{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {},
"id": "view-in-github"
},
"source": [
"
 "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 1: Un/Self-supervised learning methods\n",
"\n",
"**Week 3, Day 3: Unsupervised and self-supervised learning**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"__Content creators:__ Arna Ghosh, Colleen Gillon, Tim Lillicrap, Blake Richards\n",
"\n",
"__Content reviewers:__ Atnafu Lambebo, Hadi Vafaei, Khalid Almubarak, Melvin Selim Atay, Kelson Shilling-Scrivo\n",
"\n",
"__Content editors:__ Anoop Kulkarni, Spiros Chavlis\n",
"\n",
"__Production editors:__ Deepak Raya, Gagana B, Spiros Chavlis"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Tutorial Objectives\n",
"\n",
"In this tutorial, you will learn about the importance of learning good representations of data.\n",
"\n",
"Specific objectives for this tutorial:\n",
"* Train logistic regressions (A) directly on input data and (B) on representations learned from the data.\n",
"* Compare the classification performances achieved by the different networks.\n",
"* Compare the representations learned by the different networks.\n",
"* Identify the advantages of self-supervised learning over supervised or traditional unsupervised methods."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @markdown\n",
"from IPython.display import IFrame\n",
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/wvt34/\")\n",
" display(IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/wvt34/?direct%26mode=render%26action=download%26mode=render\", width=730, height=410))\n",
"display(out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Setup"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install dependencies\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install dependencies\n",
"\n",
"# @markdown Download dataset, modules, and files needed for the tutorial from GitHub.\n",
"\n",
"# @markdown This cell will download the library from OSF, but you can check out the code in https://github.com/colleenjg/neuromatch_ssl_tutorial.git\n",
"\n",
"import os, sys, shutil, importlib\n",
"\n",
"REPO_PATH = \"neuromatch_ssl_tutorial\"\n",
"download_str = \"Downloading\"\n",
"if os.path.exists(REPO_PATH):\n",
" download_str = \"Redownloading\"\n",
" shutil.rmtree(REPO_PATH)\n",
"\n",
"# Download from github repo directly\n",
"# !git clone git://github.com/colleenjg/neuromatch_ssl_tutorial.git --quiet\n",
"\n",
"from io import BytesIO\n",
"from urllib.request import urlopen\n",
"from zipfile import ZipFile\n",
"\n",
"zipurl = 'https://osf.io/smqvg/download'\n",
"print(f\"{download_str} and unzipping the file... Please wait.\")\n",
"with urlopen(zipurl) as zipresp:\n",
" with ZipFile(BytesIO(zipresp.read())) as zfile:\n",
" zfile.extractall()\n",
"print(\"Download completed!\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and import feedback gadget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install and import feedback gadget\n",
"\n",
"!pip3 install vibecheck datatops --quiet\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
" return DatatopsContentReviewContainer(\n",
" \"\", # No text prompt\n",
" notebook_section,\n",
" {\n",
" \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
" \"name\": \"neuromatch_dl\",\n",
" \"user_key\": \"f379rz8y\",\n",
" },\n",
" ).render()\n",
"\n",
"\n",
"feedback_prefix = \"W3D3_T1\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Imports\n",
"import torch\n",
"import torchvision\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"\n",
"# Import modules designed for use in this notebook.\n",
"from neuromatch_ssl_tutorial.modules import data, load, models, plot_util\n",
"from neuromatch_ssl_tutorial.modules import data, load, models, plot_util\n",
"importlib.reload(data)\n",
"importlib.reload(load)\n",
"importlib.reload(models)\n",
"importlib.reload(plot_util)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure settings\n",
"import logging\n",
"logging.getLogger('matplotlib.font_manager').disabled = True\n",
"\n",
"import ipywidgets as widgets # Interactive display\n",
"%matplotlib inline\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/content-creation/main/nma.mplstyle\")\n",
"\n",
"plt.rc('axes', unicode_minus=False) # To ensure negatives render correctly with xkcd style\n",
"import warnings\n",
"warnings.filterwarnings(\"ignore\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Plotting functions\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Function to plot a histogram of RSM values: `plot_rsm_histogram(rsms, colors)`\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Plotting functions\n",
"\n",
"# @markdown Function to plot a histogram of RSM values: `plot_rsm_histogram(rsms, colors)`\n",
"def plot_rsm_histogram(rsms, colors, labels=None, nbins=100):\n",
" \"\"\"\n",
" Function to plot histogram based on Representational Similarity Matrices\n",
"\n",
" Args:\n",
" rsms: List\n",
" List of values within RSM\n",
" colors: List\n",
" List of colors for histogram\n",
" labels: List\n",
" List of RSM Labels\n",
" nbins: Integer\n",
" Specifies number of histogram bins\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" fig, ax = plt.subplots(1)\n",
" ax.set_title(\"Histogram of RSM values\", y=1.05)\n",
"\n",
" min_val = np.min([np.nanmin(rsm) for rsm in rsms])\n",
" max_val = np.max([np.nanmax(rsm) for rsm in rsms])\n",
"\n",
" bins = np.linspace(min_val, max_val, nbins+1)\n",
"\n",
" if labels is None:\n",
" labels = [labels] * len(rsms)\n",
" elif len(labels) != len(rsms):\n",
" raise ValueError(\"If providing labels, must provide as many as RSMs.\")\n",
"\n",
" if len(rsms) != len(colors):\n",
" raise ValueError(\"Must provide as many colors as RSMs.\")\n",
"\n",
" for r, rsm in enumerate(rsms):\n",
" ax.hist(\n",
" rsm.reshape(-1), bins, density=True, alpha=0.4,\n",
" color=colors[r], label=labels[r]\n",
" )\n",
" ax.axvline(x=0, ls=\"dashed\", alpha=0.6, color=\"k\")\n",
" ax.set_ylabel(\"Density\")\n",
" ax.set_xlabel(\"Similarity values\")\n",
" ax.legend()\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Helper functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Helper functions\n",
"\n",
"from IPython.display import display, Image # to visualize images\n",
"\n",
"# @markdown Function to set test custom torch RSM function: `test_custom_torch_RSM_fct()`\n",
"def test_custom_torch_RSM_fct(custom_torch_RSM_fct):\n",
" \"\"\"\n",
" Function to set test implementation of custom_torch_RSM_fct\n",
"\n",
" Args:\n",
" custom_torch_RSM_fct: f_name\n",
" Function to test\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" rand_feats = torch.rand(100, 1000)\n",
" RSM_custom = custom_torch_RSM_fct(rand_feats)\n",
" RSM_ground_truth = data.calculate_torch_RSM(rand_feats)\n",
"\n",
" if torch.allclose(RSM_custom, RSM_ground_truth, equal_nan=True):\n",
" print(\"custom_torch_RSM_fct() is correctly implemented.\")\n",
" else:\n",
" print(\"custom_torch_RSM_fct() is NOT correctly implemented.\")\n",
"\n",
"\n",
"# @markdown Function to set test custom contrastive loss function: `test_custom_contrastive_loss_fct()`\n",
"def test_custom_contrastive_loss_fct(custom_simclr_contrastive_loss):\n",
" \"\"\"\n",
" Function to set test implementation of custom_simclr_contrastive_loss\n",
"\n",
" Args:\n",
" custom_simclr_contrastive_loss: f_name\n",
" Function to test\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" rand_proj_feat1 = torch.rand(100, 1000)\n",
" rand_proj_feat2 = torch.rand(100, 1000)\n",
" loss_custom = custom_simclr_contrastive_loss(rand_proj_feat1, rand_proj_feat2)\n",
" loss_ground_truth = models.contrastive_loss(rand_proj_feat1,rand_proj_feat2)\n",
"\n",
" if torch.allclose(loss_custom, loss_ground_truth):\n",
" print(\"custom_simclr_contrastive_loss() is correctly implemented.\")\n",
" else:\n",
" print(\"custom_simclr_contrastive_loss() is NOT correctly implemented.\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Set random seed\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Executing `set_seed(seed=seed)` you are setting the seed\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Set random seed\n",
"\n",
"# @markdown Executing `set_seed(seed=seed)` you are setting the seed\n",
"\n",
"# For DL its critical to set the random seed so that students can have a\n",
"# baseline to compare their results to expected results.\n",
"# Read more here: https://pytorch.org/docs/stable/notes/randomness.html\n",
"\n",
"# Call `set_seed` function in the exercises to ensure reproducibility.\n",
"import random\n",
"import torch\n",
"\n",
"def set_seed(seed=None, seed_torch=True):\n",
" \"\"\"\n",
" Handles variability by controlling sources of randomness\n",
" through set seed values\n",
"\n",
" Args:\n",
" seed: Integer\n",
" Set the seed value to given integer.\n",
" If no seed, set seed value to random integer in the range 2^32\n",
" seed_torch: Bool\n",
" Seeds the random number generator for all devices to\n",
" offer some guarantees on reproducibility\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" if seed is None:\n",
" seed = np.random.choice(2 ** 32)\n",
" random.seed(seed)\n",
" np.random.seed(seed)\n",
" if seed_torch:\n",
" torch.manual_seed(seed)\n",
" torch.cuda.manual_seed_all(seed)\n",
" torch.cuda.manual_seed(seed)\n",
" torch.backends.cudnn.benchmark = False\n",
" torch.backends.cudnn.deterministic = True\n",
"\n",
" print(f'Random seed {seed} has been set.')\n",
"\n",
"\n",
"# In case that `DataLoader` is used\n",
"def seed_worker(worker_id):\n",
" \"\"\"\n",
" DataLoader will reseed workers following randomness in\n",
" multi-process data loading algorithm.\n",
"\n",
" Args:\n",
" worker_id: integer\n",
" ID of subprocess to seed. 0 means that\n",
" the data will be loaded in the main process\n",
" Refer: https://pytorch.org/docs/stable/data.html#data-loading-randomness for more details\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" worker_seed = torch.initial_seed() % 2**32\n",
" np.random.seed(worker_seed)\n",
" random.seed(worker_seed)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Set device (GPU or CPU). Execute `set_device()`\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Set device (GPU or CPU). Execute `set_device()`\n",
"# especially if torch modules used.\n",
"\n",
"# Inform the user if the notebook uses GPU or CPU.\n",
"\n",
"def set_device():\n",
" \"\"\"\n",
" Set the device. CUDA if available, CPU otherwise\n",
"\n",
" Args:\n",
" None\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
" if device != \"cuda\":\n",
" print(\"WARNING: For this notebook to perform best, \"\n",
" \"if possible, in the menu under `Runtime` -> \"\n",
" \"`Change runtime type.` select `GPU` \")\n",
" else:\n",
" print(\"GPU is enabled in this notebook.\")\n",
"\n",
" return device"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Set global variables\n",
"SEED = 2021\n",
"set_seed(seed=SEED)\n",
"DEVICE = set_device()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" ### Pre-load variables (allows each section to be run independently)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown ### Pre-load variables (allows each section to be run independently)\n",
"\n",
"# Section 1\n",
"dSprites = data.dSpritesDataset(\n",
" os.path.join(REPO_PATH, \"dsprites\", \"dsprites_subset.npz\")\n",
" )\n",
"\n",
"dSprites_torchdataset = data.dSpritesTorchDataset(\n",
" dSprites,\n",
" target_latent=\"shape\"\n",
" )\n",
"\n",
"train_sampler, test_sampler = data.train_test_split_idx(\n",
" dSprites_torchdataset,\n",
" fraction_train=0.8,\n",
" randst=SEED\n",
" )\n",
"\n",
"supervised_encoder = load.load_encoder(REPO_PATH,\n",
" model_type=\"supervised\",\n",
" verbose=False)\n",
"\n",
"# Section 2\n",
"custom_torch_RSM_fct = None # Default is used instead\n",
"\n",
"# Section 3\n",
"random_encoder = load.load_encoder(REPO_PATH,\n",
" model_type=\"random\",\n",
" verbose=False)\n",
"\n",
"# Section 4\n",
"vae_encoder = load.load_encoder(REPO_PATH,\n",
" model_type=\"vae\",\n",
" verbose=False)\n",
"\n",
"# Section 5\n",
"invariance_transforms = torchvision.transforms.RandomAffine(\n",
" degrees=90,\n",
" translate=(0.2, 0.2),\n",
" scale=(0.8, 1.2)\n",
" )\n",
"dSprites_invariance_torchdataset = data.dSpritesTorchDataset(\n",
" dSprites,\n",
" target_latent=\"shape\",\n",
" simclr=True,\n",
" simclr_transforms=invariance_transforms\n",
" )\n",
"\n",
"# Section 6\n",
"simclr_encoder = load.load_encoder(REPO_PATH,\n",
" model_type=\"simclr\",\n",
" verbose=False)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 0: Introduction"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 0: Introduction\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 0: Introduction\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'Q3b_EqFUI00'), ('Bilibili', 'BV1D64y1s78e')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Introduction_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 1: Representations are important\n",
"\n",
"*Time estimate: ~30mins*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 1: Why do representations matter?\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Why do representations matter?\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'lj5uTUo6W88'), ('Bilibili', 'BV1g54y1J7cE')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Why_do_representations_matter_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 1.1: Introducing the dSprites dataset"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In this tutorial, we will be using a subset of the openly available **dSprites dataset** to investigate the importance of learning good representations.\n",
"\n",
"_**Note on dataset:** For convenience, we will be using a subset of the original, full dataset which is available [here](https://github.com/deepmind/dsprites-dataset/), on GitHub._"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 1.1.1: Exploring the dSprites dataset\n",
"\n",
"In this first demo, we will get to know the **dSprites dataset**. This dataset is made up of black and white images (20,000 images total in the subset we are using).\n",
"\n",
"The images in the dataset can be described using different combinations of **latent dimension values**, sampled from:\n",
"- **Shapes (3):** square (1.0), oval (2.0) or heart (3.0)\n",
"- **Scales (6):** 0.5 to 1.0\n",
"- **Orientations (40):** 0 to 2$\\pi$\n",
"- **Positions in X (32):** 0 to 1 (left to right)\n",
"- **Positions in Y (32):** 0 to 1 (top to bottom)\n",
"\n",
"As a result, **each image carries 5 labels.** One for each of the latent dimensions.\n",
"\n",
"We will first load the dataset into the `dSprites` object, which is an instance of the `data.dSpritesDataset` class."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"dSprites = data.dSpritesDataset(\n",
" os.path.join(REPO_PATH, \"dsprites\", \"dsprites_subset.npz\")\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Next, we use the `dSpritesDataset` class method `show_images()` to plot a few images from the dataset, with their latent dimension values printed below.\n",
"\n",
"**Interactive Demo:** View a different set of randomly sampled images by passing the random state argument `randst` any integer or the value `None`. (The original setting is `randst=SEED`.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# DEMO: To view different images, set randst to any integer value.\n",
"dSprites.show_images(num_images=10, randst=SEED)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"To better understand the `posX` and `posY` latent dimensions (which will be most relevant in **Bonus 2**), we plot the images with some annotations. The annotations (in red) do not modify the actual images; they are added **purely for visualization purposes**, and show:\n",
" - the **edges** of the `posX` and `posY` spans, and\n",
" - the **center**, i.e., `(posX, posY)`, for each shape.\n",
"\n",
"_**Note on shape positions:** Notice that all shape centers are positioned **within the area marked by the red square**. `posX` and `posY` actually describe the relative position of the center of a shape within this area: `posX=0` (left) to `posX=1` (right), and `posY=0` (top) to `posY=1` (bottom). No shape center appears outside, in the buffer area. This choice in the dSprites dataset design ensures that shapes of different scales and rotations **all appear fully**._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# DEMO: To view different images, set randst to any integer value.\n",
"dSprites.show_images(num_images=10, randst=SEED, annotations=\"pos\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 1.2: Training a classifier with and without representations"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Now, we will investigate how 2 different types of classifiers perform when trained to decode the shape latent dimension of images in the **dSprites dataset**.\n",
"\n",
"Specifically, we will train **one classifier directly on the images**, and **another on the output of an encoder network**.\n",
"\n",
"The **encoder network** we will use here and throughout the tutorial is the multi-layer convolutional network, pictured below. It comprises 2 consecutive convolutional layers, followed by 3 fully connected layers, and uses average pooling and batch normalization between layers, as well as rectified linear units as non-linearities.\n",
"\n",
"The **classifier layer** then takes the encoder features as input, predicting, for example, the shape latent dimension of encoded input images.\n",
"\n",
"_**Note on terminology:** In this tutorial, both the terms **representations** and **features** are used to refer to the data embeddings learned in the final layer of the encoder network (of dimension 1x84, and indicated by a red dashed box) which are fed to the classifiers._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" ### Encoder network schematic\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown ### Encoder network schematic\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"feat_encoder_schematic.png\"), width=1200)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The following code:\n",
"* Seeds modules that will use random processes, to ensure the results are consistently reproducible, using the `seed_processes()` function,\n",
"* Collects the dSprites dataset into a torch dataset using the `data.dSpritesTorchDataset` class,\n",
"* Initializes a training and a test sampler to keep the two datasets separate using the `data.train_test_splix_idx()` function."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Set the seed before building any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"# Initialize a torch dataset, specifying the target latent dimension for\n",
"# the classifier\n",
"dSprites_torchdataset = data.dSpritesTorchDataset(\n",
" dSprites,\n",
" target_latent=\"shape\"\n",
" )\n",
"\n",
"# Initialize a train_sampler and a test_sampler to keep the two sets\n",
"# consistently separate\n",
"train_sampler, test_sampler = data.train_test_split_idx(\n",
" dSprites_torchdataset,\n",
" fraction_train=0.8, # 80:20 data split\n",
" randst=SEED\n",
" )\n",
"\n",
"print(f\"Dataset size: {len(train_sampler)} training, \"\n",
" f\"{len(test_sampler)} test images\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 1.2.1: Training a logistic regression classifier directly on images\n",
"\n",
"The following code:\n",
"* trains a logistic regression directly on the training set images to classify their shape, and assesses its performance on the test set images using the `models.train_classifier()` function.\n",
"\n",
"_**Interactive Demo:** Try a few different `num_epochs` settings to see whether performance improves with more training, e.g., between 1 and 50 epochs. (The original setting is `num_epochs=25`)._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_What_models_Video\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"num_epochs = 25 # DEMO: Try different numbers of training epochs\n",
"\n",
"# Train a classifier directly on the images\n",
"print(\"Training a classifier directly on the images...\")\n",
"_ = models.train_classifier(\n",
" encoder=None,\n",
" dataset=dSprites_torchdataset,\n",
" train_sampler=train_sampler,\n",
" test_sampler=test_sampler,\n",
" freeze_features=True, # There is no feature encoder to train here, anyway\n",
" num_epochs=num_epochs,\n",
" verbose=True # Print results\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As we can observe, the classifier trained directly on the images performs only a bit above chance (39.55%) on the test set, after 25 training epochs."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Shape classification results using different feature encoders:\n",
"\n",
"| _Chance_ | | None (raw data) |\n",
"| - | - | --- |\n",
"| _33.33%_ | | 39.55% |"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 1.2.1: Training a logistic regression classifier along with an encoder\n",
"\n",
"The following code:\n",
"* Uses the same dSprites torch dataset (`dSprites_torchdataset`) initialized above, as well as the training and test samplers (`train_sampler`, `test_sampler`),\n",
"* Again, seed modules for substructures that use random processes, to ensure the results are consistently reproducible,\n",
"* Initializes an encoder network to use in the supervised network using the `models.EncoderCore` class,\n",
"* Sets a proposed number of epochs to use when training the classifier and encoder (`num_epochs=10`).\n",
"\n",
"**Exercise:** Train a classifier, along with the encoder, to classify the input images according to shape, using `models.train_classifier()`. How does it perform?\n",
"\n",
"**Hints**:\n",
"- `models.train_classifier()`:\n",
" - Is introduced in **Interactive Demo 1.2.1**.\n",
" - Takes `freeze_features` as an input argument:\n",
" - If set to `True`, the encoder is frozen, and so only the classifier layer is trained.\n",
" - If set to `False`, the encoder is **not** frozen, and is trained along with the classifier layer."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def train_supervised_encoder(num_epochs, seed):\n",
" \"\"\"\n",
" Helper function to train the encoder in a supervised way\n",
"\n",
" Args:\n",
" num_epochs: Integer\n",
" Number of epochs the supervised encoder is to be trained for\n",
" seed: Integer\n",
" The seed value for the dataset/network\n",
"\n",
" Returns:\n",
" supervised_encoder: nn.module\n",
" The trained encoder with mentioned parameters/hyperparameters\n",
" \"\"\"\n",
" # Call this before any dataset/network initializing or training,\n",
" # to ensure reproducibility\n",
" set_seed(seed)\n",
"\n",
" # Initialize a core encoder network on which the classifier will be added\n",
" supervised_encoder = models.EncoderCore()\n",
"\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your implementation\n",
" raise NotImplementedError(\"Exercise: Train a supervised encoder and classifier.\")\n",
" #################################################\n",
