{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {},
"id": "view-in-github"
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 1: Introduction to CNNs\n",
"\n",
"**Week 2, Day 2: Convnets and DL Thinking**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"__Content creators:__ Dawn Estes McKnight, Richard Gerum, Cassidy Pirlot, Rohan Saha, Liam Peet-Pare, Saeed Najafi, Alona Fyshe\n",
"\n",
"__Content reviewers:__ Saeed Salehi, Lily Cheng, Yu-Fang Yang, Polina Turishcheva, Bettina Hein, Kelson Shilling-Scrivo\n",
"\n",
"__Content editors:__ Gagana B, Nina Kudryashova, Anmol Gupta, Xiaoxiong Lin, Spiros Chavlis\n",
"\n",
"__Production editors:__ Alex Tran-Van-Minh, Gagana B, Spiros Chavlis\n",
"\n",
" \n",
"\n",
"*Based on material from:* Konrad Kording, Hmrishav Bandyopadhyay, Rahul Shekhar, Tejas Srivastava"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Tutorial Objectives\n",
"At the end of this tutorial, we will be able to:\n",
"- Define what convolution is\n",
"- Implement convolution as an operation\n",
"\n",
"In the Bonus materials of this tutorial, you will be able to:\n",
"\n",
"- Train a CNN by writing your own train loop\n",
"- Recognize the symptoms of overfitting and how to cure them\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @markdown\n",
"from IPython.display import IFrame\n",
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/s8xz5/\")\n",
" display(IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/s8xz5/?direct%26mode=render%26action=download%26mode=render\", width=730, height=410))\n",
"display(out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Setup"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install dependencies\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install dependencies\n",
"!pip install Pillow --quiet"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and import feedback gadget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install and import feedback gadget\n",
"\n",
"!pip3 install vibecheck datatops --quiet\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
" return DatatopsContentReviewContainer(\n",
" \"\", # No text prompt\n",
" notebook_section,\n",
" {\n",
" \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
" \"name\": \"neuromatch_dl\",\n",
" \"user_key\": \"f379rz8y\",\n",
" },\n",
" ).render()\n",
"\n",
"\n",
"feedback_prefix = \"W2D2_T1\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Imports\n",
"import time\n",
"import torch\n",
"import scipy.signal\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"\n",
"import torch.nn as nn\n",
"import torch.nn.functional as F\n",
"\n",
"import torchvision.transforms as transforms\n",
"import torchvision.datasets as datasets\n",
"from torch.utils.data import DataLoader\n",
"\n",
"from tqdm.notebook import tqdm, trange\n",
"from PIL import Image"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure Settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure Settings\n",
"import logging\n",
"logging.getLogger('matplotlib.font_manager').disabled = True\n",
"\n",
"import ipywidgets as widgets # Interactive display\n",
"%matplotlib inline\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/content-creation/main/nma.mplstyle\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Helper functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Helper functions\n",
"from scipy.signal import correlate2d\n",
"import zipfile, gzip, shutil, tarfile\n",
"\n",
"\n",
"def download_data(fname, folder, url, tar):\n",
" \"\"\"\n",
" Data downloading from OSF.\n",
"\n",
" Args:\n",
" fname : str\n",
" The name of the archive\n",
" folder : str\n",
" The name of the destination folder\n",
" url : str\n",
" The download url\n",
" tar : boolean\n",
" `tar=True` the archive is `fname`.tar.gz, `tar=False` is `fname`.zip\n",
"\n",
" Returns:\n",
" Nothing.\n",
" \"\"\"\n",
"\n",
" if not os.path.exists(folder):\n",
" print(f'\\nDownloading {folder} dataset...')\n",
" r = requests.get(url, allow_redirects=True)\n",
" with open(fname, 'wb') as fh:\n",
" fh.write(r.content)\n",
" print(f'\\nDownloading {folder} completed.')\n",
"\n",
" print('\\nExtracting the files...\\n')\n",
" if not tar:\n",
" with zipfile.ZipFile(fname, 'r') as fz:\n",
" fz.extractall()\n",
" else:\n",
" with tarfile.open(fname) as ft:\n",
" ft.extractall()\n",
" # Remove the archive\n",
" os.remove(fname)\n",
"\n",
" # Extract all .gz files\n",
" foldername = folder + '/raw/'\n",
" for filename in os.listdir(foldername):\n",
" # Remove the extension\n",
" fname = filename.replace('.gz', '')\n",
" # Gunzip all files\n",
" with gzip.open(foldername + filename, 'rb') as f_in:\n",
" with open(foldername + fname, 'wb') as f_out:\n",
" shutil.copyfileobj(f_in, f_out)\n",
" os.remove(foldername+filename)\n",
" else:\n",
" print(f'{folder} dataset has already been downloaded.\\n')\n",
"\n",
"\n",
"def check_shape_function(func, image_shape, kernel_shape):\n",
" \"\"\"\n",
" Helper function to check shape implementation\n",
"\n",
" Args:\n",
" func: f.__name__\n",
" Function name\n",
" image_shape: tuple\n",
" Image shape\n",
" kernel_shape: tuple\n",
" Kernel shape\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" correct_shape = correlate2d(np.random.rand(*image_shape), np.random.rand(*kernel_shape), \"valid\").shape\n",
" user_shape = func(image_shape, kernel_shape)\n",
" if correct_shape != user_shape:\n",
" print(f\"❌ Your calculated output shape is not correct.\")\n",
" else:\n",
