps | 30464 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.192 |
| n_updates | 30363 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.8 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 956 |
| fps | 508 |
| time_elapsed | 60 |
| total_timesteps | 30592 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.179 |
| n_updates | 30491 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 960 |
| fps | 508 |
| time_elapsed | 60 |
| total_timesteps | 30720 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.192 |
| n_updates | 30619 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 964 |
| fps | 507 |
| time_elapsed | 60 |
| total_timesteps | 30848 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.273 |
| n_updates | 30747 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 968 |
| fps | 506 |
| time_elapsed | 61 |
| total_timesteps | 30976 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.176 |
| n_updates | 30875 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 972 |
| fps | 505 |
| time_elapsed | 61 |
| total_timesteps | 31104 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.217 |
| n_updates | 31003 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 976 |
| fps | 504 |
| time_elapsed | 61 |
| total_timesteps | 31232 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.267 |
| n_updates | 31131 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.5 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 980 |
| fps | 504 |
| time_elapsed | 62 |
| total_timesteps | 31360 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.212 |
| n_updates | 31259 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 984 |
| fps | 504 |
| time_elapsed | 62 |
| total_timesteps | 31488 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.247 |
| n_updates | 31387 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.5 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 988 |
| fps | 503 |
| time_elapsed | 62 |
| total_timesteps | 31616 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.336 |
| n_updates | 31515 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 992 |
| fps | 504 |
| time_elapsed | 62 |
| total_timesteps | 31744 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.411 |
| n_updates | 31643 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.6 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 996 |
| fps | 503 |
| time_elapsed | 63 |
| total_timesteps | 31872 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.327 |
| n_updates | 31771 |
----------------------------------
----------------------------------
| rollout/ | |
| ep_len_mean | 32 |
| ep_rew_mean | 21.7 |
| exploration_rate | 0.5 |
| time/ | |
| episodes | 1000 |
| fps | 504 |
| time_elapsed | 63 |
| total_timesteps | 32000 |
| train/ | |
| learning_rate | 0.0001 |
| loss | 0.19 |
| n_updates | 31899 |
----------------------------------
✅ Training complete.
Plot agent’s result
plot_training_results(log_dir, "DQN Training on N-Back Task")
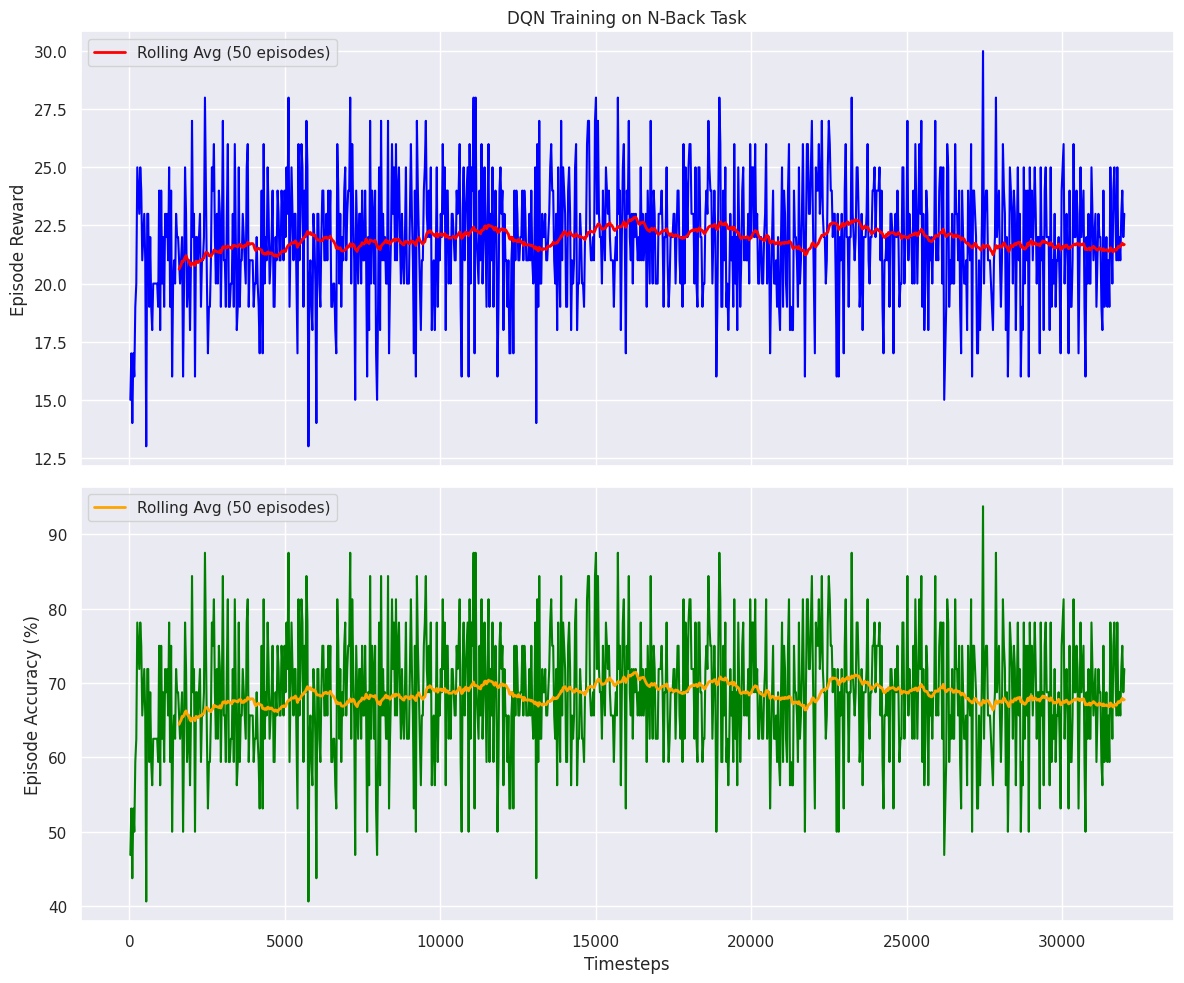
Inspect logs as dataframe
log_file_path = os.path.join(log_dir, "monitor.csv")
if os.path.exists(log_file_path):
logs_df = pd.read_csv(log_file_path, skiprows=1) # Skip the header row
print("\n--- Training Logs (last 5 episodes) ---")
print(logs_df.tail())
else:
print("\nCould not find the monitor log file.")
--- Training Logs (last 5 episodes) ---
r l t
995 21.0 32 73.091478
996 23.0 32 73.160453
997 24.0 32 73.219404
998 22.0 32 73.273850
999 23.0 32 73.332403