" # Train an encoder and classifier on the images, using models.train_classifier()\n",
" print(\"Training a supervised encoder and classifier...\")\n",
" _ = models.train_classifier(\n",
" encoder=...,\n",
" dataset=...,\n",
" train_sampler=...,\n",
" test_sampler=...,\n",
" freeze_features=...,\n",
" num_epochs=num_epochs,\n",
" verbose=... # print results\n",
" )\n",
"\n",
" return supervised_encoder\n",
"\n",
"\n",
"\n",
"num_epochs = 10 # Proposed number of training epochs\n",
"## Uncomment below to test your function\n",
"# supervised_encoder = train_supervised_encoder(num_epochs=num_epochs, seed=SEED)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"Network performance after 10 encoder and classifier training epochs (chance: 33.33%):\n",
" Training accuracy: 100.00%\n",
" Testing accuracy: 98.70%\n",
"````"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_d96280b7.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Logistic_regression_classifier_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"When the classifier is trained with an encoder network, however, it achieves very high classification accuracy (~98.70%) on the test set, after only 10 training epochs."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Shape classification results using different feature encoders:\n",
"\n",
"| _Chance_ | | None (raw data) | Supervised |\n",
"| - | - | --- | --- |\n",
"| _33.33%_ | | 39.55% | 98.70% |"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 2: Supervised learning induces invariant representations\n",
"\n",
"*Time estimate: ~20mins*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 2: Supervised Learning and Invariance\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 2: Supervised Learning and Invariance\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'ZQka4k8ZOs0'), ('Bilibili', 'BV1d54y1E76W')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Supervised_learning_and_invariance_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 2.1: Examining Representational Similarity Matrices (RSMs)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"To examine the representations learned by the encoder network, we use **Representational Similarity Matrices (RSMs)**. In these matrices, the similarity between the encoder's representations of each possible pair of images is plotted to reveal overall structure in representation space.\n",
"\n",
"_**Note on cosine similarity:** Here, we use cosine similarity as a measure of representational similarity. Cosine similarity measures the angle between 2 vectors, and can be thought of as their normalized dot product._"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 2.1.1: Complete a function that calculates RSMs\n",
"\n",
"The following code:\n",
"* Lays out the skeleton of a function `custom_torch_RSM_fct()` which calculates an RSM from features,\n",
"* Tests the custom function against the solution implementation.\n",
"\n",
"**Exercise:** Complete the `custom_torch_RSM_fct()` implementation.\n",
"\n",
"**Hints**:\n",
"- `custom_torch_RSM_fct()`:\n",
" - Takes 1 input argument:\n",
" - `features` (2D torch Tensor): Feature matrix (nbr items x nbr features)\n",
" - Returns 1 output:\n",
" - `rsm` (2D torch Tensor): Similarity matrix (nbr items x nbr items)\n",
" - Uses `torch.nn.functional.cosine_similarity()`.\n",
"- `torch.nn.functional.cosine_similarity()`:\n",
" - Takes 3 arguments, in order:\n",
" - `x1` (torch Tensor),\n",
" - `x2` (torch Tensor),\n",
" - `dim` (int)\n",
" - Returns the similarity between `x1` and `x2` along dimension `dim`.\n",
"\n",
"**Detailed hint**:\n",
"- To use `torch.nn.functional.cosine_similarity()` to measure the similarity of `features` to **itself** for each possible **pair of items**:\n",
" - Pass 2 versions of `features` as `x1` and `x2`, respectively.\n",
" - Ensure that for `x1` and `x2`, the **features dimension is at the same position** , and specify that dimension with `dim`.\n",
" - To obtain the similarity between each possible pair of items, ensure that for `x1` and `x2`, the **items dimensions are orthogonal** to one another (i.e., at different positions).\n",
" - Don't forget that to achieve this, singleton dimensions (i.e., dimensions of length 1) can be used."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def custom_torch_RSM_fct(features):\n",
" \"\"\"\n",
" Custom function to calculate representational similarity matrix (RSM) of a feature\n",
" matrix using pairwise cosine similarity.\n",
"\n",
" Args:\n",
" features: 2D torch.Tensor\n",
" Feature matrix of size (nbr items x nbr features)\n",
"\n",
" Returns:\n",
" rsm: 2D torch.Tensor\n",
" Similarity matrix of size (nbr items x nbr items)\n",
" \"\"\"\n",
"\n",
" num_items, num_features = features.shape\n",
"\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # Complete the function below given the specific guidelines.\n",
" # Use torch.nn.functional.cosine_similarity()\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Exercise: Implement RSM calculation.\")\n",
" #################################################\n",
" # EXERCISE: Implement RSM calculation\n",
" rsm = ...\n",
"\n",
" if not rsm.shape == (num_items, num_items):\n",
" raise ValueError(f\"RSM should be of shape ({num_items}, {num_items})\")\n",
"\n",
" return rsm\n",
"\n",
"\n",
"\n",
"## Test implementation by comparing output to solution implementation\n",
"# test_custom_torch_RSM_fct(custom_torch_RSM_fct)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"custom_torch_RSM_fct() is correctly implemented.\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_2752aa1a.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Function_that_calculates_RSMs_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 2.1.1: Plotting the supervised network encoder RSM along different latent dimensions\n",
"\n",
"In this demo, we calculate an RSM for representations of the test set images generated by the supervised network encoder.\n",
"\n",
"The following code:\n",
"* Calculates and plots the RSM for the test set, with rows and columns sorted by whichever latent dimension is specified (e.g., `sorting_latent=\"shape\"`) using `models.plot_model_RSMs()`.\n",
"\n",
"**Interactive Demo:** In the current example, the rows and columns of the RSM are organized along the `shape` latent dimension. Try organizing them along one of the other latent dimensions (`\"scale\"`, `\"orientation\"`, `\"posX\"` or `\"posY\"`) to see whether different patterns emerge. (The original setting is `sorting_latent=\"shape\"`.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"sorting_latent = \"shape\" # DEMO: Try sorting by different latent dimensions\n",
"print(\"Plotting RSMs...\")\n",
"_ = models.plot_model_RSMs(\n",
" encoders=[supervised_encoder], # We pass the trained supervised_encoder\n",
" dataset=dSprites_torchdataset,\n",
" sampler=test_sampler, # We want to see the representations on the held out test set\n",
" titles=[\"Supervised network encoder RSM\"], # Plot title\n",
" sorting_latent=sorting_latent,\n",
" RSM_fct=custom_torch_RSM_fct\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Supervised_network_encoder_RSM_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 2.1.1: What patterns do the RSMs reveal about how the encoder represents different images?\n",
"**A.** What does the yellow (maximal similarity color) diagonal, going from the top left to the bottom right, correspond to?\n",
"**B.** What pattern can be observed when comparing RSM values for pairs of images that share a similar latent value (e.g., 2 heart images) vs pairs of images that do not (e.g., a heart and a square image)?\n",
"**C.** Do some shapes appear to be encoded more similarly than others?\n",
"**D.** Do some latent dimensions show clearer RSM patterns than others? Why might that be so?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" #### Supporting images for Discussion response examples for 2.1.1\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown #### Supporting images for Discussion response examples for 2.1.1\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"rsms_supervised_encoder_10ep_bs1000_seed2021.png\"), width=1200)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_50b74052.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_What_patterns_do_the_RSMs_reveal_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 3: Random projections don’t work as well\n",
"\n",
"*Time estimate: ~20mins*\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 3: Random Representations\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 3: Random Representations\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'LVM7Fm5T6Fs'), ('Bilibili', 'BV1Jf4y15789')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Random_representations_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.1: Examining RSMs of a random encoder"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"To determine whether the patterns observed in the RSMs of the supervised network encoder are trivial, we investigate whether they also emerge from the **random projections of an untrained encoder**."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 3.1.1: Plotting a random network encoder RSM along different latent dimensions\n",
"\n",
"In this exercise, we repeat the same analysis as in **Section 2.1**, but with a random encoder.\n",
"\n",
"The following code:\n",
"* Initializes an encoder network to use in the random network using the `models.EncoderCore` class,\n",
"* Proposes a latent dimension along which to sort the rows and columns (`sorting_latent=\"shape\"`).\n",
"\n",
"**Exercise:**\n",
"* Visualize the RSMs for the supervised and random network encoders, using `models.plot_model_RSMs()`.\n",
"* Visualize the RSMs, organized along different latent dimensions (`\"scale\"`, `\"orientation\"`, `\"posX\"` or `\"posY\"`), and compare the patterns observed for the supervised versus the random encoder network.\n",
"\n",
"**Hint**: `models.plot_model_RSMs()` is introduced in **Interactive Demo 2.1.1**."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def plot_rsms(seed):\n",
" \"\"\"\n",
" Helper function to plot Representational Similarity Matrices (RSMs)\n",
"\n",
" Args:\n",
" seed: Integer\n",
" The seed value for the dataset/network\n",
"\n",
" Returns:\n",
" random_encoder: nn.module\n",
" The encoder with mentioned parameters/hyperparameters\n",
" \"\"\"\n",
" # Call this before any dataset/network initializing or training,\n",
" # to ensure reproducibility\n",
" set_seed(seed)\n",
"\n",
" # Initialize a core encoder network that will not get trained\n",
" random_encoder = models.EncoderCore()\n",
"\n",
" # Try sorting by different latent dimensions\n",
" sorting_latent = \"shape\"\n",
"\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your implementation\n",
" raise NotImplementedError(\"Exercise: Plot RSMs.\")\n",
" #################################################\n",
" # Plot RSMs\n",
" print(\"Plotting RSMs...\")\n",
" _ = models.plot_model_RSMs(\n",
" encoders=[..., ...], # Pass both encoders\n",
" dataset=...,\n",
" sampler=..., # To see the representations on the held out test set\n",
" titles=[\"Supervised network encoder RSM\",\n",
" \"Random network encoder RSM\"], # Plot titles\n",
" sorting_latent=sorting_latent,\n",
" )\n",
"\n",
" return random_encoder\n",
"\n",
"\n",
"\n",
"## Uncomment below to test your function\n",
"# random_encoder = plot_rsms(seed=SEED)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_f066182b.py)\n",
"\n",
"*Example output:*\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 1: Un/Self-supervised learning methods\n",
"\n",
"**Week 3, Day 3: Unsupervised and self-supervised learning**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"__Content creators:__ Arna Ghosh, Colleen Gillon, Tim Lillicrap, Blake Richards\n",
"\n",
"__Content reviewers:__ Atnafu Lambebo, Hadi Vafaei, Khalid Almubarak, Melvin Selim Atay, Kelson Shilling-Scrivo\n",
"\n",
"__Content editors:__ Anoop Kulkarni, Spiros Chavlis\n",
"\n",
"__Production editors:__ Deepak Raya, Gagana B, Spiros Chavlis"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Tutorial Objectives\n",
"\n",
"In this tutorial, you will learn about the importance of learning good representations of data.\n",
"\n",
"Specific objectives for this tutorial:\n",
"* Train logistic regressions (A) directly on input data and (B) on representations learned from the data.\n",
"* Compare the classification performances achieved by the different networks.\n",
"* Compare the representations learned by the different networks.\n",
"* Identify the advantages of self-supervised learning over supervised or traditional unsupervised methods."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @markdown\n",
"from IPython.display import IFrame\n",
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/wvt34/\")\n",
" display(IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/wvt34/?direct%26mode=render%26action=download%26mode=render\", width=730, height=410))\n",
"display(out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Setup"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install dependencies\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install dependencies\n",
"\n",
"# @markdown Download dataset, modules, and files needed for the tutorial from GitHub.\n",
"\n",
"# @markdown This cell will download the library from OSF, but you can check out the code in https://github.com/colleenjg/neuromatch_ssl_tutorial.git\n",
"\n",
"import os, sys, shutil, importlib\n",
"\n",
"REPO_PATH = \"neuromatch_ssl_tutorial\"\n",
"download_str = \"Downloading\"\n",
"if os.path.exists(REPO_PATH):\n",
" download_str = \"Redownloading\"\n",
" shutil.rmtree(REPO_PATH)\n",
"\n",
"# Download from github repo directly\n",
"# !git clone git://github.com/colleenjg/neuromatch_ssl_tutorial.git --quiet\n",
"\n",
"from io import BytesIO\n",
"from urllib.request import urlopen\n",
"from zipfile import ZipFile\n",
"\n",
"zipurl = 'https://osf.io/smqvg/download'\n",
"print(f\"{download_str} and unzipping the file... Please wait.\")\n",
"with urlopen(zipurl) as zipresp:\n",
" with ZipFile(BytesIO(zipresp.read())) as zfile:\n",
" zfile.extractall()\n",
"print(\"Download completed!\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and import feedback gadget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install and import feedback gadget\n",
"\n",
"!pip3 install vibecheck datatops --quiet\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
" return DatatopsContentReviewContainer(\n",
" \"\", # No text prompt\n",
" notebook_section,\n",
" {\n",
" \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
" \"name\": \"neuromatch_dl\",\n",
" \"user_key\": \"f379rz8y\",\n",
" },\n",
" ).render()\n",
"\n",
"\n",
"feedback_prefix = \"W3D3_T1\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Imports\n",
"import torch\n",
"import torchvision\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"\n",
"# Import modules designed for use in this notebook.\n",
"from neuromatch_ssl_tutorial.modules import data, load, models, plot_util\n",
"from neuromatch_ssl_tutorial.modules import data, load, models, plot_util\n",
"importlib.reload(data)\n",
"importlib.reload(load)\n",
"importlib.reload(models)\n",
"importlib.reload(plot_util)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure settings\n",
"import logging\n",
"logging.getLogger('matplotlib.font_manager').disabled = True\n",
"\n",
"import ipywidgets as widgets # Interactive display\n",
"%matplotlib inline\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/content-creation/main/nma.mplstyle\")\n",
"\n",
"plt.rc('axes', unicode_minus=False) # To ensure negatives render correctly with xkcd style\n",
"import warnings\n",
"warnings.filterwarnings(\"ignore\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Plotting functions\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Function to plot a histogram of RSM values: `plot_rsm_histogram(rsms, colors)`\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Plotting functions\n",
"\n",
"# @markdown Function to plot a histogram of RSM values: `plot_rsm_histogram(rsms, colors)`\n",
"def plot_rsm_histogram(rsms, colors, labels=None, nbins=100):\n",
" \"\"\"\n",
" Function to plot histogram based on Representational Similarity Matrices\n",
"\n",
" Args:\n",
" rsms: List\n",
" List of values within RSM\n",
" colors: List\n",
" List of colors for histogram\n",
" labels: List\n",
" List of RSM Labels\n",
" nbins: Integer\n",
" Specifies number of histogram bins\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" fig, ax = plt.subplots(1)\n",
" ax.set_title(\"Histogram of RSM values\", y=1.05)\n",
"\n",
" min_val = np.min([np.nanmin(rsm) for rsm in rsms])\n",
" max_val = np.max([np.nanmax(rsm) for rsm in rsms])\n",
"\n",
" bins = np.linspace(min_val, max_val, nbins+1)\n",
"\n",
" if labels is None:\n",
" labels = [labels] * len(rsms)\n",
" elif len(labels) != len(rsms):\n",
" raise ValueError(\"If providing labels, must provide as many as RSMs.\")\n",
"\n",
" if len(rsms) != len(colors):\n",
" raise ValueError(\"Must provide as many colors as RSMs.\")\n",
"\n",
" for r, rsm in enumerate(rsms):\n",
" ax.hist(\n",
" rsm.reshape(-1), bins, density=True, alpha=0.4,\n",
" color=colors[r], label=labels[r]\n",
" )\n",
" ax.axvline(x=0, ls=\"dashed\", alpha=0.6, color=\"k\")\n",
" ax.set_ylabel(\"Density\")\n",
" ax.set_xlabel(\"Similarity values\")\n",
" ax.legend()\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Helper functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Helper functions\n",
"\n",
"from IPython.display import display, Image # to visualize images\n",
"\n",
"# @markdown Function to set test custom torch RSM function: `test_custom_torch_RSM_fct()`\n",
"def test_custom_torch_RSM_fct(custom_torch_RSM_fct):\n",
" \"\"\"\n",
" Function to set test implementation of custom_torch_RSM_fct\n",
"\n",
" Args:\n",
" custom_torch_RSM_fct: f_name\n",
" Function to test\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" rand_feats = torch.rand(100, 1000)\n",
" RSM_custom = custom_torch_RSM_fct(rand_feats)\n",
" RSM_ground_truth = data.calculate_torch_RSM(rand_feats)\n",
"\n",
" if torch.allclose(RSM_custom, RSM_ground_truth, equal_nan=True):\n",
" print(\"custom_torch_RSM_fct() is correctly implemented.\")\n",
" else:\n",
" print(\"custom_torch_RSM_fct() is NOT correctly implemented.\")\n",
"\n",
"\n",
"# @markdown Function to set test custom contrastive loss function: `test_custom_contrastive_loss_fct()`\n",
"def test_custom_contrastive_loss_fct(custom_simclr_contrastive_loss):\n",
" \"\"\"\n",
" Function to set test implementation of custom_simclr_contrastive_loss\n",
"\n",
" Args:\n",
" custom_simclr_contrastive_loss: f_name\n",
" Function to test\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" rand_proj_feat1 = torch.rand(100, 1000)\n",
" rand_proj_feat2 = torch.rand(100, 1000)\n",
" loss_custom = custom_simclr_contrastive_loss(rand_proj_feat1, rand_proj_feat2)\n",
" loss_ground_truth = models.contrastive_loss(rand_proj_feat1,rand_proj_feat2)\n",
"\n",
" if torch.allclose(loss_custom, loss_ground_truth):\n",
" print(\"custom_simclr_contrastive_loss() is correctly implemented.\")\n",
" else:\n",
" print(\"custom_simclr_contrastive_loss() is NOT correctly implemented.\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Set random seed\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Executing `set_seed(seed=seed)` you are setting the seed\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Set random seed\n",
"\n",
"# @markdown Executing `set_seed(seed=seed)` you are setting the seed\n",
"\n",
"# For DL its critical to set the random seed so that students can have a\n",
"# baseline to compare their results to expected results.\n",
"# Read more here: https://pytorch.org/docs/stable/notes/randomness.html\n",
"\n",
"# Call `set_seed` function in the exercises to ensure reproducibility.\n",
"import random\n",
"import torch\n",
"\n",
"def set_seed(seed=None, seed_torch=True):\n",
" \"\"\"\n",
" Handles variability by controlling sources of randomness\n",
" through set seed values\n",
"\n",
" Args:\n",
" seed: Integer\n",
" Set the seed value to given integer.\n",
" If no seed, set seed value to random integer in the range 2^32\n",
" seed_torch: Bool\n",
" Seeds the random number generator for all devices to\n",
" offer some guarantees on reproducibility\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" if seed is None:\n",
" seed = np.random.choice(2 ** 32)\n",
" random.seed(seed)\n",
" np.random.seed(seed)\n",
" if seed_torch:\n",
" torch.manual_seed(seed)\n",
" torch.cuda.manual_seed_all(seed)\n",
" torch.cuda.manual_seed(seed)\n",
" torch.backends.cudnn.benchmark = False\n",
" torch.backends.cudnn.deterministic = True\n",
"\n",
" print(f'Random seed {seed} has been set.')\n",
"\n",
"\n",
"# In case that `DataLoader` is used\n",
"def seed_worker(worker_id):\n",
" \"\"\"\n",
" DataLoader will reseed workers following randomness in\n",
" multi-process data loading algorithm.\n",
"\n",
" Args:\n",
" worker_id: integer\n",
" ID of subprocess to seed. 0 means that\n",
" the data will be loaded in the main process\n",
" Refer: https://pytorch.org/docs/stable/data.html#data-loading-randomness for more details\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" worker_seed = torch.initial_seed() % 2**32\n",
" np.random.seed(worker_seed)\n",
" random.seed(worker_seed)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Set device (GPU or CPU). Execute `set_device()`\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Set device (GPU or CPU). Execute `set_device()`\n",
"# especially if torch modules used.\n",
"\n",
"# Inform the user if the notebook uses GPU or CPU.\n",
"\n",
"def set_device():\n",
" \"\"\"\n",
" Set the device. CUDA if available, CPU otherwise\n",
"\n",
" Args:\n",
" None\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
" if device != \"cuda\":\n",
" print(\"WARNING: For this notebook to perform best, \"\n",
" \"if possible, in the menu under `Runtime` -> \"\n",
" \"`Change runtime type.` select `GPU` \")\n",
" else:\n",
" print(\"GPU is enabled in this notebook.\")\n",
"\n",
" return device"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Set global variables\n",
"SEED = 2021\n",
"set_seed(seed=SEED)\n",
"DEVICE = set_device()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" ### Pre-load variables (allows each section to be run independently)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown ### Pre-load variables (allows each section to be run independently)\n",
"\n",
"# Section 1\n",
"dSprites = data.dSpritesDataset(\n",
" os.path.join(REPO_PATH, \"dsprites\", \"dsprites_subset.npz\")\n",
" )\n",
"\n",
"dSprites_torchdataset = data.dSpritesTorchDataset(\n",
" dSprites,\n",
" target_latent=\"shape\"\n",
" )\n",
"\n",
"train_sampler, test_sampler = data.train_test_split_idx(\n",