" print(f\"✅ Output for image_shape: {image_shape} and kernel_shape: {kernel_shape}, output_shape: {user_shape}, is correct.\")\n",
"\n",
"\n",
"def check_conv_function(func, image, kernel):\n",
" \"\"\"\n",
" Helper function to check conv_function\n",
"\n",
" Args:\n",
" func: f.__name__\n",
" Function name\n",
" image: np.ndarray\n",
" Image matrix\n",
" kernel_shape: np.ndarray\n",
" Kernel matrix\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" solution_user = func(image, kernel)\n",
" solution_scipy = correlate2d(image, kernel, \"valid\")\n",
" result_right = (solution_user == solution_scipy).all()\n",
" if result_right:\n",
" print(\"✅ The function calculated the convolution correctly.\")\n",
" else:\n",
" print(\"❌ The function did not produce the right output.\")\n",
" print(\"For the input matrix:\")\n",
" print(image)\n",
" print(\"and the kernel:\")\n",
" print(kernel)\n",
" print(\"the function returned:\")\n",
" print(solution_user)\n",
" print(\"the correct output would be:\")\n",
" print(solution_scipy)\n",
"\n",
"\n",
"def check_pooling_net(net, device='cpu'):\n",
" \"\"\"\n",
" Helper function to check pooling output\n",
"\n",
" Args:\n",
" net: nn.module\n",
" Net instance\n",
" device: string\n",
" GPU/CUDA if available, CPU otherwise.\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" x_img = emnist_train[x_img_idx][0].unsqueeze(dim=0).to(device)\n",
" output_x = net(x_img)\n",
" output_x = output_x.squeeze(dim=0).detach().cpu().numpy()\n",
"\n",
" right_output = [\n",
" [0.000000, 0.000000, 0.000000, 0.000000, 0.000000, 0.000000, 0.000000,\n",
" 0.000000, 0.000000, 0.000000, 0.000000, 0.000000],\n",
" [0.000000, 0.000000, 0.000000, 0.000000, 0.000000, 0.000000, 0.000000,\n",
" 0.000000, 0.000000, 0.000000, 0.000000, 0.000000],\n",
" [9.309552, 1.6216984, 0.000000, 0.000000, 0.000000, 0.000000, 2.2708383,\n",
" 2.6654134, 1.2271233, 0.000000, 0.000000, 0.000000],\n",
" [12.873457, 13.318945, 9.46229, 4.663746, 0.000000, 0.000000, 1.8889914,\n",
" 0.31068993, 0.000000, 0.000000, 0.000000, 0.000000],\n",
" [0.000000, 8.354934, 10.378724, 16.882853, 18.499334, 4.8546696, 0.000000,\n",
" 0.000000, 0.000000, 6.29296, 5.096506, 0.000000],\n",
" [0.000000, 0.000000, 0.31068993, 5.7074604, 9.984148, 4.12916, 8.10037,\n",
" 7.667609, 0.000000, 0.000000, 1.2780352, 0.000000],\n",
" [0.000000, 2.436305, 3.9764223, 0.000000, 0.000000, 0.000000, 12.98801,\n",
" 17.1756, 17.531992, 11.664275, 1.5453291, 0.000000],\n",
" [4.2691708, 2.3217516, 0.000000, 0.000000, 1.3798618, 0.05612564, 0.000000,\n",
" 0.000000, 11.218788, 16.360992, 13.980816, 8.354935],\n",
" [1.8126211, 0.000000, 0.000000, 2.9199777, 3.9382377, 0.000000, 0.000000,\n",
" 0.000000, 0.000000, 0.000000, 6.076582, 10.035061],\n",
" [0.000000, 0.92164516, 4.434638, 0.7816348, 0.000000, 0.000000, 0.000000,\n",
" 0.000000, 0.000000, 0.000000, 0.000000, 0.83254766],\n",
" [0.000000, 0.000000, 0.000000, 0.000000, 0.000000, 0.000000, 0.000000,\n",
" 0.000000, 0.000000, 0.000000, 0.000000, 0.000000],\n",
" [0.000000, 0.000000, 0.000000, 0.000000, 0.000000, 0.000000, 0.000000,\n",
" 0.000000, 0.000000, 0.000000, 0.000000, 0.000000]\n",
" ]\n",
"\n",
" right_shape = (3, 12, 12)\n",
"\n",
" if output_x.shape != right_shape:\n",
" print(f\"❌ Your output does not have the right dimensions. Your output is {output_x.shape} the expected output is {right_shape}\")\n",
" elif (output_x[0] != right_output).all():\n",
" print(\"❌ Your output is not right.\")\n",
" else:\n",
" print(\"✅ Your network produced the correct output.\")\n",
"\n",
"\n",
"# Just returns accuracy on test data\n",
"def test(model, device, data_loader):\n",
" \"\"\"\n",
" Test function\n",
"\n",
" Args:\n",
" net: nn.module\n",
" Net instance\n",
" device: string\n",
" GPU/CUDA if available, CPU otherwise.\n",
" data_loader: torch.loader\n",
" Test loader\n",
"\n",
" Returns:\n",
" acc: float\n",
" Test accuracy\n",
" \"\"\"\n",
" model.eval()\n",
" correct = 0\n",
" total = 0\n",
" for data in data_loader:\n",
" inputs, labels = data\n",
" inputs = inputs.to(device).float()\n",
" labels = labels.to(device).long()\n",
"\n",
" outputs = model(inputs)\n",
" _, predicted = torch.max(outputs, 1)\n",
" total += labels.size(0)\n",
" correct += (predicted == labels).sum().item()\n",
"\n",
" acc = 100 * correct / total\n",
" return f\"{acc}%\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Plotting Functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Plotting Functions\n",
"\n",
"def display_image_from_greyscale_array(matrix, title):\n",
" \"\"\"\n",
" Display image from greyscale array\n",
"\n",
" Args:\n",
" matrix: np.ndarray\n",
" Image\n",
" title: string\n",
" Title of plot\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" _matrix = matrix.astype(np.uint8)\n",
" _img = Image.fromarray(_matrix, 'L')\n",
" plt.figure(figsize=(3, 3))\n",
" plt.imshow(_img, cmap='gray', vmin=0, vmax=255) # Using 220 instead of 255 so the examples show up better\n",
" plt.title(title)\n",
" plt.axis('off')\n",
"\n",
"\n",
"def make_plots(original, actual_convolution, solution):\n",
" \"\"\"\n",
" Function to build original image/obtained solution and actual convolution\n",
"\n",
" Args:\n",
" original: np.ndarray\n",
" Image\n",
" actual_convolution: np.ndarray\n",
" Expected convolution output\n",
" solution: np.ndarray\n",
" Obtained convolution output\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" display_image_from_greyscale_array(original, \"Original Image\")\n",
" display_image_from_greyscale_array(actual_convolution, \"Convolution result\")\n",
" display_image_from_greyscale_array(solution, \"Your solution\")\n",
"\n",
"\n",
"def plot_loss_accuracy(train_loss, train_acc,\n",
" validation_loss, validation_acc):\n",
" \"\"\"\n",
" Code to plot loss and accuracy\n",
"\n",
" Args:\n",
" train_loss: list\n",
" Log of training loss\n",
" validation_loss: list\n",
" Log of validation loss\n",
" train_acc: list\n",
" Log of training accuracy\n",
" validation_acc: list\n",
" Log of validation accuracy\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" epochs = len(train_loss)\n",
" fig, (ax1, ax2) = plt.subplots(1, 2)\n",
" ax1.plot(list(range(epochs)), train_loss, label='Training Loss')\n",
" ax1.plot(list(range(epochs)), validation_loss, label='Validation Loss')\n",
" ax1.set_xlabel('Epochs')\n",
" ax1.set_ylabel('Loss')\n",
" ax1.set_title('Epoch vs Loss')\n",
" ax1.legend()\n",
"\n",
" ax2.plot(list(range(epochs)), train_acc, label='Training Accuracy')\n",
" ax2.plot(list(range(epochs)), validation_acc, label='Validation Accuracy')\n",
" ax2.set_xlabel('Epochs')\n",
" ax2.set_ylabel('Accuracy')\n",
" ax2.set_title('Epoch vs Accuracy')\n",
" ax2.legend()\n",
" fig.set_size_inches(15.5, 5.5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Set random seed\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Executing `set_seed(seed=seed)` you are setting the seed\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Set random seed\n",
"\n",
"# @markdown Executing `set_seed(seed=seed)` you are setting the seed\n",
"\n",
"# For DL its critical to set the random seed so that students can have a\n",
"# baseline to compare their results to expected results.\n",
"# Read more here: https://pytorch.org/docs/stable/notes/randomness.html\n",
"\n",
"# Call `set_seed` function in the exercises to ensure reproducibility.\n",
"import random\n",
"import torch\n",
"\n",
"def set_seed(seed=None, seed_torch=True):\n",
" \"\"\"\n",
" Function that controls randomness.\n",
" NumPy and random modules must be imported.\n",
"\n",
" Args:\n",
" seed : Integer\n",
" A non-negative integer that defines the random state. Default is `None`.\n",
" seed_torch : Boolean\n",
" If `True` sets the random seed for pytorch tensors, so pytorch module\n",
" must be imported. Default is `True`.\n",
"\n",
" Returns:\n",
" Nothing.\n",
" \"\"\"\n",
" if seed is None:\n",
" seed = np.random.choice(2 ** 32)\n",
" random.seed(seed)\n",
" np.random.seed(seed)\n",
" if seed_torch:\n",
" torch.manual_seed(seed)\n",
" torch.cuda.manual_seed_all(seed)\n",
" torch.cuda.manual_seed(seed)\n",
" torch.backends.cudnn.benchmark = False\n",
" torch.backends.cudnn.deterministic = True\n",
"\n",
" print(f'Random seed {seed} has been set.')\n",
"\n",
"\n",
"# In case that `DataLoader` is used\n",
"def seed_worker(worker_id):\n",
" \"\"\"\n",
" DataLoader will reseed workers following randomness in\n",
" multi-process data loading algorithm.\n",
"\n",
" Args:\n",
" worker_id: integer\n",
" ID of subprocess to seed. 0 means that\n",
" the data will be loaded in the main process\n",
" Refer: https://pytorch.org/docs/stable/data.html#data-loading-randomness for more details\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" worker_seed = torch.initial_seed() % 2**32\n",
" np.random.seed(worker_seed)\n",
" random.seed(worker_seed)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Set device (GPU or CPU). Execute `set_device()`\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Set device (GPU or CPU). Execute `set_device()`\n",
"# especially if torch modules used.\n",
"\n",
"# Inform the user if the notebook uses GPU or CPU.\n",
"\n",
"def set_device():\n",
" \"\"\"\n",
" Set the device. CUDA if available, CPU otherwise\n",
"\n",
" Args:\n",
" None\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
" if device != \"cuda\":\n",
" print(\"WARNING: For this notebook to perform best, \"\n",
" \"if possible, in the menu under `Runtime` -> \"\n",
" \"`Change runtime type.` select `GPU` \")\n",
" else:\n",
" print(\"GPU is enabled in this notebook.\")\n",
"\n",
" return device"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"SEED = 2021\n",
"set_seed(seed=SEED)\n",
"DEVICE = set_device()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 0: Recap the Experience from Last Week\n",
"\n",
"*Time estimate: ~15mins*"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Last week you learned a lot! Recall that overparametrized ANNs are efficient universal approximators, but also that ANNs can memorize our data. However, regularization can help ANNs to better generalize. You were introduced to several regularization techniques such as *L1*, *L2*, *Data Augmentation*, and *Dropout*.\n",
"\n",
"Today we'll be talking about other ways to simplify ANNs, by making smart changes to their architecture."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 1: Introduction to CNNs and RNNs\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Introduction to CNNs and RNNs\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', '5598K-hS89A'), ('Bilibili', 'BV1cL411p7rz')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Introduction_to_CNNs_and_RNNs_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Think! 0: Regularization & effective number of params\n",