" dSprites_torchdataset,\n",
" fraction_train=0.8,\n",
" randst=SEED\n",
" )\n",
"\n",
"supervised_encoder = load.load_encoder(REPO_PATH,\n",
" model_type=\"supervised\",\n",
" verbose=False)\n",
"\n",
"# Section 2\n",
"custom_torch_RSM_fct = None # Default is used instead\n",
"\n",
"# Section 3\n",
"random_encoder = load.load_encoder(REPO_PATH,\n",
" model_type=\"random\",\n",
" verbose=False)\n",
"\n",
"# Section 4\n",
"vae_encoder = load.load_encoder(REPO_PATH,\n",
" model_type=\"vae\",\n",
" verbose=False)\n",
"\n",
"# Section 5\n",
"invariance_transforms = torchvision.transforms.RandomAffine(\n",
" degrees=90,\n",
" translate=(0.2, 0.2),\n",
" scale=(0.8, 1.2)\n",
" )\n",
"dSprites_invariance_torchdataset = data.dSpritesTorchDataset(\n",
" dSprites,\n",
" target_latent=\"shape\",\n",
" simclr=True,\n",
" simclr_transforms=invariance_transforms\n",
" )\n",
"\n",
"# Section 6\n",
"simclr_encoder = load.load_encoder(REPO_PATH,\n",
" model_type=\"simclr\",\n",
" verbose=False)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 0: Introduction"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 0: Introduction\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 0: Introduction\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'Q3b_EqFUI00'), ('Bilibili', 'BV1D64y1s78e')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Introduction_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 1: Representations are important\n",
"\n",
"*Time estimate: ~30mins*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 1: Why do representations matter?\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Why do representations matter?\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'lj5uTUo6W88'), ('Bilibili', 'BV1g54y1J7cE')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Why_do_representations_matter_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 1.1: Introducing the dSprites dataset"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In this tutorial, we will be using a subset of the openly available **dSprites dataset** to investigate the importance of learning good representations.\n",
"\n",
"_**Note on dataset:** For convenience, we will be using a subset of the original, full dataset which is available [here](https://github.com/deepmind/dsprites-dataset/), on GitHub._"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 1.1.1: Exploring the dSprites dataset\n",
"\n",
"In this first demo, we will get to know the **dSprites dataset**. This dataset is made up of black and white images (20,000 images total in the subset we are using).\n",
"\n",
"The images in the dataset can be described using different combinations of **latent dimension values**, sampled from:\n",
"- **Shapes (3):** square (1.0), oval (2.0) or heart (3.0)\n",
"- **Scales (6):** 0.5 to 1.0\n",
"- **Orientations (40):** 0 to 2$\\pi$\n",
"- **Positions in X (32):** 0 to 1 (left to right)\n",
"- **Positions in Y (32):** 0 to 1 (top to bottom)\n",
"\n",
"As a result, **each image carries 5 labels.** One for each of the latent dimensions.\n",
"\n",
"We will first load the dataset into the `dSprites` object, which is an instance of the `data.dSpritesDataset` class."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"dSprites = data.dSpritesDataset(\n",
" os.path.join(REPO_PATH, \"dsprites\", \"dsprites_subset.npz\")\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Next, we use the `dSpritesDataset` class method `show_images()` to plot a few images from the dataset, with their latent dimension values printed below.\n",
"\n",
"**Interactive Demo:** View a different set of randomly sampled images by passing the random state argument `randst` any integer or the value `None`. (The original setting is `randst=SEED`.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# DEMO: To view different images, set randst to any integer value.\n",
"dSprites.show_images(num_images=10, randst=SEED)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"To better understand the `posX` and `posY` latent dimensions (which will be most relevant in **Bonus 2**), we plot the images with some annotations. The annotations (in red) do not modify the actual images; they are added **purely for visualization purposes**, and show:\n",
" - the **edges** of the `posX` and `posY` spans, and\n",
" - the **center**, i.e., `(posX, posY)`, for each shape.\n",
"\n",
"_**Note on shape positions:** Notice that all shape centers are positioned **within the area marked by the red square**. `posX` and `posY` actually describe the relative position of the center of a shape within this area: `posX=0` (left) to `posX=1` (right), and `posY=0` (top) to `posY=1` (bottom). No shape center appears outside, in the buffer area. This choice in the dSprites dataset design ensures that shapes of different scales and rotations **all appear fully**._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# DEMO: To view different images, set randst to any integer value.\n",
"dSprites.show_images(num_images=10, randst=SEED, annotations=\"pos\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 1.2: Training a classifier with and without representations"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Now, we will investigate how 2 different types of classifiers perform when trained to decode the shape latent dimension of images in the **dSprites dataset**.\n",
"\n",
"Specifically, we will train **one classifier directly on the images**, and **another on the output of an encoder network**.\n",
"\n",
"The **encoder network** we will use here and throughout the tutorial is the multi-layer convolutional network, pictured below. It comprises 2 consecutive convolutional layers, followed by 3 fully connected layers, and uses average pooling and batch normalization between layers, as well as rectified linear units as non-linearities.\n",
"\n",
"The **classifier layer** then takes the encoder features as input, predicting, for example, the shape latent dimension of encoded input images.\n",
"\n",
"_**Note on terminology:** In this tutorial, both the terms **representations** and **features** are used to refer to the data embeddings learned in the final layer of the encoder network (of dimension 1x84, and indicated by a red dashed box) which are fed to the classifiers._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" ### Encoder network schematic\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown ### Encoder network schematic\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"feat_encoder_schematic.png\"), width=1200)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The following code:\n",
"* Seeds modules that will use random processes, to ensure the results are consistently reproducible, using the `seed_processes()` function,\n",
"* Collects the dSprites dataset into a torch dataset using the `data.dSpritesTorchDataset` class,\n",
"* Initializes a training and a test sampler to keep the two datasets separate using the `data.train_test_splix_idx()` function."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Set the seed before building any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"# Initialize a torch dataset, specifying the target latent dimension for\n",
"# the classifier\n",
"dSprites_torchdataset = data.dSpritesTorchDataset(\n",
" dSprites,\n",
" target_latent=\"shape\"\n",
" )\n",
"\n",
"# Initialize a train_sampler and a test_sampler to keep the two sets\n",
"# consistently separate\n",
"train_sampler, test_sampler = data.train_test_split_idx(\n",
" dSprites_torchdataset,\n",
" fraction_train=0.8, # 80:20 data split\n",
" randst=SEED\n",
" )\n",
"\n",
"print(f\"Dataset size: {len(train_sampler)} training, \"\n",
" f\"{len(test_sampler)} test images\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 1.2.1: Training a logistic regression classifier directly on images\n",
"\n",
"The following code:\n",
"* trains a logistic regression directly on the training set images to classify their shape, and assesses its performance on the test set images using the `models.train_classifier()` function.\n",
"\n",
"_**Interactive Demo:** Try a few different `num_epochs` settings to see whether performance improves with more training, e.g., between 1 and 50 epochs. (The original setting is `num_epochs=25`)._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_What_models_Video\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"num_epochs = 25 # DEMO: Try different numbers of training epochs\n",
"\n",
"# Train a classifier directly on the images\n",
"print(\"Training a classifier directly on the images...\")\n",
"_ = models.train_classifier(\n",
" encoder=None,\n",
" dataset=dSprites_torchdataset,\n",
" train_sampler=train_sampler,\n",
" test_sampler=test_sampler,\n",
" freeze_features=True, # There is no feature encoder to train here, anyway\n",
" num_epochs=num_epochs,\n",
" verbose=True # Print results\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As we can observe, the classifier trained directly on the images performs only a bit above chance (39.55%) on the test set, after 25 training epochs."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Shape classification results using different feature encoders:\n",
"\n",
"| _Chance_ | | None (raw data) |\n",
"| - | - | --- |\n",
"| _33.33%_ | | 39.55% |"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 1.2.1: Training a logistic regression classifier along with an encoder\n",
"\n",
"The following code:\n",
"* Uses the same dSprites torch dataset (`dSprites_torchdataset`) initialized above, as well as the training and test samplers (`train_sampler`, `test_sampler`),\n",
"* Again, seed modules for substructures that use random processes, to ensure the results are consistently reproducible,\n",
"* Initializes an encoder network to use in the supervised network using the `models.EncoderCore` class,\n",
"* Sets a proposed number of epochs to use when training the classifier and encoder (`num_epochs=10`).\n",
"\n",
"**Exercise:** Train a classifier, along with the encoder, to classify the input images according to shape, using `models.train_classifier()`. How does it perform?\n",
"\n",
"**Hints**:\n",
"- `models.train_classifier()`:\n",
" - Is introduced in **Interactive Demo 1.2.1**.\n",
" - Takes `freeze_features` as an input argument:\n",
" - If set to `True`, the encoder is frozen, and so only the classifier layer is trained.\n",
" - If set to `False`, the encoder is **not** frozen, and is trained along with the classifier layer."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def train_supervised_encoder(num_epochs, seed):\n",
" \"\"\"\n",
" Helper function to train the encoder in a supervised way\n",
"\n",
" Args:\n",
" num_epochs: Integer\n",
" Number of epochs the supervised encoder is to be trained for\n",
" seed: Integer\n",
" The seed value for the dataset/network\n",
"\n",
" Returns:\n",
" supervised_encoder: nn.module\n",
" The trained encoder with mentioned parameters/hyperparameters\n",
" \"\"\"\n",
" # Call this before any dataset/network initializing or training,\n",
" # to ensure reproducibility\n",
" set_seed(seed)\n",
"\n",
" # Initialize a core encoder network on which the classifier will be added\n",
" supervised_encoder = models.EncoderCore()\n",
"\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your implementation\n",
" raise NotImplementedError(\"Exercise: Train a supervised encoder and classifier.\")\n",
" #################################################\n",
" # Train an encoder and classifier on the images, using models.train_classifier()\n",
" print(\"Training a supervised encoder and classifier...\")\n",
" _ = models.train_classifier(\n",
" encoder=...,\n",
" dataset=...,\n",
" train_sampler=...,\n",
" test_sampler=...,\n",
" freeze_features=...,\n",
" num_epochs=num_epochs,\n",
" verbose=... # print results\n",
" )\n",
"\n",
" return supervised_encoder\n",
"\n",
"\n",
"\n",
"num_epochs = 10 # Proposed number of training epochs\n",
"## Uncomment below to test your function\n",
"# supervised_encoder = train_supervised_encoder(num_epochs=num_epochs, seed=SEED)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"Network performance after 10 encoder and classifier training epochs (chance: 33.33%):\n",
" Training accuracy: 100.00%\n",
" Testing accuracy: 98.70%\n",
"````"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_d96280b7.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Logistic_regression_classifier_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"When the classifier is trained with an encoder network, however, it achieves very high classification accuracy (~98.70%) on the test set, after only 10 training epochs."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Shape classification results using different feature encoders:\n",
"\n",
"| _Chance_ | | None (raw data) | Supervised |\n",
"| - | - | --- | --- |\n",
"| _33.33%_ | | 39.55% | 98.70% |"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 2: Supervised learning induces invariant representations\n",
"\n",
"*Time estimate: ~20mins*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 2: Supervised Learning and Invariance\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 2: Supervised Learning and Invariance\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'ZQka4k8ZOs0'), ('Bilibili', 'BV1d54y1E76W')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Supervised_learning_and_invariance_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 2.1: Examining Representational Similarity Matrices (RSMs)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"To examine the representations learned by the encoder network, we use **Representational Similarity Matrices (RSMs)**. In these matrices, the similarity between the encoder's representations of each possible pair of images is plotted to reveal overall structure in representation space.\n",
"\n",
"_**Note on cosine similarity:** Here, we use cosine similarity as a measure of representational similarity. Cosine similarity measures the angle between 2 vectors, and can be thought of as their normalized dot product._"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 2.1.1: Complete a function that calculates RSMs\n",
"\n",
"The following code:\n",
"* Lays out the skeleton of a function `custom_torch_RSM_fct()` which calculates an RSM from features,\n",
"* Tests the custom function against the solution implementation.\n",
"\n",
"**Exercise:** Complete the `custom_torch_RSM_fct()` implementation.\n",
"\n",
"**Hints**:\n",
"- `custom_torch_RSM_fct()`:\n",
" - Takes 1 input argument:\n",
" - `features` (2D torch Tensor): Feature matrix (nbr items x nbr features)\n",
" - Returns 1 output:\n",
" - `rsm` (2D torch Tensor): Similarity matrix (nbr items x nbr items)\n",
" - Uses `torch.nn.functional.cosine_similarity()`.\n",
"- `torch.nn.functional.cosine_similarity()`:\n",
" - Takes 3 arguments, in order:\n",
" - `x1` (torch Tensor),\n",
" - `x2` (torch Tensor),\n",
" - `dim` (int)\n",
" - Returns the similarity between `x1` and `x2` along dimension `dim`.\n",
"\n",
"**Detailed hint**:\n",
"- To use `torch.nn.functional.cosine_similarity()` to measure the similarity of `features` to **itself** for each possible **pair of items**:\n",
" - Pass 2 versions of `features` as `x1` and `x2`, respectively.\n",
" - Ensure that for `x1` and `x2`, the **features dimension is at the same position** , and specify that dimension with `dim`.\n",
" - To obtain the similarity between each possible pair of items, ensure that for `x1` and `x2`, the **items dimensions are orthogonal** to one another (i.e., at different positions).\n",
" - Don't forget that to achieve this, singleton dimensions (i.e., dimensions of length 1) can be used."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def custom_torch_RSM_fct(features):\n",
" \"\"\"\n",
" Custom function to calculate representational similarity matrix (RSM) of a feature\n",
" matrix using pairwise cosine similarity.\n",
"\n",
" Args:\n",
" features: 2D torch.Tensor\n",
" Feature matrix of size (nbr items x nbr features)\n",
"\n",
" Returns:\n",
" rsm: 2D torch.Tensor\n",
" Similarity matrix of size (nbr items x nbr items)\n",
" \"\"\"\n",
"\n",
" num_items, num_features = features.shape\n",
"\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # Complete the function below given the specific guidelines.\n",
" # Use torch.nn.functional.cosine_similarity()\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Exercise: Implement RSM calculation.\")\n",
" #################################################\n",
" # EXERCISE: Implement RSM calculation\n",
" rsm = ...\n",
"\n",
" if not rsm.shape == (num_items, num_items):\n",
" raise ValueError(f\"RSM should be of shape ({num_items}, {num_items})\")\n",
"\n",
" return rsm\n",
"\n",
"\n",
"\n",
"## Test implementation by comparing output to solution implementation\n",
"# test_custom_torch_RSM_fct(custom_torch_RSM_fct)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"custom_torch_RSM_fct() is correctly implemented.\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_2752aa1a.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Function_that_calculates_RSMs_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 2.1.1: Plotting the supervised network encoder RSM along different latent dimensions\n",
"\n",
"In this demo, we calculate an RSM for representations of the test set images generated by the supervised network encoder.\n",
"\n",
"The following code:\n",
"* Calculates and plots the RSM for the test set, with rows and columns sorted by whichever latent dimension is specified (e.g., `sorting_latent=\"shape\"`) using `models.plot_model_RSMs()`.\n",
"\n",
"**Interactive Demo:** In the current example, the rows and columns of the RSM are organized along the `shape` latent dimension. Try organizing them along one of the other latent dimensions (`\"scale\"`, `\"orientation\"`, `\"posX\"` or `\"posY\"`) to see whether different patterns emerge. (The original setting is `sorting_latent=\"shape\"`.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"sorting_latent = \"shape\" # DEMO: Try sorting by different latent dimensions\n",
"print(\"Plotting RSMs...\")\n",
"_ = models.plot_model_RSMs(\n",
" encoders=[supervised_encoder], # We pass the trained supervised_encoder\n",
" dataset=dSprites_torchdataset,\n",
" sampler=test_sampler, # We want to see the representations on the held out test set\n",
" titles=[\"Supervised network encoder RSM\"], # Plot title\n",
" sorting_latent=sorting_latent,\n",
" RSM_fct=custom_torch_RSM_fct\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Supervised_network_encoder_RSM_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 2.1.1: What patterns do the RSMs reveal about how the encoder represents different images?\n",
"**A.** What does the yellow (maximal similarity color) diagonal, going from the top left to the bottom right, correspond to?\n",
"**B.** What pattern can be observed when comparing RSM values for pairs of images that share a similar latent value (e.g., 2 heart images) vs pairs of images that do not (e.g., a heart and a square image)?\n",
"**C.** Do some shapes appear to be encoded more similarly than others?\n",
"**D.** Do some latent dimensions show clearer RSM patterns than others? Why might that be so?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" #### Supporting images for Discussion response examples for 2.1.1\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown #### Supporting images for Discussion response examples for 2.1.1\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"rsms_supervised_encoder_10ep_bs1000_seed2021.png\"), width=1200)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_50b74052.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_What_patterns_do_the_RSMs_reveal_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 3: Random projections don’t work as well\n",
"\n",
"*Time estimate: ~20mins*\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 3: Random Representations\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 3: Random Representations\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'LVM7Fm5T6Fs'), ('Bilibili', 'BV1Jf4y15789')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Random_representations_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.1: Examining RSMs of a random encoder"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"To determine whether the patterns observed in the RSMs of the supervised network encoder are trivial, we investigate whether they also emerge from the **random projections of an untrained encoder**."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 3.1.1: Plotting a random network encoder RSM along different latent dimensions\n",
"\n",
"In this exercise, we repeat the same analysis as in **Section 2.1**, but with a random encoder.\n",
"\n",
"The following code:\n",
"* Initializes an encoder network to use in the random network using the `models.EncoderCore` class,\n",
"* Proposes a latent dimension along which to sort the rows and columns (`sorting_latent=\"shape\"`).\n",
"\n",
"**Exercise:**\n",
"* Visualize the RSMs for the supervised and random network encoders, using `models.plot_model_RSMs()`.\n",
"* Visualize the RSMs, organized along different latent dimensions (`\"scale\"`, `\"orientation\"`, `\"posX\"` or `\"posY\"`), and compare the patterns observed for the supervised versus the random encoder network.\n",
"\n",
"**Hint**: `models.plot_model_RSMs()` is introduced in **Interactive Demo 2.1.1**."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def plot_rsms(seed):\n",
" \"\"\"\n",
" Helper function to plot Representational Similarity Matrices (RSMs)\n",
"\n",
" Args:\n",
" seed: Integer\n",
" The seed value for the dataset/network\n",
"\n",
" Returns:\n",
" random_encoder: nn.module\n",
" The encoder with mentioned parameters/hyperparameters\n",
" \"\"\"\n",
" # Call this before any dataset/network initializing or training,\n",
" # to ensure reproducibility\n",
" set_seed(seed)\n",
"\n",
" # Initialize a core encoder network that will not get trained\n",
" random_encoder = models.EncoderCore()\n",
"\n",
" # Try sorting by different latent dimensions\n",
" sorting_latent = \"shape\"\n",
"\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your implementation\n",
" raise NotImplementedError(\"Exercise: Plot RSMs.\")\n",
" #################################################\n",
" # Plot RSMs\n",
" print(\"Plotting RSMs...\")\n",
" _ = models.plot_model_RSMs(\n",
" encoders=[..., ...], # Pass both encoders\n",
" dataset=...,\n",
" sampler=..., # To see the representations on the held out test set\n",
" titles=[\"Supervised network encoder RSM\",\n",
" \"Random network encoder RSM\"], # Plot titles\n",
" sorting_latent=sorting_latent,\n",
" )\n",
"\n",
" return random_encoder\n",
"\n",
"\n",
"\n",
"## Uncomment below to test your function\n",