"Let's think back to last week, when you learned about regularization. Recall that regularization comes in several forms. For example, L1 regularization adds a term to the loss function that penalizes based on the sum of the _absolute_ magnitude of the weights. Below are the results from training a simple multilayer perceptron with one hidden layer (b) on a simple toy dataset (a).\n",
"\n",
"Below that are two graphics that show the effect of regularization on both the number of non-zero weights (d), and on the network's accuracy (c).\n",
"\n",
"What do you notice?\n",
"\n",
"**Note**: Dense layers are the same as fully-connected layers. And pytorch calls them linear layers. Confusing, but now you know!\n",
"\n",
"\n",
" \n",
" a. The 2-dimensional inputs of class A (red) and B (green). b.The network architecture. Each Dense layer contains the (batch size, dimension), and below, the number of its trainable parameters. c.The train (blue) and validation (orange) accuracy as function of the regularization strength. d.The number of non-zero parameters as a function of the regularization strength.\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_18b18cac.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Regularization_and_effective_number_of_params_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Coming Up**\n",
"\n",
"The rest of these lectures focus on another way to reduce parameters: weight-sharing. Weight-sharing is based on the idea that some sets of weights can be used at multiple points in a network. We will focus primarily on CNNs today, where the weight-sharing is across the 2D space of an image. This weight-sharing technique (across space) can reduce the number of parameters and increase a network's ability to generalize. For completeness, a similar approach is the Recurrent Neural Networks (RNNs), which share parameters across time, but we will not dive into this in this tutorial."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 1: Neuroscience motivation, General CNN structure\n",
"\n",
"*Time estimate: ~25mins*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 2: Representations & Visual processing in the brain\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 2: Representations & Visual processing in the brain\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'AXO-iflKa58'), ('Bilibili', 'BV1c64y1x7mJ')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Representations_and_Visual_processing_in_the_brain_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Think! 1: What makes a representation good?\n",
"Representations have a long and storied history, having been studied by the likes of Aristotle back in 300 BC! Representations are not a new idea, and they certainly don't exist just in neural networks.\n",
"\n",
"Take a moment with your pod to discuss what would make a good representation, and how that might differ depending on the task you train your CNN to do.\n",
"\n",
"If there's time, you can also consider how the brain's representations might differ from a *learned* representation inside a NN.\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_82e644f4.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_What_makes_a_representation_good_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 2: Convolutions and Edge Detection\n",
"\n",
"*Time estimate: ~25mins*"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Fundamental to CNNs are convolutions. After all, that is what the **C** in CNN stands for! In this section, we will define what a convolution is, practice performing a convolution, and implement it in code."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 3: Details about Convolution\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 3: Details about Convolution\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'pmc40WCnF-w'), ('Bilibili', 'BV1Q64y1z77p')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Details_about_convolution_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Before jumping into coding exercises, take a moment to look at this animation that steps through the process of convolution.\n",
"\n",
"Recall from the video that convolution involves sliding the kernel across the image, taking the element-wise product, and adding those products together.\n",
"\n",
"\n",
"\n",
"Adopted from A. Zhang, Z. C. Lipton, M. Li and A. J. Smola, _[Dive into Deep Learning](http://d2l.ai/chapter_convolutional-neural-networks/conv-layer.html)_.\n",
"\n",
" \n",
"\n",
"**Note:** You need to run the cell to activate the sliders, and again to run once changing the sliders.\n",
"\n",
"**Tip:** In this animation, and all the ones that follow, you can hover over the parts of the code underlined in red to change them.\n",
"\n",
"**Tip:** Below, the function is called `Conv2d` because the convolutional filter is a matrix with two dimensions (2D). There are also 1D and 3D convolutions, but we won't talk about them today."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 2: Visualization of Convolution"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Important:** Change the bool variable `run_demo` to `True` by ticking the box, in order to experiment with the demo. Due to video rendering on jupyter-book, we had to remove it from the automatic execution."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" *Run this cell to enable the widget!*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown *Run this cell to enable the widget!*\n",
"\n",
"from IPython.display import HTML\n",
"\n",
"id_html = 2\n",
"url = f'https://raw.githubusercontent.com/NeuromatchAcademy/course-content-dl/main/tutorials/W2D2_ConvnetsAndDlThinking/static/interactive_demo{id_html}.html'\n",
"run_demo = False # @param {type:\"boolean\"}\n",
"if run_demo:\n",
" display(HTML(url))"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"#### Definitional Note\n",
"\n",
"\n",
"If you have a background in signal processing or math, you may have already heard of convolution. However, the definitions in other domains and the one we use here are slightly different. The more common definition involves flipping the kernel horizontally and vertically before sliding.\n",
"\n",
"**For our purposes, no flipping is needed. If you are familiar with conventions involving flipping, just assume the kernel is pre-flipped.**\n",
"\n",
"In more general usage, the no-flip operation that we call convolution is known as _cross-correlation_ (hence the usage of `scipy.signal.correlate2d` in the next exercise). Early papers used the more common definition of convolution, but not using a flip is easier to visualize, and in fact the lack of flip does not impact a CNN's ability to learn."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 2.1: Convolution of a Simple Kernel\n",
"At its core, convolution is just repeatedly multiplying a matrix, known as a _kernel_ or _filter_, with some other, larger matrix (in our case the pixels of an image). Consider the below image and kernel:\n",
"\n",
"\\begin{align}\n",
"\\textbf{Image} &=\n",
"\\begin{bmatrix}0 & 200 & 200 \\\\0 & 0 & 200 \\\\ 0 & 0 & 0\n",
"\\end{bmatrix} \\\\ \\\\\n",
"\\textbf{Kernel} &=\n",
"\\begin{bmatrix} \\frac{1}{4} &\\frac{1}{4} \\\\\\frac{1}{4} & \\frac{1}{4}\n",
"\\end{bmatrix}\n",
"\\end{align}\n",
"\n",
"Perform (by hand) the operations needed to convolve the kernel and image above. Afterwards enter your results in the \"solution\" section in the code below. Think about what this specific kernel is doing to the original image.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def conv_check():\n",
" \"\"\"\n",
" Demonstration of convolution operation\n",
"\n",
" Args:\n",
" None\n",
"\n",
" Returns:\n",
" original: np.ndarray\n",
" Image\n",
" actual_convolution: np.ndarray\n",
" Expected convolution output\n",
" solution: np.ndarray\n",
" Obtained convolution output\n",
" kernel: np.ndarray\n",
" Kernel\n",
" \"\"\"\n",
" ####################################################################\n",
" # Fill in missing code below (the elements of the matrix),\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Fill in the solution matrix, then delete this\")\n",
" ####################################################################\n",
" # Write the solution array and call the function to verify it!\n",
" solution = ...\n",
"\n",
" original = np.array([\n",
" [0, 200, 200],\n",
" [0, 0, 200],\n",
" [0, 0, 0]\n",
" ])\n",
"\n",
" kernel = np.array([\n",
" [0.25, 0.25],\n",
" [0.25, 0.25]\n",
" ])\n",
"\n",
" actual_convolution = scipy.signal.correlate2d(original, kernel, mode=\"valid\")\n",
"\n",
" if (solution == actual_convolution).all():\n",
" print(\"✅ Your solution is correct!\\n\")\n",
" else:\n",
" print(\"❌ Your solution is incorrect.\\n\")\n",
"\n",
" return original, kernel, actual_convolution, solution\n",
"\n",
"\n",
"\n",
"## Uncomment to test your solution!\n",
"# original, kernel, actual_convolution, solution = conv_check()\n",
"# make_plots(original, actual_convolution, solution)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_78a81e50.py)\n",
"\n",
"*Example output:*\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Convolution_of_a_simple_kernel_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 2.2: Convolution Output Size\n",
"\n",
"Now, you have manually calculated a convolution. How did this change the shape of the output? When you know the shapes of the input matrix and kernel, what is the shape of the output?\n",
"\n",
"**Hint:** If you have problems figuring out what the output shape should look like, go back to the visualisation and see how the output shape changes as you modify the image and kernel size."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def calculate_output_shape(image_shape, kernel_shape):\n",
" \"\"\"\n",
" Helper function to calculate output shape\n",
"\n",
" Args:\n",
" image_shape: tuple\n",
" Image shape\n",
" kernel_shape: tuple\n",
" Kernel shape\n",
"\n",
" Returns:\n",
" output_height: int\n",
" Output Height\n",
" output_width: int\n",
" Output Width\n",
" \"\"\"\n",
" image_height, image_width = image_shape\n",
" kernel_height, kernel_width = kernel_shape\n",
" ####################################################################\n",
" # Fill in missing code below, then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Fill in the lines below, then delete this\")\n",
" ####################################################################\n",
" output_height = ...\n",
" output_width = ...\n",
" return output_height, output_width\n",
"\n",
"\n",
"\n",
"# Here we check if your function works correcly by applying it to different image\n",
"# and kernel shapes\n",
"# check_shape_function(calculate_output_shape, image_shape=(3, 3), kernel_shape=(2, 2))\n",
"# check_shape_function(calculate_output_shape, image_shape=(3, 4), kernel_shape=(2, 3))\n",
"# check_shape_function(calculate_output_shape, image_shape=(5, 5), kernel_shape=(5, 5))\n",
"# check_shape_function(calculate_output_shape, image_shape=(10, 20), kernel_shape=(3, 2))\n",