"# random_encoder = plot_rsms(seed=SEED)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_f066182b.py)\n",
"\n",
"*Example output:*\n",
"\n",
"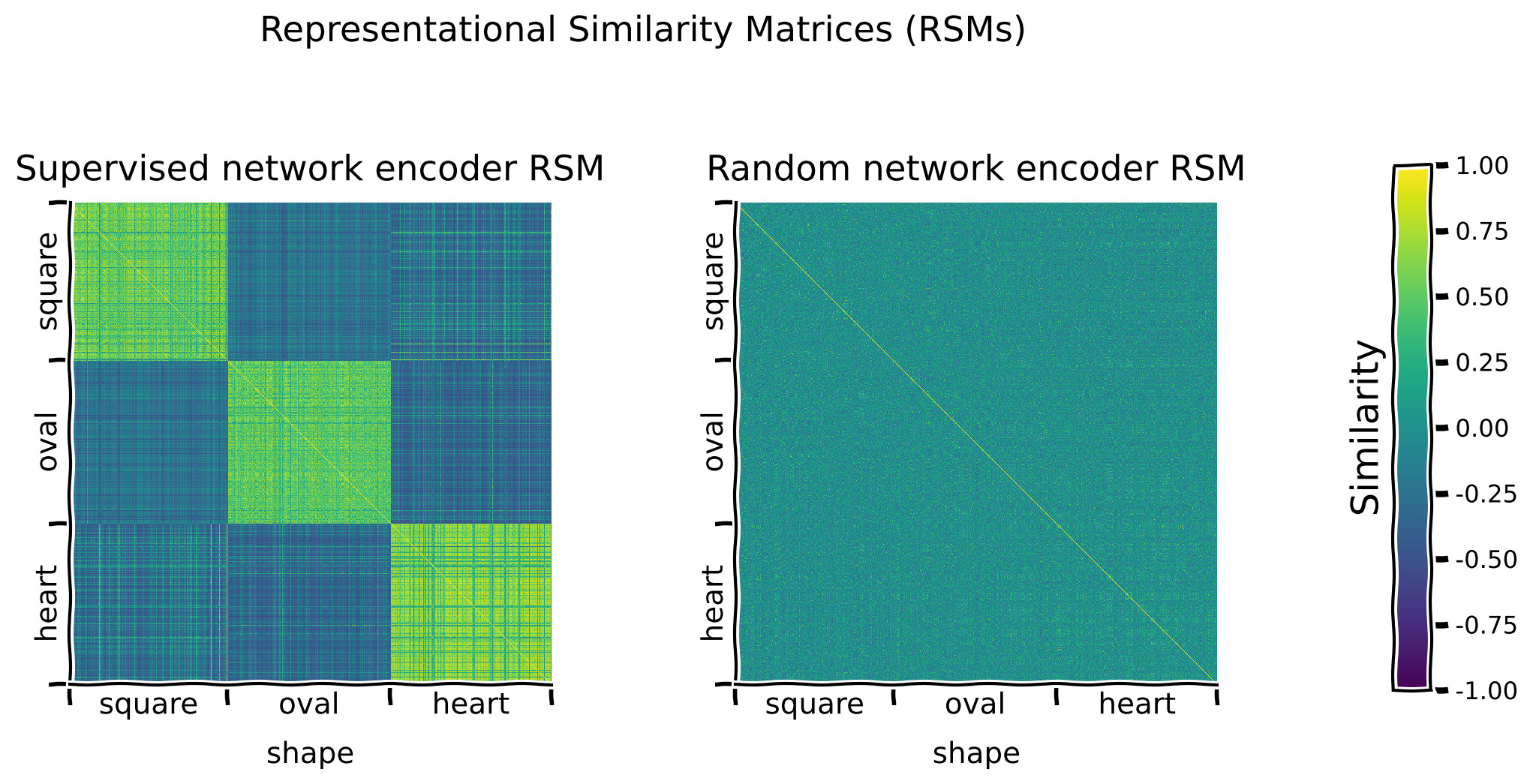 \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Plotting_a_random_network_encoder_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 3.1.1: What does comparing these RSMs reveal about the potential value of trained versus random encoder representations?\n",
"\n",
"**A.** What patterns, if any, are visible in the random network encoder RSM?\n",
"**B.** Which encoder network is most likely to produce meaningful representations?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" #### Supporting images for Discussion response examples for 3.1.1: All random encoder RSMs\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown #### Supporting images for Discussion response examples for 3.1.1: All random encoder RSMs\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"rsms_random_encoder_0ep_bs0_seed2021.png\"), width=1000)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_8b06362b.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Trained_vs_Random_encoder_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 3.1.2: Evaluating the classification performance of a logistic regression trained on the representations produced by a random network encoder\n",
"\n",
"In this exercise, we repeat a similar analysis to **Section 1.2**, but with the random encoder network. Importantly, this time, the encoder parameters must stay frozen during training by setting `freeze_features=True`. Instead of being provided ahead of time a suggestion for a reasonable number of training epochs, we use the training loss array to select a good value.\n",
"\n",
"\n",
"The following code:\n",
"* Trains a logistic regression on top of the random encoder network to classify images based on shape, and assesses its performance on the test set images using `models.train_classifier()` with `freeze_features=True` to ensure that the encoder is **not** trained, and only the classifier is.\n",
"\n",
"**Exercise:**\n",
"* Set a number of epochs for which to train the classifier.\n",
"* Plot the training loss array (`random_loss_array`, i.e., training loss at each epoch) returned when training the model.\n",
"* Rerun the classifier if more training epochs are needed based on the progression of the training loss.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def plot_loss(num_epochs, seed):\n",
" \"\"\"\n",
" Helper function to plot the loss function of the random-encoder\n",
"\n",
" Args:\n",
" num_epochs: Integer\n",
" Number of the epochs the random encoder is to be trained for\n",
" seed: Integer\n",
" The seed value for the dataset/network\n",
"\n",
" Returns:\n",
" random_loss_array: List\n",
" Loss per epoch\n",
" \"\"\"\n",
" # Call this before any dataset/network initializing or training,\n",
" # to ensure reproducibility\n",
" set_seed(seed)\n",
"\n",
" # Train classifier on the randomly encoded images\n",
" print(\"Training a classifier on the random encoder representations...\")\n",
" _, random_loss_array, _, _ = models.train_classifier(\n",
" encoder=random_encoder,\n",
" dataset=dSprites_torchdataset,\n",
" train_sampler=train_sampler,\n",
" test_sampler=test_sampler,\n",
" freeze_features=True, # Keep the encoder frozen while training the classifier\n",
" num_epochs=num_epochs,\n",
" verbose=True # Print results\n",
" )\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your implementation\n",
" raise NotImplementedError(\"Exercise: Plot loss array.\")\n",
" #################################################\n",
" # Plot the loss array\n",
" fig, ax = plt.subplots()\n",
" ax.plot(...)\n",
" ax.set_title(...)\n",
" ax.set_xlabel(...)\n",
" ax.set_ylabel(...)\n",
"\n",
" return random_loss_array\n",
"\n",
"\n",
"\n",
"## Set a reasonable number of training epochs\n",
"num_epochs = 25\n",
"## Uncomment below to test your plot\n",
"# random_loss_array = plot_loss(num_epochs=num_epochs, seed=SEED)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"Network performance after 25 classifier training epochs (chance: 33.33%):\n",
" Training accuracy: 46.02%\n",
" Testing accuracy: 44.67%\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_16901ca7.py)\n",
"\n",
"*Example output:*\n",
"\n",
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Plotting_a_random_network_encoder_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 3.1.1: What does comparing these RSMs reveal about the potential value of trained versus random encoder representations?\n",
"\n",
"**A.** What patterns, if any, are visible in the random network encoder RSM?\n",
"**B.** Which encoder network is most likely to produce meaningful representations?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" #### Supporting images for Discussion response examples for 3.1.1: All random encoder RSMs\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown #### Supporting images for Discussion response examples for 3.1.1: All random encoder RSMs\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"rsms_random_encoder_0ep_bs0_seed2021.png\"), width=1000)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_8b06362b.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Trained_vs_Random_encoder_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 3.1.2: Evaluating the classification performance of a logistic regression trained on the representations produced by a random network encoder\n",
"\n",
"In this exercise, we repeat a similar analysis to **Section 1.2**, but with the random encoder network. Importantly, this time, the encoder parameters must stay frozen during training by setting `freeze_features=True`. Instead of being provided ahead of time a suggestion for a reasonable number of training epochs, we use the training loss array to select a good value.\n",
"\n",
"\n",
"The following code:\n",
"* Trains a logistic regression on top of the random encoder network to classify images based on shape, and assesses its performance on the test set images using `models.train_classifier()` with `freeze_features=True` to ensure that the encoder is **not** trained, and only the classifier is.\n",
"\n",
"**Exercise:**\n",
"* Set a number of epochs for which to train the classifier.\n",
"* Plot the training loss array (`random_loss_array`, i.e., training loss at each epoch) returned when training the model.\n",
"* Rerun the classifier if more training epochs are needed based on the progression of the training loss.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def plot_loss(num_epochs, seed):\n",
" \"\"\"\n",
" Helper function to plot the loss function of the random-encoder\n",
"\n",
" Args:\n",
" num_epochs: Integer\n",
" Number of the epochs the random encoder is to be trained for\n",
" seed: Integer\n",
" The seed value for the dataset/network\n",
"\n",
" Returns:\n",
" random_loss_array: List\n",
" Loss per epoch\n",
" \"\"\"\n",
" # Call this before any dataset/network initializing or training,\n",
" # to ensure reproducibility\n",
" set_seed(seed)\n",
"\n",
" # Train classifier on the randomly encoded images\n",
" print(\"Training a classifier on the random encoder representations...\")\n",
" _, random_loss_array, _, _ = models.train_classifier(\n",
" encoder=random_encoder,\n",
" dataset=dSprites_torchdataset,\n",
" train_sampler=train_sampler,\n",
" test_sampler=test_sampler,\n",
" freeze_features=True, # Keep the encoder frozen while training the classifier\n",
" num_epochs=num_epochs,\n",
" verbose=True # Print results\n",
" )\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your implementation\n",
" raise NotImplementedError(\"Exercise: Plot loss array.\")\n",
" #################################################\n",
" # Plot the loss array\n",
" fig, ax = plt.subplots()\n",
" ax.plot(...)\n",
" ax.set_title(...)\n",
" ax.set_xlabel(...)\n",
" ax.set_ylabel(...)\n",
"\n",
" return random_loss_array\n",
"\n",
"\n",
"\n",
"## Set a reasonable number of training epochs\n",
"num_epochs = 25\n",
"## Uncomment below to test your plot\n",
"# random_loss_array = plot_loss(num_epochs=num_epochs, seed=SEED)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"Network performance after 25 classifier training epochs (chance: 33.33%):\n",
" Training accuracy: 46.02%\n",
" Testing accuracy: 44.67%\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_16901ca7.py)\n",
"\n",
"*Example output:*\n",
"\n",
" \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Evaluating_the_classification_performance_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The network loss training is fairly stable by 25 epochs, at which point the classifier performs at 44.67% accuracy on the test dataset."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Shape classification results using different feature encoders:\n",
"\n",
"| _Chance_ | | None (raw data) | Supervised | Random |\n",
"| - | - | --- | --- | --- |\n",
"| _33.33%_ | | 39.55% | 98.70% | 44.67% |"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 3.1.2: What can we conclude about the potential consequences of using random projections with a dataset like dSprites?\n",
"\n",
"**A.** How does the classifier performance compare to the classifier trained directly on the images?\n",
"**B.** How does the classifier performance compare to the classifier trained along with the encoder (supervised encoder)?\n",
"**C.** What explains these different performances?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_28e6be8a.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Random_projections_with_dSprites_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 4: Generative approaches to representation learning can fail\n",
"\n",
"*Time estimate: ~30mins*\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 4: Generative models\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 4: Generative models\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'NUittg0EKSM'), ('Bilibili', 'BV1YP4y147UT')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Generative_models_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 4.1: Examining the RSMs of a Variational Autoencoder\n",
"\n",
"We next ask - What kind of representations a network can learn in the absence of labelled data? To answer this question, we first look at a **generative model**, namely the **Variational Autoencoder (VAE)**.\n",
"\n",
"Given that generative models typically require more training than supervised models, instead of pre-training a network here, we will load one that was **pre-trained for 300 epochs**. Importantly, the **encoder shares the same architecture** as the one used for the supervised and random examples above.\n",
"\n",
"The following code:\n",
"* Loads the parameters of a full Variational AutoEncoder (VAE) network (encoder and decoder) pre-trained on the generative task of reconstructing the input images, under the Kullback–Leibler Divergence (KLD) minimization constraint over the latent space that characterizes VAEs, using `load.load_encoder()` and `load.load_decoder()`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"# Load VAE encoder and decoder pre-trained on the reconstruction and KLD tasks\n",
"vae_encoder = load.load_encoder(REPO_PATH, model_type=\"vae\")\n",
"vae_decoder = load.load_vae_decoder(REPO_PATH)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 4.1.1: Plotting example reconstructions using the pre-trained VAE encoder and decoder\n",
"\n",
"In this demo, we sample images from the test set, and take a look at the quality of the reconstructions using `models.plot_vae_reconstructions()`.\n",
"\n",
"**Interactive Demo:** Try plotting different images from the test dataset by selecting different `test_sampler.indices` values. (Original setting is `indices=test_sampler.indices[:10]`.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"models.plot_vae_reconstructions(\n",
" vae_encoder, # Pre-trained encoder\n",
" vae_decoder, # Pre-trained decoder\n",
" dataset=dSprites_torchdataset,\n",
" indices=test_sampler.indices[:10], # DEMO: Select different indices to plot from the test set\n",
" title=\"VAE test set image reconstructions\",\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Pretrained_VAE_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 4.1.1: How does the VAE perform on the reconstruction task?\n",
"**A.** Which latent features does the network appear to preserve well, and which does it preserve less well?\n",
"**B.** Based on the reconstruction performance, what do you expect to see in the different RSMs?\n",
"\n",
"**Note on reconstruction quality:** This VAE network uses a basic VAE loss with a convolutional encoder (our core encoder network), and a deconvolutional decoder. This can lead to some blurriness in the reconstructed shapes which a more sophisticated VAE could overcome."
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_5e470358.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_VAE_on_the_reconstruction_task_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 4.1.2: Visualizing the VAE encoder RSMs, organized along different latent dimensions\n",
"\n",
"We will now compare the pre-trained VAE encoder network RSM to the previously generated encoder RSMs.\n",
"\n",
"**Interactive Demo:** Visualize the RSMs, organized along different latent dimensions (`\"scale\"`, `\"orientation\"`, `\"posX\"` or `\"posY\"`), and compare the patterns observed for the different encoder networks. (The original setting is `sorting_latent=\"shape\"`.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"sorting_latent = \"shape\" # DEMO: Try sorting by different latent dimensions\n",
"print(\"Plotting RSMs...\")\n",
"_ = models.plot_model_RSMs(\n",
" encoders=[supervised_encoder, random_encoder, vae_encoder], # Pass all three encoders\n",
" dataset=dSprites_torchdataset,\n",
" sampler=test_sampler, # To see the representations on the held out test set\n",
" titles=[\"Supervised network encoder RSM\", \"Random network encoder RSM\",\n",
" \"VAE network encoder RSM\"], # Plot titles\n",
" sorting_latent=sorting_latent,\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_VAE_encoder_RSMs_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 4.1.2: What can we conclude about the the ability of generative models like VAEs to construct a meaningful representation space?\n",
"\n",
"**A.** What structure can be observed in the pre-trained VAE encoder RSMs when sorted along the different latent dimensions, and what does that suggest about the feature space learned by the VAE encoder?\n",
"**B.** How do the pre-trained VAE encoder RSMs compare to the supervised and random encoder network RSMs?\n",
"**C.** What explains these different RSMs?\n",
"**D.** How well will the pre-trained VAE encoder likely perform on the shape classification task, as compared to the other encoder networks?\n",
"**E.** Might the pre-trained VAE encoder be better suited to predicting a different latent dimension?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" #### Supporting images for Discussion response examples for 4.1.2: All VAE encoder RSMs\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown #### Supporting images for Discussion response examples for 4.1.2: All VAE encoder RSMs\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"rsms_vae_encoder_300ep_bs500_seed2021.png\"), width=1000)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_b7aba28a.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Construct_a_meaningful_representation_space_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 4.1.2: Evaluating the classification performance of a logistic regression trained on the representations produced by the pre-trained VAE network encoder\n",
"\n",
"For the pre-trained VAE encoder, as the encoder parameters have already been trained, they should be kept frozen while the classifier is trained by setting `freeze_features=True`.\n",
"\n",
"**Exercise:**\n",
"* Set a number of epochs for which to train the classifier.\n",
"* Train a classifier, along with the encoder, to classify the input images according to shape, using `models.train_classifier()`.\n",
"* Plot the loss array returned when training the model, and update the number of training epochs, if needed.\n",
"\n",
"**Hint**: `models.train_classifier()` is introduced in **Interactive Demo 1.2.1**."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def vae_train_loss(num_epochs, seed):\n",
" \"\"\"\n",
" Helper function to plot the train loss of the variational autoencoder (VAE)\n",
"\n",
" Args:\n",
" num_epochs: Integer\n",
" Number of the epochs the VAE is to be trained for\n",
" seed: Integer\n",
" The seed value for the dataset/network\n",
"\n",
" Returns:\n",
" vae_loss_array: List\n",
" Loss per epoch\n",
" \"\"\"\n",
" # Call this before any dataset/network initializing or training,\n",
" # to ensure reproducibility\n",
" set_seed(seed)\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your implementation\n",
" raise NotImplementedError(\"Exercise: Train a classifer on the pre-trained VAE encoder representations.\")\n",
" #################################################\n",
" # Train an encoder and classifier on the images, using models.train_classifier()\n",
" print(\"Training a classifier on the pre-trained VAE encoder representations...\")\n",
" _, vae_loss_array, _, _ = models.train_classifier(\n",
" encoder=...,\n",
" dataset=...,\n",
" train_sampler=...,\n",
" test_sampler=...,\n",
" freeze_features=..., # Keep the encoder frozen while training the classifier\n",
" num_epochs=...,\n",
" verbose=... # Print results\n",
" )\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your implementation\n",
" raise NotImplementedError(\"Exercise: Plot the VAE classifier training loss.\")\n",
" #################################################\n",
" # Plot the VAE classifier training loss.\n",
" fig, ax = plt.subplots()\n",
" ax.plot(...)\n",
" ax.set_title(...)\n",
" ax.set_xlabel(...)\n",
" ax.set_ylabel(...)\n",
"\n",
" return vae_loss_array\n",
"\n",
"\n",
"\n",
"# Set a reasonable number of training epochs\n",
"num_epochs = 25\n",
"## Uncomment below to test your function\n",
"# vae_loss_array = vae_train_loss(num_epochs=num_epochs, seed=SEED)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"Network performance after 25 classifier training epochs (chance: 33.33%):\n",
" Training accuracy: 46.48%\n",
" Testing accuracy: 45.75%\n",
"````"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_b605b4ed.py)\n",
"\n",
"*Example output:*\n",
"\n",
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Evaluating_the_classification_performance_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The network loss training is fairly stable by 25 epochs, at which point the classifier performs at 44.67% accuracy on the test dataset."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Shape classification results using different feature encoders:\n",
"\n",
"| _Chance_ | | None (raw data) | Supervised | Random |\n",
"| - | - | --- | --- | --- |\n",
"| _33.33%_ | | 39.55% | 98.70% | 44.67% |"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 3.1.2: What can we conclude about the potential consequences of using random projections with a dataset like dSprites?\n",
"\n",
"**A.** How does the classifier performance compare to the classifier trained directly on the images?\n",
"**B.** How does the classifier performance compare to the classifier trained along with the encoder (supervised encoder)?\n",
"**C.** What explains these different performances?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_28e6be8a.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Random_projections_with_dSprites_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 4: Generative approaches to representation learning can fail\n",
"\n",
"*Time estimate: ~30mins*\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 4: Generative models\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 4: Generative models\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'NUittg0EKSM'), ('Bilibili', 'BV1YP4y147UT')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Generative_models_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 4.1: Examining the RSMs of a Variational Autoencoder\n",
"\n",
"We next ask - What kind of representations a network can learn in the absence of labelled data? To answer this question, we first look at a **generative model**, namely the **Variational Autoencoder (VAE)**.\n",
"\n",
"Given that generative models typically require more training than supervised models, instead of pre-training a network here, we will load one that was **pre-trained for 300 epochs**. Importantly, the **encoder shares the same architecture** as the one used for the supervised and random examples above.\n",
"\n",
"The following code:\n",
"* Loads the parameters of a full Variational AutoEncoder (VAE) network (encoder and decoder) pre-trained on the generative task of reconstructing the input images, under the Kullback–Leibler Divergence (KLD) minimization constraint over the latent space that characterizes VAEs, using `load.load_encoder()` and `load.load_decoder()`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"# Load VAE encoder and decoder pre-trained on the reconstruction and KLD tasks\n",
"vae_encoder = load.load_encoder(REPO_PATH, model_type=\"vae\")\n",
"vae_decoder = load.load_vae_decoder(REPO_PATH)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 4.1.1: Plotting example reconstructions using the pre-trained VAE encoder and decoder\n",
"\n",
"In this demo, we sample images from the test set, and take a look at the quality of the reconstructions using `models.plot_vae_reconstructions()`.\n",
"\n",
"**Interactive Demo:** Try plotting different images from the test dataset by selecting different `test_sampler.indices` values. (Original setting is `indices=test_sampler.indices[:10]`.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"models.plot_vae_reconstructions(\n",
" vae_encoder, # Pre-trained encoder\n",
" vae_decoder, # Pre-trained decoder\n",
" dataset=dSprites_torchdataset,\n",
" indices=test_sampler.indices[:10], # DEMO: Select different indices to plot from the test set\n",
" title=\"VAE test set image reconstructions\",\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Pretrained_VAE_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 4.1.1: How does the VAE perform on the reconstruction task?\n",
"**A.** Which latent features does the network appear to preserve well, and which does it preserve less well?\n",
"**B.** Based on the reconstruction performance, what do you expect to see in the different RSMs?\n",
"\n",
"**Note on reconstruction quality:** This VAE network uses a basic VAE loss with a convolutional encoder (our core encoder network), and a deconvolutional decoder. This can lead to some blurriness in the reconstructed shapes which a more sophisticated VAE could overcome."