"# check_shape_function(calculate_output_shape, image_shape=(100, 200), kernel_shape=(40, 30))"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_7c652c63.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Convolution_output_size_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 2.3: Coding a Convolution\n",
"\n",
"Here, we have the skeleton of a function that performs convolution using the provided image and kernel matrices.\n",
"\n",
"*Exercise:* Fill in the missing lines of code. You can test your function by uncommenting the sections beneath it.\n",
"\n",
"Note: in more general situations, once you understand convolutions, you can use functions already available in `pytorch`/`numpy` to perform convolution (such as `scipy.signal.correlate2d` or `scipy.signal.convolve2d`)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def convolution2d(image, kernel):\n",
" \"\"\"\n",
" Convolves a 2D image matrix with a kernel matrix.\n",
"\n",
" Args:\n",
" image: np.ndarray\n",
" Image\n",
" kernel: np.ndarray\n",
" Kernel\n",
"\n",
" Returns:\n",
" output: np.ndarray\n",
" Output of convolution\n",
" \"\"\"\n",
"\n",
" # Get the height/width of the image, kernel, and output\n",
" im_h, im_w = image.shape\n",
" ker_h, ker_w = kernel.shape\n",
" out_h = im_h - ker_h + 1\n",
" out_w = im_w - ker_w + 1\n",
"\n",
" # Create an empty matrix in which to store the output\n",
" output = np.zeros((out_h, out_w))\n",
"\n",
" # Iterate over the different positions at which to apply the kernel,\n",
" # storing the results in the output matrix\n",
" for out_row in range(out_h):\n",
" for out_col in range(out_w):\n",
" # Overlay the kernel on part of the image\n",
" # (multiply each element of the kernel with some element of the image, then sum)\n",
" # to determine the output of the matrix at a point\n",
" current_product = 0\n",
" for i in range(ker_h):\n",
" for j in range(ker_w):\n",
" ####################################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Implement the convolution function\")\n",
" ####################################################################\n",
" current_product += ...\n",
"\n",
" output[out_row, out_col] = current_product\n",
"\n",
" return output\n",
"\n",
"\n",
"\n",
"## Tests\n",
"# First, we test the parameters we used before in the manual-calculation example\n",
"image = np.array([[0, 200, 200], [0, 0, 200], [0, 0, 0]])\n",
"kernel = np.array([[0.25, 0.25], [0.25, 0.25]])\n",
"# check_conv_function(convolution2d, image, kernel)\n",
"\n",
"# Next, we test with a different input and kernel (the numbers 1-9 and 1-4)\n",
"image = np.arange(9).reshape(3, 3)\n",
"kernel = np.arange(4).reshape(2, 2)\n",
"# check_conv_function(convolution2d, image, kernel)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_4f643447.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Coding_a_Convolution_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Convolution on the Chicago Skyline\n",
"\n",
"After you have finished programming the above convolution function, run the coding cell below, which applies two different kernels to a greyscale picture of Chicago and takes the geometric average of the results.\n",
"\n",
"**Make sure you remove all print statements from your convolution2d implementation, or this will run for a _very_ long time.** It should take somewhere between 10 seconds and 1 minute.\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" ### Load images (run me)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown ### Load images (run me)\n",
"\n",
"import requests, os\n",
"\n",
"if not os.path.exists('images/'):\n",
" os.mkdir('images/')\n",
"\n",
"url = \"https://raw.githubusercontent.com/NeuromatchAcademy/course-content-dl/main/tutorials/W2D2_ConvnetsAndDlThinking/static/chicago_skyline_shrunk_v2.bmp\"\n",
"r = requests.get(url, allow_redirects=True)\n",
"with open(\"images/chicago_skyline_shrunk_v2.bmp\", 'wb') as fd:\n",
" fd.write(r.content)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Visualize the output of your function\n",
"from IPython.display import display as IPydisplay\n",
"\n",
"with open(\"images/chicago_skyline_shrunk_v2.bmp\", 'rb') as skyline_image_file:\n",
" img_skyline_orig = Image.open(skyline_image_file)\n",
" img_skyline_mat = np.asarray(img_skyline_orig)\n",
" kernel_ver = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]])\n",
" kernel_hor = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]).T\n",
" img_processed_mat_ver = convolution2d(img_skyline_mat, kernel_ver)\n",
" img_processed_mat_hor = convolution2d(img_skyline_mat, kernel_hor)\n",
" img_processed_mat = np.sqrt(np.multiply(img_processed_mat_ver,\n",
" img_processed_mat_ver) + \\\n",
" np.multiply(img_processed_mat_hor,\n",
" img_processed_mat_hor))\n",
"\n",
" img_processed_mat *= 255.0/img_processed_mat.max()\n",
" img_processed_mat = img_processed_mat.astype(np.uint8)\n",
" img_processed = Image.fromarray(img_processed_mat, 'L')\n",
" width, height = img_skyline_orig.size\n",
" scale = 0.6\n",
" IPydisplay(img_skyline_orig.resize((int(width*scale), int(height*scale))),\n",
" Image.NEAREST)\n",
" IPydisplay(img_processed.resize((int(width*scale), int(height*scale))),\n",
" Image.NEAREST)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Pretty cool, right? We will go into more detail on what's happening in the next section."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 2.1: Demonstration of a CNN in PyTorch\n",
"At this point, you should have a fair idea of how to perform a convolution on an image given a kernel. In the following cell, we provide a code snippet that demonstrates setting up a convolutional network using PyTorch.\n",
"\n",
"We look at the `nn` module in PyTorch. The `nn` module contains a plethora of functions that will make implementing a neural network easier. In particular we will look at the `nn.Conv2d()` function, which creates a convolutional layer that is applied to whatever image that you feed the resulting network.\n",
"\n",
"Look at the code below. In it, we define a `Net` class that you can instantiate with a kernel to create a Neural Network object. When you apply the network object to an image (or anything in the form of a matrix), it convolves the kernel over that image."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"class Net(nn.Module):\n",
" \"\"\"\n",
" A convolutional neural network class.\n",
" When an instance of it is constructed with a kernel, you can apply that instance\n",
" to a matrix and it will convolve the kernel over that image.\n",
" i.e. Net(kernel)(image)\n",
" \"\"\"\n",
"\n",
" def __init__(self, kernel=None, padding=0):\n",
" super(Net, self).__init__()\n",
" \"\"\"\n",
" Summary of the nn.conv2d parameters (you can also get this by hovering\n",
" over the method):\n",
" - in_channels (int): Number of channels in the input image\n",
" - out_channels (int): Number of channels produced by the convolution\n",
" - kernel_size (int or tuple): Size of the convolving kernel\n",
"\n",
" Args:\n",
" padding: int or tuple, optional\n",
" Zero-padding added to both sides of the input. Default: 0\n",
" kernel: np.ndarray\n",
" Convolving kernel. Default: None\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" self.conv1 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=2,\n",
" padding=padding)\n",
"\n",
" # Set up a default kernel if a default one isn't provided\n",
" if kernel is not None:\n",
" dim1, dim2 = kernel.shape[0], kernel.shape[1]\n",
" kernel = kernel.reshape(1, 1, dim1, dim2)\n",
"\n",
" self.conv1.weight = torch.nn.Parameter(kernel)\n",
" self.conv1.bias = torch.nn.Parameter(torch.zeros_like(self.conv1.bias))\n",
"\n",
" def forward(self, x):\n",
" \"\"\"\n",
" Forward Pass of nn.conv2d\n",
"\n",
" Args:\n",
" x: torch.tensor\n",
" Input features\n",
"\n",
" Returns:\n",
" x: torch.tensor\n",
" Convolution output\n",
" \"\"\"\n",
" x = self.conv1(x)\n",
" return x"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Format a default 2x2 kernel of numbers from 0 through 3\n",
"kernel = torch.Tensor(np.arange(4).reshape(2, 2))\n",
"\n",
"# Prepare the network with that default kernel\n",
"net = Net(kernel=kernel, padding=0).to(DEVICE)\n",
"\n",
"# Set up a 3x3 image matrix of numbers from 0 through 8\n",
"image = torch.Tensor(np.arange(9).reshape(3, 3))\n",
"image = image.reshape(1, 1, 3, 3).to(DEVICE) # BatchSize X Channels X Height X Width\n",
"\n",
"print(\"Image:\\n\" + str(image))\n",
"print(\"Kernel:\\n\" + str(kernel))\n",
"output = net(image) # Apply the convolution\n",
"print(\"Output:\\n\" + str(output))"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As a quick aside, notice the difference in the input and output size. The input had a size of 3×3, and the output is of size 2×2. This is because of the fact that the kernel can't produce values for the edges of the image - when it slides to an end of the image and is centered on a border pixel, it overlaps space outside of the image that is undefined. If we don't want to lose that information, we will have to pad the image with some defaults (such as 0s) on the border. This process is, somewhat predictably, called *padding*. We will talk more about padding in the next section."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"print(\"Image (before padding):\\n\" + str(image))\n",
"print(\"Kernel:\\n\" + str(kernel))\n",
"\n",
"# Prepare the network with the aforementioned default kernel, but this\n",
"# time with padding\n",
"net = Net(kernel=kernel, padding=1).to(DEVICE)\n",
"output = net(image) # Apply the convolution onto the padded image\n",
"print(\"Output:\\n\" + str(output))"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 2.2: Padding and Edge Detection"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Before we start in on the exercises, here's a visualization to help you think about padding."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 2.2: Visualization of Convolution with Padding and Stride\n",
"\n",
"\n",
"Recall that\n",
"* Padding adds rows and columns of zeros to the outside edge of an image\n",
"* Stride length adjusts the distance by which a filter is shifted after each convolution.\n",
"\n",
"Change the padding and stride and see how this affects the shape of the output. How does the padding need to be configured to maintain the shape of the input?"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Important:** Change the bool variable `run_demo` to `True` by ticking the box, in order to experiment with the demo. Due to video rendering on jupyter-book, we had to remove it from the automatic execution."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" *Run this cell to enable the widget!*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown *Run this cell to enable the widget!*\n",
"\n",
"from IPython.display import HTML\n",
"\n",
"id_html = 2.2\n",
"url = f'https://raw.githubusercontent.com/NeuromatchAcademy/course-content-dl/main/tutorials/W2D2_ConvnetsAndDlThinking/static/interactive_demo{id_html}.html'\n",