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_5e470358.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_VAE_on_the_reconstruction_task_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 4.1.2: Visualizing the VAE encoder RSMs, organized along different latent dimensions\n",
"\n",
"We will now compare the pre-trained VAE encoder network RSM to the previously generated encoder RSMs.\n",
"\n",
"**Interactive Demo:** Visualize the RSMs, organized along different latent dimensions (`\"scale\"`, `\"orientation\"`, `\"posX\"` or `\"posY\"`), and compare the patterns observed for the different encoder networks. (The original setting is `sorting_latent=\"shape\"`.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"sorting_latent = \"shape\" # DEMO: Try sorting by different latent dimensions\n",
"print(\"Plotting RSMs...\")\n",
"_ = models.plot_model_RSMs(\n",
" encoders=[supervised_encoder, random_encoder, vae_encoder], # Pass all three encoders\n",
" dataset=dSprites_torchdataset,\n",
" sampler=test_sampler, # To see the representations on the held out test set\n",
" titles=[\"Supervised network encoder RSM\", \"Random network encoder RSM\",\n",
" \"VAE network encoder RSM\"], # Plot titles\n",
" sorting_latent=sorting_latent,\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_VAE_encoder_RSMs_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 4.1.2: What can we conclude about the the ability of generative models like VAEs to construct a meaningful representation space?\n",
"\n",
"**A.** What structure can be observed in the pre-trained VAE encoder RSMs when sorted along the different latent dimensions, and what does that suggest about the feature space learned by the VAE encoder?\n",
"**B.** How do the pre-trained VAE encoder RSMs compare to the supervised and random encoder network RSMs?\n",
"**C.** What explains these different RSMs?\n",
"**D.** How well will the pre-trained VAE encoder likely perform on the shape classification task, as compared to the other encoder networks?\n",
"**E.** Might the pre-trained VAE encoder be better suited to predicting a different latent dimension?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" #### Supporting images for Discussion response examples for 4.1.2: All VAE encoder RSMs\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown #### Supporting images for Discussion response examples for 4.1.2: All VAE encoder RSMs\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"rsms_vae_encoder_300ep_bs500_seed2021.png\"), width=1000)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_b7aba28a.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Construct_a_meaningful_representation_space_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 4.1.2: Evaluating the classification performance of a logistic regression trained on the representations produced by the pre-trained VAE network encoder\n",
"\n",
"For the pre-trained VAE encoder, as the encoder parameters have already been trained, they should be kept frozen while the classifier is trained by setting `freeze_features=True`.\n",
"\n",
"**Exercise:**\n",
"* Set a number of epochs for which to train the classifier.\n",
"* Train a classifier, along with the encoder, to classify the input images according to shape, using `models.train_classifier()`.\n",
"* Plot the loss array returned when training the model, and update the number of training epochs, if needed.\n",
"\n",
"**Hint**: `models.train_classifier()` is introduced in **Interactive Demo 1.2.1**."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def vae_train_loss(num_epochs, seed):\n",
" \"\"\"\n",
" Helper function to plot the train loss of the variational autoencoder (VAE)\n",
"\n",
" Args:\n",
" num_epochs: Integer\n",
" Number of the epochs the VAE is to be trained for\n",
" seed: Integer\n",
" The seed value for the dataset/network\n",
"\n",
" Returns:\n",
" vae_loss_array: List\n",
" Loss per epoch\n",
" \"\"\"\n",
" # Call this before any dataset/network initializing or training,\n",
" # to ensure reproducibility\n",
" set_seed(seed)\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your implementation\n",
" raise NotImplementedError(\"Exercise: Train a classifer on the pre-trained VAE encoder representations.\")\n",
" #################################################\n",
" # Train an encoder and classifier on the images, using models.train_classifier()\n",
" print(\"Training a classifier on the pre-trained VAE encoder representations...\")\n",
" _, vae_loss_array, _, _ = models.train_classifier(\n",
" encoder=...,\n",
" dataset=...,\n",
" train_sampler=...,\n",
" test_sampler=...,\n",
" freeze_features=..., # Keep the encoder frozen while training the classifier\n",
" num_epochs=...,\n",
" verbose=... # Print results\n",
" )\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your implementation\n",
" raise NotImplementedError(\"Exercise: Plot the VAE classifier training loss.\")\n",
" #################################################\n",
" # Plot the VAE classifier training loss.\n",
" fig, ax = plt.subplots()\n",
" ax.plot(...)\n",
" ax.set_title(...)\n",
" ax.set_xlabel(...)\n",
" ax.set_ylabel(...)\n",
"\n",
" return vae_loss_array\n",
"\n",
"\n",
"\n",
"# Set a reasonable number of training epochs\n",
"num_epochs = 25\n",
"## Uncomment below to test your function\n",
"# vae_loss_array = vae_train_loss(num_epochs=num_epochs, seed=SEED)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"Network performance after 25 classifier training epochs (chance: 33.33%):\n",
" Training accuracy: 46.48%\n",
" Testing accuracy: 45.75%\n",
"````"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_b605b4ed.py)\n",
"\n",
"*Example output:*\n",
"\n",
" \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Evaluate_performance_using_pretrained_VAE_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The network loss training is fairly stable by 25 epochs, at which point the classifier performs at 45.75% accuracy on the test dataset."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Shape classification results using different feature encoders:\n",
"\n",
"| _Chance_ | | None (raw data) | Supervised | Random | VAE |\n",
"| - | - | --- | --- | --- | --- |\n",
"| _33.33%_ | | 39.55% | 98.70% | 44.67% | 45.75% |"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 5: The modern approach to self-supervised training for invariance\n",
"\n",
"*Time estimate: ~10mins*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 5: Modern Approach in Self-supervised Learning\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 5: Modern Approach in Self-supervised Learning\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'hUWcsSFWZyw'), ('Bilibili', 'BV1Bv411n7zP')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Modern_approach_in_Selfsupervised_Learning_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 5.1: Examining different options for learning invariant representations."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We now take a look at a few options for learning invariant shape representations for a dataset such as **dSprites**."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 5.1.1: Visualizing a few different image transformations available that could be used to learn invariance\n",
"\n",
"The following code:\n",
"* Initializes a set of transforms called `invariance_transforms` using the `torchvision.transforms.RandomAffine` class,\n",
"* Collects the dSprites dataset into a torch dataset `dSprites_invariance_torchdataset` which takes the `invariance_transforms` as input and deploys the transforms when it is called,\n",
"* Shows a few examples of images and their transformed versions using the `data.dSpritesTorchDataset` `show_images()` method.\n",
"\n",
"The `torchvision.transforms.RandomAffine` class enables us to predetermine which types and ranges of transforms will be sampled from when transforming the images, by setting the following arguments:\n",
"* `degrees`: Absolute maximum number of degrees to rotate\n",
"* `translate`: Absolute maximum proportion of width to shift in x, and of height to shift in y\n",
"* `scale`: Minimum to maximum scaling factor\n",
"\n",
"**Interactive Demo:** Try out a few combinations of the transformation parameters, and visualize the pairs of transformations of the same image. (The original settings are `degrees=90`, `translate=(0.2, 0.2)`, `scale=(0.8, 1.2)`.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"# DEMO: Try some random affine data augmentations combinations to apply to the images\n",
"invariance_transforms = torchvision.transforms.RandomAffine(\n",
" degrees=90,\n",
" translate=(0.2, 0.2), # (in x, in y)\n",
" scale=(0.8, 1.2) # min to max scaling\n",
" )\n",
"\n",
"# Initialize a simclr-specific torch dataset\n",
"dSprites_invariance_torchdataset = data.dSpritesTorchDataset(\n",
" dSprites,\n",
" target_latent=\"shape\",\n",
" simclr=True,\n",
" simclr_transforms=invariance_transforms\n",
" )\n",
"\n",
"# Show a few example of pairs of image augmentations\n",
"_ = dSprites_invariance_torchdataset.show_images(randst=SEED)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Image_transformations_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 6: How to train for invariance to transformations with a target network\n",
"\n",
"*Time estimate: ~40mins*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 6: Data Transformations\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 6: Data Transformations\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'g6IxiUXubhM'), ('Bilibili', 'BV1H64y1t7ag')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Data_Transformations_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 6.1: Using image transformations to learn feature invariant representations in a Self-supervised Learning (SSL) network."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We will now investigate the effects of selecting certain transformations compared to others on the invariance learned by an encoder network trained with a **specific type of SSL algorithm, namely SimCLR**. Specifically, we will observe how pre-training an encoder network with SimCLR affects the performance of a classifier trained on the representations the network has learned."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 6.1.1: Complete a SimCLR loss function\n",
"\n",
"The following code:\n",
"* Lays out the skeleton of a function `custom_simclr_contrastive_loss()` which calculates the contrastive loss for a SimCLR network,\n",
"* Tests the custom function against the solution implementation,\n",
"* Trains SimCLR for a few epochs.\n",
"\n",
"**Exercise:**\n",
"* Complete the `custom_simclr_contrastive_loss()` implementation,\n",
"* Plot the loss after training SimCLR with the custom loss function for a few epochs.\n",
"\n",
"**Detailed hint**:\n",
"- `custom_simclr_contrastive_loss()`:\n",
" - Takes 2 input arguments:\n",
" - `proj_feat1` (2D torch Tensor): Projected features for first image augmentations (batch_size x feat_size)\n",
" - `proj_feat2` (2D torch Tensor): Projected features for second image augmentations (batch_size x feat_size)\n",
" - Computes the `similarity_matrix` for all possible pairs of image augmentations.\n",
" - Identifies positive and negative sample indicators for indexing the `similarity_matrix`:\n",
" - `pos_sample_indicators` (2D torch Tensor): Tensor indicating the positions of **positive** image pairs with 1s (and 0s in all other positions). (batch_size \\* 2 x batch_size * 2)\n",
" - `neg_sample_indicators` (2D torch Tensor): Tensor indicating the positions of **negative** image pairs with 1s (and 0s in all other positions). (batch_size \\* 2 x batch_size * 2)\n",
" - Computes the 2 parts of the contrastive loss, retrieving the relevant values from the `similarity_matrix` using the indicators:\n",
" - `numerator`: Calculated from the `similarity_matrix` values for positive pairs.\n",
" - `denominator`: Calculated from the `similarity_matrix` values for negative pairs."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def custom_simclr_contrastive_loss(proj_feat1, proj_feat2, temperature=0.5):\n",
" \"\"\"\n",
" Returns contrastive loss, given sets of projected features, with positive\n",
" pairs matched along the batch dimension.\n",
"\n",
" Args:\n",
" Required:\n",
" proj_feat1: 2D torch.Tensor\n",
" Projected features for first image with augmentations (size: batch_size x feat_size)\n",
" proj_feat2: 2D torch.Tensor\n",
" Projected features for second image with augmentations (size: batch_size x feat_size)\n",
" Optional:\n",
" temperature: Float\n",
" relaxation temperature (default: 0.5)\n",
" l2 normalization along with temperature effectively weights different\n",
" examples, and an appropriate temperature can help the model learn from hard negatives.\n",
" Returns:\n",
" loss: Float\n",
" Mean contrastive loss\n",
" \"\"\"\n",
" device = proj_feat1.device\n",
"\n",
" if len(proj_feat1) != len(proj_feat2):\n",
" raise ValueError(f\"Batch dimension of proj_feat1 ({len(proj_feat1)}) \"\n",
" f\"and proj_feat2 ({len(proj_feat2)}) should be same\")\n",
"\n",
" batch_size = len(proj_feat1) # N\n",
" z1 = torch.nn.functional.normalize(proj_feat1, dim=1)\n",
" z2 = torch.nn.functional.normalize(proj_feat2, dim=1)\n",
"\n",
" proj_features = torch.cat([z1, z2], dim=0) # 2N x projected feature dimension\n",
" similarity_matrix = torch.nn.functional.cosine_similarity(\n",
" proj_features.unsqueeze(1), proj_features.unsqueeze(0), dim=2\n",
" ) # dim: 2N x 2N\n",
"\n",
" # Initialize arrays to identify sets of positive and negative examples, of\n",
" # shape (batch_size * 2, batch_size * 2), and where\n",
" # 0 indicates that 2 images are NOT a pair (either positive or negative, depending on the indicator type)\n",
" # 1 indices that 2 images ARE a pair (either positive or negative, depending on the indicator type)\n",
" pos_sample_indicators = torch.roll(torch.eye(2 * batch_size), batch_size, 1).to(device)\n",
" neg_sample_indicators = (torch.ones(2 * batch_size) - torch.eye(2 * batch_size)).to(device)\n",
"\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Exercise: Implement SimCLR loss.\")\n",
" #################################################\n",
" # Implement the SimClr loss calculation\n",
" # Calculate the numerator of the Loss expression by selecting the appropriate elements from similarity_matrix.\n",
" # Use the pos_sample_indicators tensor\n",
" numerator = ...\n",
"\n",
" # Calculate the denominator of the Loss expression by selecting the appropriate elements from similarity_matrix,\n",
" # and summing over pairs for each item.\n",
" # Use the neg_sample_indicators tensor\n",
" denominator = ...\n",
"\n",
" if (denominator < 1e-8).any(): # Clamp to avoid division by 0\n",
" denominator = torch.clamp(denominator, 1e-8)\n",
"\n",
" loss = torch.mean(-torch.log(numerator / denominator))\n",
"\n",
" return loss\n",
"\n",
"\n",
"\n",
"## Uncomment below to test your function\n",
"# test_custom_contrastive_loss_fct(custom_simclr_contrastive_loss)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"custom_simclr_contrastive_loss() is correctly implemented.\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_83f2e4e0.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_SimCLR_loss_function_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We can now train the SimCLR encoder with the custom contrastive loss for a few epochs."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"# Train SimCLR for a few epochs\n",
"print(\"Training a SimCLR encoder with the custom contrastive loss...\")\n",
"num_epochs = 5\n",
"_, test_simclr_loss_array = models.train_simclr(\n",
" encoder=models.EncoderCore(),\n",
" dataset=dSprites_invariance_torchdataset,\n",
" train_sampler=train_sampler,\n",
" num_epochs=num_epochs,\n",
" loss_fct=custom_simclr_contrastive_loss\n",
" )\n",
"\n",
"# Plot SimCLR loss over a few epochs.\n",
"fig, ax = plt.subplots()\n",
"ax.plot(test_simclr_loss_array)\n",
"ax.set_title(\"SimCLR network loss\")\n",
"ax.set_xlabel(\"Epoch number\")\n",
"_ = ax.set_ylabel(\"Training loss\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
"Given that self-supervised models typically require more training than supervised models, instead of fully pre-training a network here, we will load one that was **pre-trained for 60 epochs**. Again, the **encoder shares the same architecture** as the one used for the supervised, random and VAE examples above.\n",
"\n",
"The following code:\n",
"* Loads the parameters of a SimCLR network pre-trained on the SimCLR contrastive task using `load.load_encoder()`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Load SimCLR encoder pre-trained on the contrastive loss\n",
"simclr_encoder = load.load_encoder(REPO_PATH, model_type=\"simclr\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 6.1.1: Evaluating the classification performance of a logistic regression trained on the representations produced by a SimCLR network encoder that was pre-trained using different image transformations\n",
"\n",
"For the pre-trained SimCLR encoder, as with the VAE encoder, as the encoder parameters have already been trained, they should be kept frozen while the classifier is trained by setting `freeze_features=True`.\n",
"\n",
"We train and test with `dSprites_torch dataset` instead of `dSprites_invariance_torch dataset`, as we are interested in the classifier performance on the real dSprites images, and not their augmentations.\n",
"\n",
"**Interactive Demo:** Try different numbers of epochs for which to train the classifier. (The original setting is `num_epochs=10`.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"print(\"Training a classifier on the pre-trained SimCLR encoder representations...\")\n",
"_, simclr_loss_array, _, _ = models.train_classifier(\n",
" encoder=simclr_encoder,\n",
" dataset=dSprites_torchdataset,\n",
" train_sampler=train_sampler,\n",
" test_sampler=test_sampler,\n",
" freeze_features=True, # Keep the encoder frozen while training the classifier\n",
" num_epochs=10, # DEMO: Try different numbers of epochs\n",
" verbose=True\n",
" )\n",
"\n",
"fig, ax = plt.subplots()\n",
"ax.plot(simclr_loss_array)\n",
"ax.set_title(\"Loss of classifier trained on a SimCLR encoder.\")\n",
"ax.set_xlabel(\"Epoch number\")\n",
"_ = ax.set_ylabel(\"Training loss\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"Network performance after 10 classifier training epochs (chance: 33.33%):\n",
" Training accuracy: 97.83%\n",
" Testing accuracy: 97.53%\n",
"````"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Evaluate_performance_using_pretrained_SimCLR_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The network (using the transforms proposed above) performs at 97.53% accuracy on the test dataset, after 15 classifier training epochs."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Shape classification results using different feature encoders:\n",
"\n",
"| _Chance_ | | None (raw data) | Supervised | Random | VAE | SimCLR |\n",
"| - | - | --- | --- | --- | --- | --- |\n",
"| _33.33%_ | | 39.55% | 98.70% | 44.67% | 45.75% | 97.53% |"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 7: Ethical considerations for self-supervised learning from biased datasets"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 7: Un/Self-Supervised Learning\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 7: Un/Self-Supervised Learning\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'NT006a6nkyg'), ('Bilibili', 'BV1mP4y1473E')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Un_self_supervised_learning_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 7.1: The consequences of training models on biased datasets"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"If a model is trained on a biased dataset, it is likely to learn a representational encoding that reproduces these biases, impairing its ability to generalize properly and increasing the likelihood that it will propagate these biases forward.\n",
"\n",
"Here, we investigate the effects of training the models on a biased subset of the training dataset. Specifically, we introduce a `train_sampler_biased`, a training dataset sampler that only samples:\n",
"* **Squares**, if they are centered on the **lefthand** side of an image **(posX: 0 to 0.3)**,\n",
"* **Ovals**, if they are centered in the **center** of an image **(posX: 0.35 to 0.65)**,\n",
"* **Hearts**, if they are centered on the **righthand** side of am image **(posX: 0.7 to 1.0)**.\n",
"\n",
"This sampling bias introduces a correlation between `shape` and `posX` that does not exist in the original dataset.\n",
"\n",
"We then train each model as above on the dataset, and observe their performance when tested on an unbiased dataset.\n",
"\n",
"_**Note on dataset size:** This biased sampling also significantly reduces the size of the training dataset available (approximately 6x). Thus, it would not be fair to compare our results here to those obtained previously in the tutorial, when we were using the full dataset. For this reason, **as a control, we will also separately train the models with `train_sampler_bias_ctrl`**, a training dataset sampler that does not share the same sampling bias as `train_sampler_biased`, but can only sample as many samples as `train_sampler_biased` can._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"bias_type = \"shape_posX_spaced\" # Name of bias\n",
"\n",
"# Initialize a biased training sampler and an unbiased test sampler\n",
"train_sampler_biased, test_sampler_for_biased = data.train_test_split_idx(\n",
" dSprites_torchdataset,\n",
" fraction_train=0.95, # 95:5 Split to partially compensate for loss of training examples due to bias\n",
" randst=SEED,\n",
" train_bias=bias_type\n",
" )\n",
"\n",
"# Initialize a control, unbiased training sampler and an unbiased test sampler\n",
"train_sampler_bias_ctrl, test_sampler_for_bias_ctrl = data.train_test_split_idx(\n",
" dSprites_torchdataset,\n",
" fraction_train=0.95,\n",
" randst=SEED,\n",
" train_bias=bias_type,\n",
" control=True\n",
" )\n",
"\n",
"print(f\"Biased dataset: {len(train_sampler_biased)} training, \"\n",
" f\"{len(test_sampler_for_biased)} test images\")\n",
"print(f\"Bias control dataset: {len(train_sampler_bias_ctrl)} training, \"\n",
" f\"{len(test_sampler_for_bias_ctrl)} test images\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We plot some images sampled with `train_sampler_biased` to observe the pattern described above where `shape` and `posX` are now correlated.\n",
"\n",
"To better visualize the bias introduced, we will plot them with annotations that show, in red:\n",
" - The **edges** of each of the 3 `posX` sections, and\n",
" - The **center**, i.e. `(posX, posY)`, for each shape."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"print(\"Plotting first 20 images from the biased training dataset.\\n\")\n",
"dSprites.show_images(indices=train_sampler_biased.indices[:20], annotations=\"posX_quadrants\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We also plot some images sampled with `train_sampler_bias_ctrl` to verify visually that this biased pattern does not appear in the control dataset.\n",
"\n",
"Again, the annotations are added, **purely for visualization purposes**."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"print(\"Plotting sample images from the bias control training dataset.\\n\")\n",
"dSprites.show_images(indices=train_sampler_bias_ctrl.indices[:20], annotations=\"posX_quadrants\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown ### Function to run full training procedure\n",
"# @markdown (from initializing and pretraining encoders to training classifiers):\n",
"\n",
"# @markdown `full_training_procedure(train_sampler, test_sampler)`\n",
"\n",
"def full_training_procedure(train_sampler, test_sampler, title=None,\n",
" dataset_type=\"biased\", verbose=True):\n",
" \"\"\"\n",
" Funtion to load pretrained VAE and SimCLR encoders\n",
"\n",
" Args:\n",
" train_sampler: torch.Tensor\n",
" Training Data\n",
" test_sampler: torch.Tensor\n",
" Test Data\n",
" title: String\n",
" Title\n",
" dataset_type: String\n",
" Specifies if the expected model type is biased/bias-controlled\n",
" verbose: Boolean\n",
" If true, the shell shows all lines in the script in execution\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" if dataset_type not in [\"biased\", \"bias_ctrl\"]:\n",
" raise ValueError(\"Expected model_type to be 'biased' or 'bias_ctrl', \"\n",
" f\"but found {model_type}.\")\n",
"\n",
" supervised_encoder = models.EncoderCore()\n",
" random_encoder = models.EncoderCore()\n",
"\n",
" # Load pre-trained VAE\n",
" vae_encoder = load.load_encoder(\n",
" REPO_PATH, model_type=\"vae\", dataset_type=dataset_type,\n",
" verbose=verbose\n",
" )\n",
"\n",
" # Load pre-trained SimCLR encoder\n",
" simclr_encoder = load.load_encoder(\n",
" REPO_PATH, model_type=\"simclr\", dataset_type=dataset_type,\n",
" verbose=verbose\n",
" )\n",
"\n",
" encoders = [supervised_encoder, random_encoder, vae_encoder, simclr_encoder]\n",
" freeze_features = [False, True, True, True]\n",
" encoder_labels = [\"supervised\", \"random\", \"VAE\", \"SimCLR\"]\n",
"\n",
" num_clf_epochs = [80, 30, 30, 30]\n",
" print(f\"\\nTraining supervised encoder and classifier for {num_clf_epochs[0]} \"\n",
" f\"epochs, and all other classifiers for {num_clf_epochs[1]} epochs each.\")\n",
" _ = models.train_encoder_clfs_by_fraction_labelled(\n",
" encoders=encoders,\n",
" dataset=dSprites_torchdataset,\n",
" train_sampler=train_sampler,\n",
" test_sampler=test_sampler,\n",
" num_epochs=num_clf_epochs,\n",
" freeze_features=freeze_features,\n",
" subset_seed=SEED,\n",
" encoder_labels=encoder_labels,\n",
" title=title,\n",
" verbose=verbose\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Here, we use a **biased training data sampler** (and unbiased control sampler) to observe how the different models perform. Because the dataset is much smaller, we increase the number of pre-trained and training epochs for the encoders and classifiers.\n",
"\n",
"Let us start with our **unbiased control sampler**, to get a sense of the classification performance levels we should expect with a dataset this size."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"print(\"Training all models using the control, unbiased training dataset\\n\")\n",
"full_training_procedure(\n",
" train_sampler_bias_ctrl, test_sampler_for_bias_ctrl,\n",
" title=\"Classifier performances with control, unbiased training dataset\",\n",
" dataset_type=\"bias_ctrl\" # For loading correct pre-trained networks\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"A similar pattern is observed here as with the full dataset, though notably most performances are a bit weaker, likely due to us (A) using a smaller training dataset, and (B) training and pre-training for fewer iterations, considering the dataset size, for time-efficiency reasons.\n",
"\n",
"Using the same parameters, we now repeat the analysis with the **biased** training data sampler."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"print(\"Training all models using the biased training dataset\\n\")\n",
"full_training_procedure(\n",
" train_sampler_biased, test_sampler_for_biased,\n",
" title=\"Classifier performances with biased training dataset\",\n",
" dataset_type=\"biased\" # For loading correct pre-trained networks\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Interestingly, the SimCLR network encoder is not only the only network to perform well, it even outperforms its control performance (which uses the same test dataset), at least with this particular dataset and biasing.\n",
"\n",
"_**Note on performance improvement:** This improvement for the SimCLR encoder is reflected in the pre-training loss curves (not shown here), which show that the encoder trained with the biased dataset learns faster than the encoder trained with the unbiased training set. It is possible that the dataset biasing, by reducing the variability in the dataset, makes the contrastive task easier, thus enabling the network to learn a good feature space for the classification task in fewer epochs_"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 7.1.1: How do different models cope with a biased training dataset?\n",
"\n",
"**A.** Which models are most and least affected by the biased training dataset?\n",
"**B.** Which types of images in the test set are most likely causing the observed drop in performance?\n",
"**C.** Why are certain models more robust to the bias introduced here than others?\n",
"**D.** What are some methods we can employ to help mitigate the negative effects of biases in our training sets on our ability to learn good data representations with our models?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_a25cd7d9.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Biased_training_dataset_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 7.1.2: How do these principles apply more generally?\n",
"\n",
"We have seen now how self-supervised learning (SSL) can improve a network's ability to learn good representations of data. For the purposes of this tutorial, we presented examples with a **simplified dataset**: the dSprites dataset, where we know:\n",
"(1) The latent dimensions for all images,\n",
"(2) The joint probability distribution across latent dimensions for the full dataset, and\n",
"(3) The precise nature of the bias introduced into our biased dataset **(see Bonus 2 for more details)**.\n",
"\n",
"As a result, it is quite simple to design data augmentations that ensure that the pre-trained encoder will learn a good feature space for the downstream classification task.\n",
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Evaluate_performance_using_pretrained_VAE_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The network loss training is fairly stable by 25 epochs, at which point the classifier performs at 45.75% accuracy on the test dataset."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Shape classification results using different feature encoders:\n",
"\n",
"| _Chance_ | | None (raw data) | Supervised | Random | VAE |\n",
"| - | - | --- | --- | --- | --- |\n",
"| _33.33%_ | | 39.55% | 98.70% | 44.67% | 45.75% |"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 5: The modern approach to self-supervised training for invariance\n",
"\n",
"*Time estimate: ~10mins*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 5: Modern Approach in Self-supervised Learning\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 5: Modern Approach in Self-supervised Learning\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'hUWcsSFWZyw'), ('Bilibili', 'BV1Bv411n7zP')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Modern_approach_in_Selfsupervised_Learning_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 5.1: Examining different options for learning invariant representations."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We now take a look at a few options for learning invariant shape representations for a dataset such as **dSprites**."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 5.1.1: Visualizing a few different image transformations available that could be used to learn invariance\n",
"\n",
"The following code:\n",
"* Initializes a set of transforms called `invariance_transforms` using the `torchvision.transforms.RandomAffine` class,\n",
"* Collects the dSprites dataset into a torch dataset `dSprites_invariance_torchdataset` which takes the `invariance_transforms` as input and deploys the transforms when it is called,\n",
"* Shows a few examples of images and their transformed versions using the `data.dSpritesTorchDataset` `show_images()` method.\n",
"\n",
"The `torchvision.transforms.RandomAffine` class enables us to predetermine which types and ranges of transforms will be sampled from when transforming the images, by setting the following arguments:\n",
"* `degrees`: Absolute maximum number of degrees to rotate\n",
"* `translate`: Absolute maximum proportion of width to shift in x, and of height to shift in y\n",
"* `scale`: Minimum to maximum scaling factor\n",
"\n",
"**Interactive Demo:** Try out a few combinations of the transformation parameters, and visualize the pairs of transformations of the same image. (The original settings are `degrees=90`, `translate=(0.2, 0.2)`, `scale=(0.8, 1.2)`.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"# DEMO: Try some random affine data augmentations combinations to apply to the images\n",
"invariance_transforms = torchvision.transforms.RandomAffine(\n",
" degrees=90,\n",
" translate=(0.2, 0.2), # (in x, in y)\n",
" scale=(0.8, 1.2) # min to max scaling\n",
" )\n",
"\n",
"# Initialize a simclr-specific torch dataset\n",
"dSprites_invariance_torchdataset = data.dSpritesTorchDataset(\n",
" dSprites,\n",
" target_latent=\"shape\",\n",
" simclr=True,\n",
" simclr_transforms=invariance_transforms\n",
" )\n",
"\n",
"# Show a few example of pairs of image augmentations\n",
"_ = dSprites_invariance_torchdataset.show_images(randst=SEED)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Image_transformations_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 6: How to train for invariance to transformations with a target network\n",
"\n",
"*Time estimate: ~40mins*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 6: Data Transformations\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 6: Data Transformations\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'g6IxiUXubhM'), ('Bilibili', 'BV1H64y1t7ag')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Data_Transformations_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 6.1: Using image transformations to learn feature invariant representations in a Self-supervised Learning (SSL) network."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We will now investigate the effects of selecting certain transformations compared to others on the invariance learned by an encoder network trained with a **specific type of SSL algorithm, namely SimCLR**. Specifically, we will observe how pre-training an encoder network with SimCLR affects the performance of a classifier trained on the representations the network has learned."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 6.1.1: Complete a SimCLR loss function\n",
"\n",
"The following code:\n",
"* Lays out the skeleton of a function `custom_simclr_contrastive_loss()` which calculates the contrastive loss for a SimCLR network,\n",
"* Tests the custom function against the solution implementation,\n",
"* Trains SimCLR for a few epochs.\n",
"\n",
"**Exercise:**\n",
"* Complete the `custom_simclr_contrastive_loss()` implementation,\n",
"* Plot the loss after training SimCLR with the custom loss function for a few epochs.\n",
"\n",
"**Detailed hint**:\n",
"- `custom_simclr_contrastive_loss()`:\n",
" - Takes 2 input arguments:\n",
" - `proj_feat1` (2D torch Tensor): Projected features for first image augmentations (batch_size x feat_size)\n",
" - `proj_feat2` (2D torch Tensor): Projected features for second image augmentations (batch_size x feat_size)\n",
" - Computes the `similarity_matrix` for all possible pairs of image augmentations.\n",
" - Identifies positive and negative sample indicators for indexing the `similarity_matrix`:\n",
" - `pos_sample_indicators` (2D torch Tensor): Tensor indicating the positions of **positive** image pairs with 1s (and 0s in all other positions). (batch_size \\* 2 x batch_size * 2)\n",
" - `neg_sample_indicators` (2D torch Tensor): Tensor indicating the positions of **negative** image pairs with 1s (and 0s in all other positions). (batch_size \\* 2 x batch_size * 2)\n",
" - Computes the 2 parts of the contrastive loss, retrieving the relevant values from the `similarity_matrix` using the indicators:\n",
" - `numerator`: Calculated from the `similarity_matrix` values for positive pairs.\n",
" - `denominator`: Calculated from the `similarity_matrix` values for negative pairs."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def custom_simclr_contrastive_loss(proj_feat1, proj_feat2, temperature=0.5):\n",
" \"\"\"\n",
" Returns contrastive loss, given sets of projected features, with positive\n",
" pairs matched along the batch dimension.\n",
"\n",
" Args:\n",
" Required:\n",
" proj_feat1: 2D torch.Tensor\n",
" Projected features for first image with augmentations (size: batch_size x feat_size)\n",
" proj_feat2: 2D torch.Tensor\n",
" Projected features for second image with augmentations (size: batch_size x feat_size)\n",
" Optional:\n",
" temperature: Float\n",
" relaxation temperature (default: 0.5)\n",
" l2 normalization along with temperature effectively weights different\n",
" examples, and an appropriate temperature can help the model learn from hard negatives.\n",
" Returns:\n",
" loss: Float\n",
" Mean contrastive loss\n",
" \"\"\"\n",
" device = proj_feat1.device\n",
"\n",
" if len(proj_feat1) != len(proj_feat2):\n",
" raise ValueError(f\"Batch dimension of proj_feat1 ({len(proj_feat1)}) \"\n",
" f\"and proj_feat2 ({len(proj_feat2)}) should be same\")\n",
"\n",
" batch_size = len(proj_feat1) # N\n",
" z1 = torch.nn.functional.normalize(proj_feat1, dim=1)\n",
" z2 = torch.nn.functional.normalize(proj_feat2, dim=1)\n",
"\n",
" proj_features = torch.cat([z1, z2], dim=0) # 2N x projected feature dimension\n",
" similarity_matrix = torch.nn.functional.cosine_similarity(\n",
" proj_features.unsqueeze(1), proj_features.unsqueeze(0), dim=2\n",
" ) # dim: 2N x 2N\n",
"\n",
" # Initialize arrays to identify sets of positive and negative examples, of\n",
" # shape (batch_size * 2, batch_size * 2), and where\n",
" # 0 indicates that 2 images are NOT a pair (either positive or negative, depending on the indicator type)\n",
" # 1 indices that 2 images ARE a pair (either positive or negative, depending on the indicator type)\n",
" pos_sample_indicators = torch.roll(torch.eye(2 * batch_size), batch_size, 1).to(device)\n",
" neg_sample_indicators = (torch.ones(2 * batch_size) - torch.eye(2 * batch_size)).to(device)\n",
"\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Exercise: Implement SimCLR loss.\")\n",
" #################################################\n",
" # Implement the SimClr loss calculation\n",
" # Calculate the numerator of the Loss expression by selecting the appropriate elements from similarity_matrix.\n",
" # Use the pos_sample_indicators tensor\n",
" numerator = ...\n",
"\n",
" # Calculate the denominator of the Loss expression by selecting the appropriate elements from similarity_matrix,\n",
" # and summing over pairs for each item.\n",
" # Use the neg_sample_indicators tensor\n",
" denominator = ...\n",
"\n",
" if (denominator < 1e-8).any(): # Clamp to avoid division by 0\n",
" denominator = torch.clamp(denominator, 1e-8)\n",
"\n",
" loss = torch.mean(-torch.log(numerator / denominator))\n",
"\n",
" return loss\n",
"\n",
"\n",
"\n",
"## Uncomment below to test your function\n",
"# test_custom_contrastive_loss_fct(custom_simclr_contrastive_loss)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"custom_simclr_contrastive_loss() is correctly implemented.\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_83f2e4e0.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_SimCLR_loss_function_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We can now train the SimCLR encoder with the custom contrastive loss for a few epochs."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"# Train SimCLR for a few epochs\n",
"print(\"Training a SimCLR encoder with the custom contrastive loss...\")\n",
"num_epochs = 5\n",
"_, test_simclr_loss_array = models.train_simclr(\n",
" encoder=models.EncoderCore(),\n",
" dataset=dSprites_invariance_torchdataset,\n",
" train_sampler=train_sampler,\n",
" num_epochs=num_epochs,\n",
" loss_fct=custom_simclr_contrastive_loss\n",
" )\n",
"\n",
"# Plot SimCLR loss over a few epochs.\n",
"fig, ax = plt.subplots()\n",
"ax.plot(test_simclr_loss_array)\n",
"ax.set_title(\"SimCLR network loss\")\n",
"ax.set_xlabel(\"Epoch number\")\n",
"_ = ax.set_ylabel(\"Training loss\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
"Given that self-supervised models typically require more training than supervised models, instead of fully pre-training a network here, we will load one that was **pre-trained for 60 epochs**. Again, the **encoder shares the same architecture** as the one used for the supervised, random and VAE examples above.\n",
"\n",
"The following code:\n",
"* Loads the parameters of a SimCLR network pre-trained on the SimCLR contrastive task using `load.load_encoder()`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Load SimCLR encoder pre-trained on the contrastive loss\n",
"simclr_encoder = load.load_encoder(REPO_PATH, model_type=\"simclr\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 6.1.1: Evaluating the classification performance of a logistic regression trained on the representations produced by a SimCLR network encoder that was pre-trained using different image transformations\n",
"\n",
"For the pre-trained SimCLR encoder, as with the VAE encoder, as the encoder parameters have already been trained, they should be kept frozen while the classifier is trained by setting `freeze_features=True`.\n",
"\n",
"We train and test with `dSprites_torch dataset` instead of `dSprites_invariance_torch dataset`, as we are interested in the classifier performance on the real dSprites images, and not their augmentations.\n",
"\n",
"**Interactive Demo:** Try different numbers of epochs for which to train the classifier. (The original setting is `num_epochs=10`.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"print(\"Training a classifier on the pre-trained SimCLR encoder representations...\")\n",
"_, simclr_loss_array, _, _ = models.train_classifier(\n",
" encoder=simclr_encoder,\n",
" dataset=dSprites_torchdataset,\n",
" train_sampler=train_sampler,\n",
" test_sampler=test_sampler,\n",
" freeze_features=True, # Keep the encoder frozen while training the classifier\n",
" num_epochs=10, # DEMO: Try different numbers of epochs\n",
" verbose=True\n",
" )\n",
"\n",
"fig, ax = plt.subplots()\n",
"ax.plot(simclr_loss_array)\n",
"ax.set_title(\"Loss of classifier trained on a SimCLR encoder.\")\n",
"ax.set_xlabel(\"Epoch number\")\n",
"_ = ax.set_ylabel(\"Training loss\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"Network performance after 10 classifier training epochs (chance: 33.33%):\n",
" Training accuracy: 97.83%\n",
" Testing accuracy: 97.53%\n",
"````"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Evaluate_performance_using_pretrained_SimCLR_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The network (using the transforms proposed above) performs at 97.53% accuracy on the test dataset, after 15 classifier training epochs."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Shape classification results using different feature encoders:\n",
"\n",
"| _Chance_ | | None (raw data) | Supervised | Random | VAE | SimCLR |\n",
"| - | - | --- | --- | --- | --- | --- |\n",
"| _33.33%_ | | 39.55% | 98.70% | 44.67% | 45.75% | 97.53% |"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 7: Ethical considerations for self-supervised learning from biased datasets"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 7: Un/Self-Supervised Learning\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 7: Un/Self-Supervised Learning\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'NT006a6nkyg'), ('Bilibili', 'BV1mP4y1473E')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Un_self_supervised_learning_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 7.1: The consequences of training models on biased datasets"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"If a model is trained on a biased dataset, it is likely to learn a representational encoding that reproduces these biases, impairing its ability to generalize properly and increasing the likelihood that it will propagate these biases forward.\n",
"\n",
"Here, we investigate the effects of training the models on a biased subset of the training dataset. Specifically, we introduce a `train_sampler_biased`, a training dataset sampler that only samples:\n",
"* **Squares**, if they are centered on the **lefthand** side of an image **(posX: 0 to 0.3)**,\n",
"* **Ovals**, if they are centered in the **center** of an image **(posX: 0.35 to 0.65)**,\n",
"* **Hearts**, if they are centered on the **righthand** side of am image **(posX: 0.7 to 1.0)**.\n",
"\n",
"This sampling bias introduces a correlation between `shape` and `posX` that does not exist in the original dataset.\n",
"\n",
"We then train each model as above on the dataset, and observe their performance when tested on an unbiased dataset.\n",
"\n",
"_**Note on dataset size:** This biased sampling also significantly reduces the size of the training dataset available (approximately 6x). Thus, it would not be fair to compare our results here to those obtained previously in the tutorial, when we were using the full dataset. For this reason, **as a control, we will also separately train the models with `train_sampler_bias_ctrl`**, a training dataset sampler that does not share the same sampling bias as `train_sampler_biased`, but can only sample as many samples as `train_sampler_biased` can._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"bias_type = \"shape_posX_spaced\" # Name of bias\n",
"\n",
"# Initialize a biased training sampler and an unbiased test sampler\n",
"train_sampler_biased, test_sampler_for_biased = data.train_test_split_idx(\n",
" dSprites_torchdataset,\n",
" fraction_train=0.95, # 95:5 Split to partially compensate for loss of training examples due to bias\n",
" randst=SEED,\n",
" train_bias=bias_type\n",
" )\n",
"\n",
"# Initialize a control, unbiased training sampler and an unbiased test sampler\n",
"train_sampler_bias_ctrl, test_sampler_for_bias_ctrl = data.train_test_split_idx(\n",
" dSprites_torchdataset,\n",
" fraction_train=0.95,\n",
" randst=SEED,\n",
" train_bias=bias_type,\n",
" control=True\n",
" )\n",
"\n",
"print(f\"Biased dataset: {len(train_sampler_biased)} training, \"\n",
" f\"{len(test_sampler_for_biased)} test images\")\n",
"print(f\"Bias control dataset: {len(train_sampler_bias_ctrl)} training, \"\n",
" f\"{len(test_sampler_for_bias_ctrl)} test images\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We plot some images sampled with `train_sampler_biased` to observe the pattern described above where `shape` and `posX` are now correlated.\n",
"\n",
"To better visualize the bias introduced, we will plot them with annotations that show, in red:\n",
" - The **edges** of each of the 3 `posX` sections, and\n",
" - The **center**, i.e. `(posX, posY)`, for each shape."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"print(\"Plotting first 20 images from the biased training dataset.\\n\")\n",
"dSprites.show_images(indices=train_sampler_biased.indices[:20], annotations=\"posX_quadrants\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We also plot some images sampled with `train_sampler_bias_ctrl` to verify visually that this biased pattern does not appear in the control dataset.\n",
"\n",
"Again, the annotations are added, **purely for visualization purposes**."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"print(\"Plotting sample images from the bias control training dataset.\\n\")\n",
"dSprites.show_images(indices=train_sampler_bias_ctrl.indices[:20], annotations=\"posX_quadrants\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown ### Function to run full training procedure\n",
"# @markdown (from initializing and pretraining encoders to training classifiers):\n",
"\n",
"# @markdown `full_training_procedure(train_sampler, test_sampler)`\n",
"\n",
"def full_training_procedure(train_sampler, test_sampler, title=None,\n",
" dataset_type=\"biased\", verbose=True):\n",
" \"\"\"\n",
" Funtion to load pretrained VAE and SimCLR encoders\n",
"\n",
" Args:\n",
" train_sampler: torch.Tensor\n",
" Training Data\n",
" test_sampler: torch.Tensor\n",
" Test Data\n",
" title: String\n",
" Title\n",
" dataset_type: String\n",
" Specifies if the expected model type is biased/bias-controlled\n",
" verbose: Boolean\n",
" If true, the shell shows all lines in the script in execution\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" if dataset_type not in [\"biased\", \"bias_ctrl\"]:\n",
" raise ValueError(\"Expected model_type to be 'biased' or 'bias_ctrl', \"\n",
" f\"but found {model_type}.\")\n",
"\n",
" supervised_encoder = models.EncoderCore()\n",
" random_encoder = models.EncoderCore()\n",
"\n",
" # Load pre-trained VAE\n",
" vae_encoder = load.load_encoder(\n",
" REPO_PATH, model_type=\"vae\", dataset_type=dataset_type,\n",
" verbose=verbose\n",
" )\n",
"\n",
" # Load pre-trained SimCLR encoder\n",
" simclr_encoder = load.load_encoder(\n",
" REPO_PATH, model_type=\"simclr\", dataset_type=dataset_type,\n",
" verbose=verbose\n",
" )\n",
"\n",
" encoders = [supervised_encoder, random_encoder, vae_encoder, simclr_encoder]\n",
" freeze_features = [False, True, True, True]\n",
" encoder_labels = [\"supervised\", \"random\", \"VAE\", \"SimCLR\"]\n",
"\n",
" num_clf_epochs = [80, 30, 30, 30]\n",
" print(f\"\\nTraining supervised encoder and classifier for {num_clf_epochs[0]} \"\n",
" f\"epochs, and all other classifiers for {num_clf_epochs[1]} epochs each.\")\n",
" _ = models.train_encoder_clfs_by_fraction_labelled(\n",
" encoders=encoders,\n",
" dataset=dSprites_torchdataset,\n",
" train_sampler=train_sampler,\n",
" test_sampler=test_sampler,\n",
" num_epochs=num_clf_epochs,\n",
" freeze_features=freeze_features,\n",
" subset_seed=SEED,\n",
" encoder_labels=encoder_labels,\n",
" title=title,\n",
" verbose=verbose\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Here, we use a **biased training data sampler** (and unbiased control sampler) to observe how the different models perform. Because the dataset is much smaller, we increase the number of pre-trained and training epochs for the encoders and classifiers.\n",
"\n",
"Let us start with our **unbiased control sampler**, to get a sense of the classification performance levels we should expect with a dataset this size."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"print(\"Training all models using the control, unbiased training dataset\\n\")\n",
"full_training_procedure(\n",
" train_sampler_bias_ctrl, test_sampler_for_bias_ctrl,\n",
" title=\"Classifier performances with control, unbiased training dataset\",\n",
" dataset_type=\"bias_ctrl\" # For loading correct pre-trained networks\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"A similar pattern is observed here as with the full dataset, though notably most performances are a bit weaker, likely due to us (A) using a smaller training dataset, and (B) training and pre-training for fewer iterations, considering the dataset size, for time-efficiency reasons.\n",
"\n",
"Using the same parameters, we now repeat the analysis with the **biased** training data sampler."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"print(\"Training all models using the biased training dataset\\n\")\n",
"full_training_procedure(\n",
" train_sampler_biased, test_sampler_for_biased,\n",
" title=\"Classifier performances with biased training dataset\",\n",
" dataset_type=\"biased\" # For loading correct pre-trained networks\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Interestingly, the SimCLR network encoder is not only the only network to perform well, it even outperforms its control performance (which uses the same test dataset), at least with this particular dataset and biasing.\n",
"\n",
"_**Note on performance improvement:** This improvement for the SimCLR encoder is reflected in the pre-training loss curves (not shown here), which show that the encoder trained with the biased dataset learns faster than the encoder trained with the unbiased training set. It is possible that the dataset biasing, by reducing the variability in the dataset, makes the contrastive task easier, thus enabling the network to learn a good feature space for the classification task in fewer epochs_"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 7.1.1: How do different models cope with a biased training dataset?\n",
"\n",
"**A.** Which models are most and least affected by the biased training dataset?\n",
"**B.** Which types of images in the test set are most likely causing the observed drop in performance?\n",
"**C.** Why are certain models more robust to the bias introduced here than others?\n",
"**D.** What are some methods we can employ to help mitigate the negative effects of biases in our training sets on our ability to learn good data representations with our models?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_a25cd7d9.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Biased_training_dataset_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Discussion 7.1.2: How do these principles apply more generally?\n",
"\n",
"We have seen now how self-supervised learning (SSL) can improve a network's ability to learn good representations of data. For the purposes of this tutorial, we presented examples with a **simplified dataset**: the dSprites dataset, where we know:\n",
"(1) The latent dimensions for all images,\n",
"(2) The joint probability distribution across latent dimensions for the full dataset, and\n",
"(3) The precise nature of the bias introduced into our biased dataset **(see Bonus 2 for more details)**.\n",
"\n",
"As a result, it is quite simple to design data augmentations that ensure that the pre-trained encoder will learn a good feature space for the downstream classification task.\n",
"
\n",
"In real-world applications, with more complex or difficult datasets,\n",
"**A.** What principles can we draw on to successfully apply SSL to learn good data representations in feature space? For example,\n",
"**B.** What challenges might we face with new datasets, compared to applying SSL to dSprites?\n",
"**C.** What types of augmentations might we use when working with non visual datasets, e.g., a speech dataset. In addition, we primarily discussed **only one type of SSL, namely SimCLR**. However, many different types of SSL exist, some of which do not use explicit data augmentations.
\n",
"**D.** What type of SSL task could be implemented for **sequential or time series** data. For example, you might wish to predict from electrical brain recordings what stage of sleep a person is in. How might you use the knowledge that sleep stages change slowly in time to construct a useful SSL task?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_118e3873.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_General_Principles_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Summary"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 8: Conclusion\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 8: Conclusion\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'tvZzYfi_bTI'), ('Bilibili', 'BV1Tq4y1X7e1')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Conclusion_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Daily survey\n",
"\n",
"Don't forget to complete your reflections and content check in the daily survey! Please be patient after logging in as there is a small delay before you will be redirected to the survey.\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus 1: Self-supervised networks learn representation invariance\n",
"\n",
"*Time estimate: ~20mins*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 9: Invariant Representations\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 9: Invariant Representations\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'f8FCk519-lI'), ('Bilibili', 'BV1Ry4y1L7Hz')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Invariant_Representations_Bonus_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus 1.1: The effects of using data transformations on invariance in SimCLR network representations"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We now observe the effects of adding our data transformations on the invariance learned by a pre-trained SimCLR network encoder."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Interactive Demo 1.1.1: Visualizing the SimCLR network encoder RSMs, organized along different latent dimensions\n",
"\n",
"We will now compare the pre-trained SimCLR encoder network RSM to the previously generated encoder RSMs.\n",
"\n",
"Again, we pass `dSprites_torchdataset` instead of `dSprites_invariance_torchdataset`, as we are interested in the RSMs for the real dSprites images, and not their augmentations.\n",
"\n",
"**Interactive Demo:** Visualize the RSMs, organized along different latent dimensions (`\"scale\"`, `\"orientation\"`, `\"posX\"` or `\"posY\"`), and compare the patterns observed for the different encoder networks. (The original setting is `sorting_latent=\"shape\"`.)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"sorting_latent = \"shape\" # DEMO: Try sorting by different latent dimensions\n",
"print(\"Plotting RSMs...\")\n",
"_ = models.plot_model_RSMs(\n",
" encoders=[supervised_encoder, vae_encoder, simclr_encoder],\n",
" dataset=dSprites_torchdataset,\n",
" sampler=test_sampler, # To see the representations on the held out test set\n",
" titles=[\"Supervised network encoder RSM\", \"VAE network encoder RSM\",\n",
" \"SimCLR network encoder RSM\"], # Plot titles\n",
" sorting_latent=sorting_latent\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_SimCLR_network_encoder_RSMs_Bonus_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Discussion 1.1.1: What can we conclude about the ability of contrastive models like SimCLR to construct a meaningful representation space?\n",
"\n",
"**A.** How do the pre-trained SimCLR encoder RSMs (sorted along different latent dimensions) compare to the supervised and pre-trained VAE encoder network RSMs?\n",
"**B.** What explains these different RSMs?\n",
"**C.** What advantages might some encoders have over others?\n",
"**D.** Does a good performance by the SimCLR encoder on a contrastive task guarantee good performance on a downstream classification task?\n",
"**E.** How might one modify the SimCLR encoder pre-training, for example, if the downstream task were to predict `orientation` instead of `shape`?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" #### Supporting images for Discussion response examples for Bonus 1.1.1: All SimCLR encoder RSMs\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown #### Supporting images for Discussion response examples for Bonus 1.1.1: All SimCLR encoder RSMs\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"rsms_simclr_encoder_60ep_bs1000_deg90_trans0-2_scale0-8to1-2_seed2021.png\"), width=1000)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_5d3ad579.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Contrastive_models_Bonus_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus 2: Avoiding representational collapse\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 10: Avoiding Representational Collapse\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 10: Avoiding Representational Collapse\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'fS2BAKVdpIY'), ('Bilibili', 'BV1Gv411E7xe')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Avoiding_Representational_Collapse_Bonus_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus 2.1: The effects of reducing the number of negative examples used in the SimCLR contrastive loss"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As seen above in the contrastive loss implementation, a strategy used to train neural networks with contrastive losses is to use large batch sizes (here, we used 1,000 examples per batch), and to use the representations of different images in a batch as **each other's negative examples**. So with a batch size of 1,000, each image has one positive paired image (its paired augmentation), and 999 negative paired images (every image but itself, including its own paired augmentation, again). This enables the contrastive loss to obtain a good estimate of the full representational similarity distribution.\n",
"\n",
"To observe the consequences of sampling using fewer negative examples in the contrastive loss, we use a pre-trained SimCLR network again. However, this one was pre-trained with a parameter called `neg_pairs` set to `2`. Under the hood, this parameter affects only the contrastive loss calculation, allowing it to use **only 2 of the total available negative pairs in a batch, for each image.**"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The following code:\n",
"* Loads the parameters of a SimCLR network pre-trained on the SimCLR contrastive task, but with only 2 negative pairs used per image in the loss calculation, using `load.load_encoder()`,\n",
"* Plots the RSMs of a few network encoders for comparison."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"# Load SimCLR encoder pre-trained on the contrastive loss\n",
"simclr_encoder_neg_pairs = load.load_encoder(\n",
" REPO_PATH, model_type=\"simclr\", neg_pairs=2\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Coding Exercise 2.1.1: Visualizing the network encoder RSMs, organized along different latent dimensions, and plotting similarity histograms\n",
"\n",
"We will now compare the RSM for the pre-trained SimCLR encoder trained with **only 2 negative pairs** to the normal pre-trained SimCLR network encoder and the random network encoder. To help us compare the representations learned by the normal and modified SimCLR encoders, we will plot a histogram of the values that make up both RSMs.\n",
"\n",
"**Exercise:**\n",
"* Visualize the RSMs, organized along the `shape` latent dimension, and compare the patterns observed for the different encoder networks.\n",
"* Plot a histogram of RSM values for the normal and 2-neg-pair SimCLR network encoders.\n",
"\n",
"**Hint**:\n",
"* `models.plot_model_RSMs()` returns the **data matrices** calculated for each encoder's RSM, in order."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def rsms_and_histogram_plot():\n",
" \"\"\"\n",
" Function to plot Representational Similarity Matrices (RSMs) and Histograms\n",
"\n",
" Args:\n",
" None\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" sorting_latent = \"shape\" # Exercise: Try sorting by different latent dimensions\n",
" # EXERCISE: Visualize RSMs for the normal SimCLR, 2-neg-pair SimCLR and random network encoders.\n",
" print(\"Plotting RSMs...\")\n",
" simclr_rsm, simclr_neg_pairs_rsm, random_rsm = models.plot_model_RSMs(\n",
" encoders=[simclr_encoder, simclr_encoder_neg_pairs, random_encoder],\n",
" dataset=dSprites_torchdataset,\n",
" sampler=test_sampler, # To see the representations on the held out test set\n",
" titles=[\"SimCLR network encoder RSM\",\n",
" f\"SimCLR network encoder RSM\\n(2 negative pairs per image used in loss calc.)\",\n",
" \"Random network encoder RSM\"], # Plot titles\n",
" sorting_latent=sorting_latent\n",
" )\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your implementation\n",
" raise NotImplementedError(\"Exercise: Plot histogram.\")\n",
" #################################################\n",
" # Plot a histogram of RSM values for both SimCLR encoders.\n",
" plot_rsm_histogram(\n",
" [..., ...],\n",
" colors=[...],\n",
" labels=[..., ...],\n",
" nbins=100\n",
" )\n",
"\n",
"\n",
"## Uncomment below to test your code\n",
"# rsms_and_histogram_plot()"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_8da89b74.py)\n",
"\n",
"*Example output:*\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus 1: Self-supervised networks learn representation invariance\n",
"\n",
"*Time estimate: ~20mins*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 9: Invariant Representations\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 9: Invariant Representations\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'f8FCk519-lI'), ('Bilibili', 'BV1Ry4y1L7Hz')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Invariant_Representations_Bonus_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus 1.1: The effects of using data transformations on invariance in SimCLR network representations"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We now observe the effects of adding our data transformations on the invariance learned by a pre-trained SimCLR network encoder."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Interactive Demo 1.1.1: Visualizing the SimCLR network encoder RSMs, organized along different latent dimensions\n",
"\n",
"We will now compare the pre-trained SimCLR encoder network RSM to the previously generated encoder RSMs.\n",
"\n",
"Again, we pass `dSprites_torchdataset` instead of `dSprites_invariance_torchdataset`, as we are interested in the RSMs for the real dSprites images, and not their augmentations.\n",
"\n",
"**Interactive Demo:** Visualize the RSMs, organized along different latent dimensions (`\"scale\"`, `\"orientation\"`, `\"posX\"` or `\"posY\"`), and compare the patterns observed for the different encoder networks. (The original setting is `sorting_latent=\"shape\"`.)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"sorting_latent = \"shape\" # DEMO: Try sorting by different latent dimensions\n",
"print(\"Plotting RSMs...\")\n",
"_ = models.plot_model_RSMs(\n",
" encoders=[supervised_encoder, vae_encoder, simclr_encoder],\n",
" dataset=dSprites_torchdataset,\n",
" sampler=test_sampler, # To see the representations on the held out test set\n",
" titles=[\"Supervised network encoder RSM\", \"VAE network encoder RSM\",\n",
" \"SimCLR network encoder RSM\"], # Plot titles\n",
" sorting_latent=sorting_latent\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_SimCLR_network_encoder_RSMs_Bonus_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Discussion 1.1.1: What can we conclude about the ability of contrastive models like SimCLR to construct a meaningful representation space?\n",
"\n",
"**A.** How do the pre-trained SimCLR encoder RSMs (sorted along different latent dimensions) compare to the supervised and pre-trained VAE encoder network RSMs?\n",
"**B.** What explains these different RSMs?\n",
"**C.** What advantages might some encoders have over others?\n",
"**D.** Does a good performance by the SimCLR encoder on a contrastive task guarantee good performance on a downstream classification task?\n",
"**E.** How might one modify the SimCLR encoder pre-training, for example, if the downstream task were to predict `orientation` instead of `shape`?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" #### Supporting images for Discussion response examples for Bonus 1.1.1: All SimCLR encoder RSMs\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown #### Supporting images for Discussion response examples for Bonus 1.1.1: All SimCLR encoder RSMs\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"rsms_simclr_encoder_60ep_bs1000_deg90_trans0-2_scale0-8to1-2_seed2021.png\"), width=1000)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_5d3ad579.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Contrastive_models_Bonus_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus 2: Avoiding representational collapse\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 10: Avoiding Representational Collapse\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 10: Avoiding Representational Collapse\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'fS2BAKVdpIY'), ('Bilibili', 'BV1Gv411E7xe')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Avoiding_Representational_Collapse_Bonus_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus 2.1: The effects of reducing the number of negative examples used in the SimCLR contrastive loss"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As seen above in the contrastive loss implementation, a strategy used to train neural networks with contrastive losses is to use large batch sizes (here, we used 1,000 examples per batch), and to use the representations of different images in a batch as **each other's negative examples**. So with a batch size of 1,000, each image has one positive paired image (its paired augmentation), and 999 negative paired images (every image but itself, including its own paired augmentation, again). This enables the contrastive loss to obtain a good estimate of the full representational similarity distribution.\n",
"\n",
"To observe the consequences of sampling using fewer negative examples in the contrastive loss, we use a pre-trained SimCLR network again. However, this one was pre-trained with a parameter called `neg_pairs` set to `2`. Under the hood, this parameter affects only the contrastive loss calculation, allowing it to use **only 2 of the total available negative pairs in a batch, for each image.**"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The following code:\n",
"* Loads the parameters of a SimCLR network pre-trained on the SimCLR contrastive task, but with only 2 negative pairs used per image in the loss calculation, using `load.load_encoder()`,\n",
"* Plots the RSMs of a few network encoders for comparison."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"# Load SimCLR encoder pre-trained on the contrastive loss\n",
"simclr_encoder_neg_pairs = load.load_encoder(\n",
" REPO_PATH, model_type=\"simclr\", neg_pairs=2\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Coding Exercise 2.1.1: Visualizing the network encoder RSMs, organized along different latent dimensions, and plotting similarity histograms\n",
"\n",
"We will now compare the RSM for the pre-trained SimCLR encoder trained with **only 2 negative pairs** to the normal pre-trained SimCLR network encoder and the random network encoder. To help us compare the representations learned by the normal and modified SimCLR encoders, we will plot a histogram of the values that make up both RSMs.\n",
"\n",
"**Exercise:**\n",
"* Visualize the RSMs, organized along the `shape` latent dimension, and compare the patterns observed for the different encoder networks.\n",
"* Plot a histogram of RSM values for the normal and 2-neg-pair SimCLR network encoders.\n",
"\n",
"**Hint**:\n",
"* `models.plot_model_RSMs()` returns the **data matrices** calculated for each encoder's RSM, in order."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def rsms_and_histogram_plot():\n",
" \"\"\"\n",
" Function to plot Representational Similarity Matrices (RSMs) and Histograms\n",
"\n",
" Args:\n",
" None\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" sorting_latent = \"shape\" # Exercise: Try sorting by different latent dimensions\n",
" # EXERCISE: Visualize RSMs for the normal SimCLR, 2-neg-pair SimCLR and random network encoders.\n",
" print(\"Plotting RSMs...\")\n",
" simclr_rsm, simclr_neg_pairs_rsm, random_rsm = models.plot_model_RSMs(\n",
" encoders=[simclr_encoder, simclr_encoder_neg_pairs, random_encoder],\n",
" dataset=dSprites_torchdataset,\n",
" sampler=test_sampler, # To see the representations on the held out test set\n",
" titles=[\"SimCLR network encoder RSM\",\n",
" f\"SimCLR network encoder RSM\\n(2 negative pairs per image used in loss calc.)\",\n",
" \"Random network encoder RSM\"], # Plot titles\n",
" sorting_latent=sorting_latent\n",
" )\n",
" #################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your implementation\n",
" raise NotImplementedError(\"Exercise: Plot histogram.\")\n",
" #################################################\n",
" # Plot a histogram of RSM values for both SimCLR encoders.\n",
" plot_rsm_histogram(\n",
" [..., ...],\n",
" colors=[...],\n",
" labels=[..., ...],\n",
" nbins=100\n",
" )\n",
"\n",
"\n",
"## Uncomment below to test your code\n",
"# rsms_and_histogram_plot()"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_8da89b74.py)\n",
"\n",
"*Example output:*\n",
"\n",
"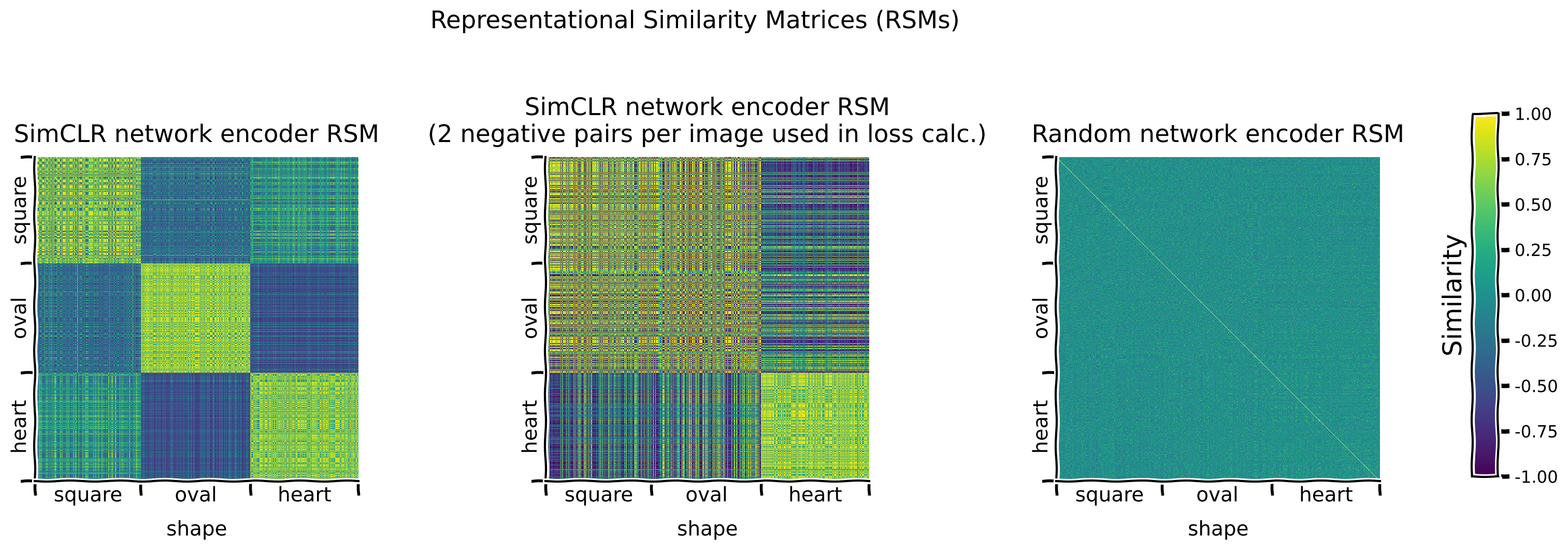 \n",
"\n",
"
\n",
"\n",
"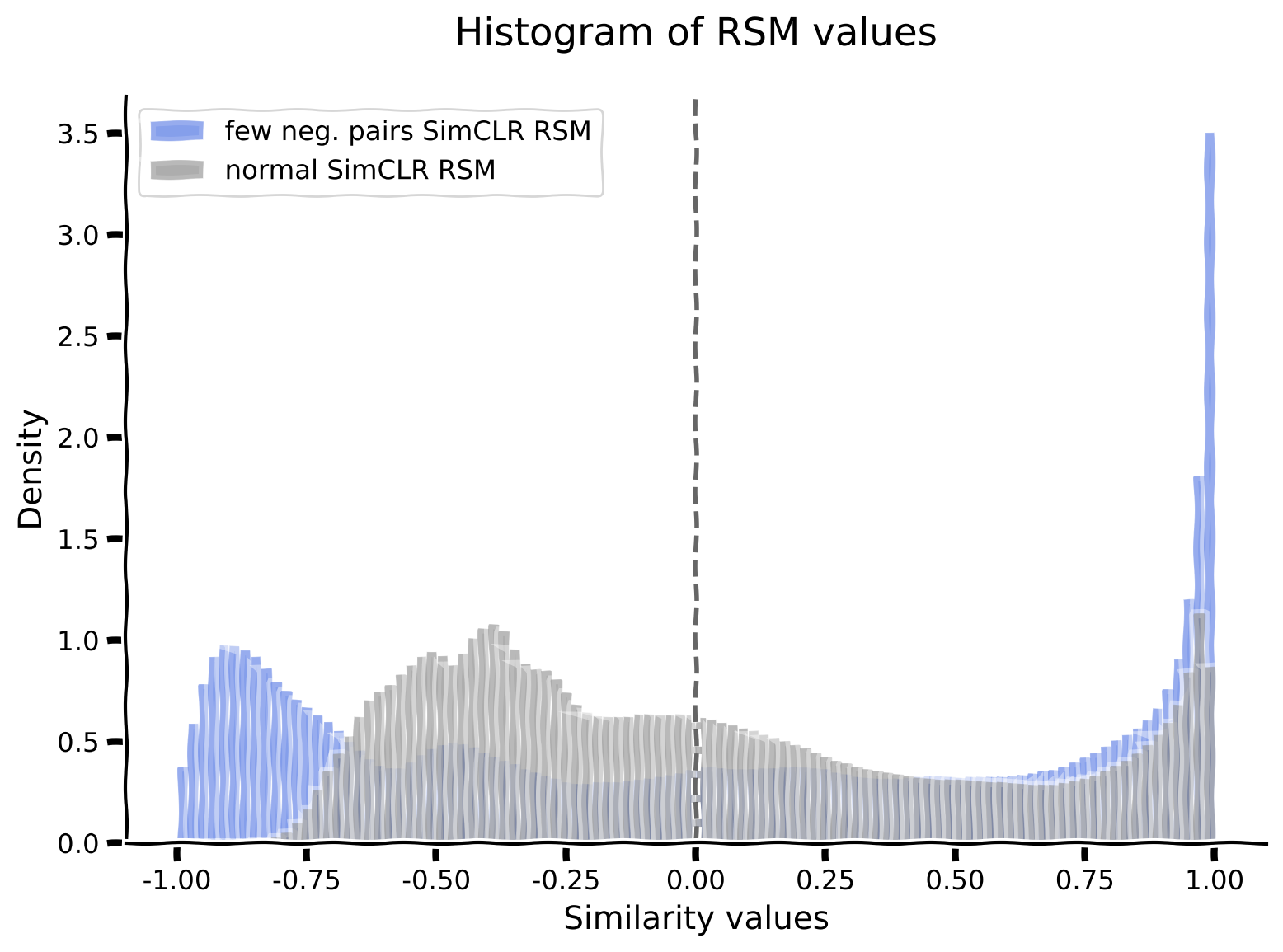 \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Visualizing_the_network_encoder_RSMs_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Interactive Demo 2.1.1: Evaluating the classification performance of a logistic regression trained on the representations produced by a SimCLR network encoder pre-trained with only a few negative pairs\n",
"\n",
"For the 2-neg-pair SimCLR encoder, as the encoder parameters have already been trained, they should again be kept frozen while the classifier is trained by setting `freeze_features=True`.\n",
"\n",
"_**Interactive Demo:** Try different numbers of epochs for which to train the classifier. (The original setting is `num_epochs=25`.)_"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"print(\"Training a classifier on the representations learned by the SimCLR \"\n",
" \"network encoder pre-trained\\nusing only 2 negative pairs per image \"\n",
" \"for the loss calculation...\")\n",
"_, simclr_neg_pairs_loss_array, _, _ = models.train_classifier(\n",
" encoder=simclr_encoder_neg_pairs,\n",
" dataset=dSprites_torchdataset,\n",
" train_sampler=train_sampler,\n",
" test_sampler=test_sampler,\n",
" freeze_features=True, # Keep the encoder frozen while training the classifier\n",
" num_epochs=50, # DEMO: Try different numbers of epochs\n",
" verbose=True\n",
" )\n",
"\n",
"# Plot the loss array\n",
"fig, ax = plt.subplots()\n",
"ax.plot(simclr_neg_pairs_loss_array)\n",
"ax.set_title((\"Loss of classifier trained on a SimCLR encoder\\n\"\n",
"\"trained with 2 negative pairs only.\"))\n",
"ax.set_xlabel(\"Epoch number\")\n",
"_ = ax.set_ylabel(\"Training loss\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Discussion 2.1.1: What can we conclude about the importance of negative pairs in computing the contrastive loss for models like SimCLR?\n",
"\n",
"**A.** How does changing the number of negative pairs affect the networks' RSMs?\n",
"**B.** How is the shape classifier likely to perform when the encoder is pre-trained with very few negative pairs?\n",
"**C.** What, intuitively, is the role of negative pairs in shaping the feature space that a contrastive model learns, and how does this role relate to the role of positive pairs?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" #### Supporting images for Discussion response examples for Bonus 2.1.1: All SimCLR encoder (2 neg. pairs) RSMs\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown #### Supporting images for Discussion response examples for Bonus 2.1.1: All SimCLR encoder (2 neg. pairs) RSMs\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"rsms_simclr_encoder_2neg_60ep_bs1000_deg90_trans0-2_scale0-8to1-2_seed2021.png\"), width=1000)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_205ec8fe.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Negative_pairs_in_computing_the_contrastive_loss_Bonus_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_SimCLR_network_encoder_pretrained_with_only_a_few_negative_pairs_Bonus_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"After dropping the number of negative pairs used per image in pre-training a SimCLR encoder, classification accuracy drops to 66.75% on the test dataset, even after 50 classifier training epochs."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Shape classification results using different feature encoders:\n",
"\n",
"| _Chance_ | | None (raw data) | Supervised | Random | VAE | SimCLR | SimCLR (few neg.pairs) |\n",
"| - | - | --- | --- | --- | --- | --- | --- |\n",
"| _33.33%_ | | 39.55% | 98.70% | 44.67% | 45.75% | 97.53% | 66.75% |"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus 3: Good representations enable few-shot learning\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 11: Few-shot Supervised Learning\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 11: Few-shot Supervised Learning\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'okrvQDeN2cc'), ('Bilibili', 'BV1BP4y147fs')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_FewShot_Supervised_learning_Bonus_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus 3.1: The benefits of pre-training an encoder network in a few-short learning scenario, i.e., when only few labelled examples are available"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The toy dataset we have been using, **dSprites**, is thoroughly labelled along 5 different dimensions. However, this is not the case for many datasets. Some very large datasets may have few if any labels.\n",
"\n",
"One of our last steps is to examine how each of our models perform in such a case when only few labelled images are available for training. In this scenario, we will train classifiers on different fractions of the training data (between 0.01 and 1.0), and see how they perform on the test set.\n",
"\n",
"For the different types of encoder, this means:\n",
"* **Supervised encoder:** As the supervised encoder can only be trained with labels, we will start from random encoders and train them end-to-end on the classification task with the fraction of labelled images allowed.\n",
"_**Note on * symbol:** Given that that network is trained end-to-end, we will train it for more epochs, and mark it with \"\\*\" in the graphs._\n",
"* **Random encoder:** By definition, the random encoder is untrained.\n",
"* **VAE encoder**: As a generative model can be pre-trained on unlabelled data, we will use the VAE encoder pre-trained on the reconstruction task using the full dataset, before training the classifier layer with the fraction of labelled images allowed.\n",
"* **SimCLR encoder**: As an SSL model can be pre-trained on unlabelled data, we will use the SimCLR encoder pre-trained on the contrastive task using the full dataset, before training the classifier layer with the fraction of labelled images allowed.\n",
"\n",
"_**Note on number of training epochs:** The numbers of epochs are specified below for when the **full training dataset** is used. For each fraction of the dataset a classifier is trained on, the **number of training epochs is scaled up** to compensate for the drop in number of training examples. For example, if we specify 10 epochs for a model, the 0.1 fraction labelled classifier will be trained over ~30 epochs. Also, we use **slightly fewer epochs** than above, here, in the interest of time._"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Interactive Demo 3.1.1: Training classifiers on different encoders, using only a fraction of the full labelled dataset\n",
"\n",
"In this demo, we select a few fractions (4 to 6) of the full labelled dataset with which to train the classifiers.\n",
"\n",
"_**Interactive Demo:** Set `labelled_fractions` argument to a list of fractions (4 to 6 values between 0.01 and 1.0) with which to train classifiers for each encoder._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"new_supervised_encoder = models.EncoderCore() # New, random supervised encoder\n",
"\n",
"_ = models.train_encoder_clfs_by_fraction_labelled(\n",
" encoders=[new_supervised_encoder, random_encoder, vae_encoder, simclr_encoder],\n",
" dataset=dSprites_torchdataset,\n",
" train_sampler=train_sampler,\n",
" test_sampler=test_sampler,\n",
" labelled_fractions=[0.01], # DEMO: select 4-6 fractions to run\n",
" num_epochs=[20, 8, 8, 8], # Train the supervised network (end-to-end) for more epochs\n",
" freeze_features=[False, True, True, True], # Only train new supervised network end-to-end\n",
" subset_seed=SEED,\n",
" encoder_labels=[\"supervised\", \"random\", \"VAE\", \"SimCLR\"],\n",
" title=\"Performance of classifiers trained\\nwith different network encoders\",\n",
" verbose=True\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Use_a_fraction_of_the_labelled_dataset_Bonus_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Discussion 3.1.1: What can we conclude the advantages and disadvantages of the different encoder network types under different conditions?\n",
"\n",
"**A.** Which models are most and least affected by how much labelled data is available?\n",
"**B.** What might explain why different models are affected differently?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" #### Supporting images for Discussion response examples for Bonus 3.1.1: Classifier performances for various fractions of labelled data\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown #### Supporting images for Discussion response examples for Bonus 3.1.1: Classifier performances for various fractions of labelled data\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"labelled_fractions.png\"), width=600)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_e5b876cb.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Advantages_and_disadvantages_of_encoders_Bonus_Discussion\")"
]
}
],
"metadata": {
"accelerator": "GPU",
"colab": {
"collapsed_sections": [],
"include_colab_link": true,
"name": "W3D3_Tutorial1",
"provenance": [],
"toc_visible": true
},
"kernel": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
},
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Visualizing_the_network_encoder_RSMs_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Interactive Demo 2.1.1: Evaluating the classification performance of a logistic regression trained on the representations produced by a SimCLR network encoder pre-trained with only a few negative pairs\n",
"\n",
"For the 2-neg-pair SimCLR encoder, as the encoder parameters have already been trained, they should again be kept frozen while the classifier is trained by setting `freeze_features=True`.\n",
"\n",
"_**Interactive Demo:** Try different numbers of epochs for which to train the classifier. (The original setting is `num_epochs=25`.)_"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"print(\"Training a classifier on the representations learned by the SimCLR \"\n",
" \"network encoder pre-trained\\nusing only 2 negative pairs per image \"\n",
" \"for the loss calculation...\")\n",
"_, simclr_neg_pairs_loss_array, _, _ = models.train_classifier(\n",
" encoder=simclr_encoder_neg_pairs,\n",
" dataset=dSprites_torchdataset,\n",
" train_sampler=train_sampler,\n",
" test_sampler=test_sampler,\n",
" freeze_features=True, # Keep the encoder frozen while training the classifier\n",
" num_epochs=50, # DEMO: Try different numbers of epochs\n",
" verbose=True\n",
" )\n",
"\n",
"# Plot the loss array\n",
"fig, ax = plt.subplots()\n",
"ax.plot(simclr_neg_pairs_loss_array)\n",
"ax.set_title((\"Loss of classifier trained on a SimCLR encoder\\n\"\n",
"\"trained with 2 negative pairs only.\"))\n",
"ax.set_xlabel(\"Epoch number\")\n",
"_ = ax.set_ylabel(\"Training loss\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Discussion 2.1.1: What can we conclude about the importance of negative pairs in computing the contrastive loss for models like SimCLR?\n",
"\n",
"**A.** How does changing the number of negative pairs affect the networks' RSMs?\n",
"**B.** How is the shape classifier likely to perform when the encoder is pre-trained with very few negative pairs?\n",
"**C.** What, intuitively, is the role of negative pairs in shaping the feature space that a contrastive model learns, and how does this role relate to the role of positive pairs?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" #### Supporting images for Discussion response examples for Bonus 2.1.1: All SimCLR encoder (2 neg. pairs) RSMs\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown #### Supporting images for Discussion response examples for Bonus 2.1.1: All SimCLR encoder (2 neg. pairs) RSMs\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"rsms_simclr_encoder_2neg_60ep_bs1000_deg90_trans0-2_scale0-8to1-2_seed2021.png\"), width=1000)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_205ec8fe.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Negative_pairs_in_computing_the_contrastive_loss_Bonus_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_SimCLR_network_encoder_pretrained_with_only_a_few_negative_pairs_Bonus_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"After dropping the number of negative pairs used per image in pre-training a SimCLR encoder, classification accuracy drops to 66.75% on the test dataset, even after 50 classifier training epochs."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Shape classification results using different feature encoders:\n",
"\n",
"| _Chance_ | | None (raw data) | Supervised | Random | VAE | SimCLR | SimCLR (few neg.pairs) |\n",
"| - | - | --- | --- | --- | --- | --- | --- |\n",
"| _33.33%_ | | 39.55% | 98.70% | 44.67% | 45.75% | 97.53% | 66.75% |"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus 3: Good representations enable few-shot learning\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 11: Few-shot Supervised Learning\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 11: Few-shot Supervised Learning\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'okrvQDeN2cc'), ('Bilibili', 'BV1BP4y147fs')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_FewShot_Supervised_learning_Bonus_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus 3.1: The benefits of pre-training an encoder network in a few-short learning scenario, i.e., when only few labelled examples are available"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The toy dataset we have been using, **dSprites**, is thoroughly labelled along 5 different dimensions. However, this is not the case for many datasets. Some very large datasets may have few if any labels.\n",
"\n",
"One of our last steps is to examine how each of our models perform in such a case when only few labelled images are available for training. In this scenario, we will train classifiers on different fractions of the training data (between 0.01 and 1.0), and see how they perform on the test set.\n",
"\n",
"For the different types of encoder, this means:\n",
"* **Supervised encoder:** As the supervised encoder can only be trained with labels, we will start from random encoders and train them end-to-end on the classification task with the fraction of labelled images allowed.\n",
"_**Note on * symbol:** Given that that network is trained end-to-end, we will train it for more epochs, and mark it with \"\\*\" in the graphs._\n",
"* **Random encoder:** By definition, the random encoder is untrained.\n",
"* **VAE encoder**: As a generative model can be pre-trained on unlabelled data, we will use the VAE encoder pre-trained on the reconstruction task using the full dataset, before training the classifier layer with the fraction of labelled images allowed.\n",
"* **SimCLR encoder**: As an SSL model can be pre-trained on unlabelled data, we will use the SimCLR encoder pre-trained on the contrastive task using the full dataset, before training the classifier layer with the fraction of labelled images allowed.\n",
"\n",
"_**Note on number of training epochs:** The numbers of epochs are specified below for when the **full training dataset** is used. For each fraction of the dataset a classifier is trained on, the **number of training epochs is scaled up** to compensate for the drop in number of training examples. For example, if we specify 10 epochs for a model, the 0.1 fraction labelled classifier will be trained over ~30 epochs. Also, we use **slightly fewer epochs** than above, here, in the interest of time._"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Interactive Demo 3.1.1: Training classifiers on different encoders, using only a fraction of the full labelled dataset\n",
"\n",
"In this demo, we select a few fractions (4 to 6) of the full labelled dataset with which to train the classifiers.\n",
"\n",
"_**Interactive Demo:** Set `labelled_fractions` argument to a list of fractions (4 to 6 values between 0.01 and 1.0) with which to train classifiers for each encoder._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Call this before any dataset/network initializing or training,\n",
"# to ensure reproducibility\n",
"set_seed(SEED)\n",
"\n",
"new_supervised_encoder = models.EncoderCore() # New, random supervised encoder\n",
"\n",
"_ = models.train_encoder_clfs_by_fraction_labelled(\n",
" encoders=[new_supervised_encoder, random_encoder, vae_encoder, simclr_encoder],\n",
" dataset=dSprites_torchdataset,\n",
" train_sampler=train_sampler,\n",
" test_sampler=test_sampler,\n",
" labelled_fractions=[0.01], # DEMO: select 4-6 fractions to run\n",
" num_epochs=[20, 8, 8, 8], # Train the supervised network (end-to-end) for more epochs\n",
" freeze_features=[False, True, True, True], # Only train new supervised network end-to-end\n",
" subset_seed=SEED,\n",
" encoder_labels=[\"supervised\", \"random\", \"VAE\", \"SimCLR\"],\n",
" title=\"Performance of classifiers trained\\nwith different network encoders\",\n",
" verbose=True\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Use_a_fraction_of_the_labelled_dataset_Bonus_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Discussion 3.1.1: What can we conclude the advantages and disadvantages of the different encoder network types under different conditions?\n",
"\n",
"**A.** Which models are most and least affected by how much labelled data is available?\n",
"**B.** What might explain why different models are affected differently?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" #### Supporting images for Discussion response examples for Bonus 3.1.1: Classifier performances for various fractions of labelled data\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown #### Supporting images for Discussion response examples for Bonus 3.1.1: Classifier performances for various fractions of labelled data\n",
"Image(filename=os.path.join(REPO_PATH, \"images\", \"labelled_fractions.png\"), width=600)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W3D3_UnsupervisedAndSelfSupervisedLearning/solutions/W3D3_Tutorial1_Solution_e5b876cb.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Advantages_and_disadvantages_of_encoders_Bonus_Discussion\")"
]
}
],
"metadata": {
"accelerator": "GPU",
"colab": {
"collapsed_sections": [],
"include_colab_link": true,
"name": "W3D3_Tutorial1",
"provenance": [],
"toc_visible": true
},
"kernel": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
},
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}