"run_demo = False # @param {type:\"boolean\"}\n",
"if run_demo:\n",
" display(HTML(url))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Visualization_of_Convolution_with_Padding_and_Stride_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! 2.2.1: Edge Detection"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"One of the simpler tasks performed by a convolutional layer is edge detection; that is, finding a place in the image where there is a large and abrupt change in color. Edge-detecting filters are usually learned by the first layers in a CNN. Observe the following simple kernel and discuss whether this will detect vertical edges (where the trace of the edge is vertical; i.e. there is a boundary between left and right), or whether it will detect horizontal edges (where the trace of the edge is horizontal; i.e., there is a boundary between top and bottom).\n",
"\n",
"\\begin{equation}\n",
"\\textbf{Kernel} =\n",
"\\begin{bmatrix} 1 & -1 \\\\ 1 & -1\n",
"\\end{bmatrix}\n",
"\\end{equation}"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_309474b2.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Edge_Detection_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Consider the image below, which has a black vertical stripe with white on the side. This is like a very zoomed-in vertical edge within an image!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Prepare an image that's basically just a vertical black stripe\n",
"X = np.ones((6, 8))\n",
"X[:, 2:6] = 0\n",
"print(X)\n",
"plt.imshow(X, cmap=plt.get_cmap('gray'))\n",
"plt.show()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Format the image that's basically just a vertical stripe\n",
"image = torch.from_numpy(X)\n",
"image = image.reshape(1, 1, 6, 8) # BatchSize X Channels X Height X Width\n",
"\n",
"# Prepare a 2x2 kernel with 1s in the first column and -1s in the\n",
"# This exact kernel was discussed above!\n",
"kernel = torch.Tensor([[1.0, -1.0], [1.0, -1.0]])\n",
"net = Net(kernel=kernel)\n",
"\n",
"# Apply the kernel to the image and prepare for display\n",
"processed_image = net(image.float())\n",
"processed_image = processed_image.reshape(5, 7).detach().numpy()\n",
"print(processed_image)\n",
"plt.imshow(processed_image, cmap=plt.get_cmap('gray'))\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As you can see, this kernel detects vertical edges (the black stripe corresponds to a highly positive result, while the white stripe corresponds to a highly negative result. However, to display the image, all the pixels are normalized between 0=black and 1=white)."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! 2.2.2 Kernel structure\n",
"\n",
"If the kernel were transposed (i.e., the columns become rows and the rows become columns), what would the kernel detect? What would be produced by running this kernel on the vertical edge image above?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_7cc3340b.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Kernel_structure_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 3: Kernels, Pooling and Subsampling\n",
"\n",
"*Time estimate: ~50mins*"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"To visualize the various components of a CNN, we will build a simple CNN step by step. Recall that the MNIST dataset consists of binarized images of handwritten digits. This time, we will use the EMNIST letters dataset, which consists of binarized images of handwritten characters $(A, ..., Z)$.\n",
"\n",
"We will simplify the problem further by only keeping the images that correspond to $X$ (labeled as `24` in the dataset) and $O$ (labeled as `15` in the dataset). Then, we will train a CNN to classify an image either an $X$ or an $O$."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Download EMNIST dataset\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Download EMNIST dataset\n",
"\n",
"# webpage: https://www.itl.nist.gov/iaui/vip/cs_links/EMNIST/gzip.zip\n",
"fname = 'EMNIST.zip'\n",
"folder = 'EMNIST'\n",
"url = \"https://osf.io/xwfaj/download\"\n",
"download_data(fname, folder, url, tar=False)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Dataset/DataLoader Functions *(Run me!)*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Dataset/DataLoader Functions *(Run me!)*\n",
"\n",
"def get_Xvs0_dataset(normalize=False, download=False):\n",
" \"\"\"\n",
" Load Dataset\n",
"\n",
" Args:\n",
" normalize: boolean\n",
" If true, normalise dataloader\n",
" download: boolean\n",
" If true, download dataset\n",
"\n",
" Returns:\n",
" emnist_train: torch.loader\n",
" Training Data\n",
" emnist_test: torch.loader\n",
" Test Data\n",
" \"\"\"\n",
" if normalize:\n",
" transform = transforms.Compose([\n",
" transforms.ToTensor(),\n",
" transforms.Normalize((0.1307,), (0.3081,))\n",
" ])\n",
" else:\n",
" transform = transforms.Compose([\n",
" transforms.ToTensor(),\n",
" ])\n",
"\n",
" emnist_train = datasets.EMNIST(root='.',\n",
" split='letters',\n",
" download=download,\n",
" train=True,\n",
" transform=transform)\n",
" emnist_test = datasets.EMNIST(root='.',\n",
" split='letters',\n",
" download=download,\n",
" train=False,\n",
" transform=transform)\n",
"\n",
" # Only want O (15) and X (24) labels\n",
" train_idx = (emnist_train.targets == 15) | (emnist_train.targets == 24)\n",
" emnist_train.targets = emnist_train.targets[train_idx]\n",
" emnist_train.data = emnist_train.data[train_idx]\n",
"\n",
" # Convert Xs predictions to 1, Os predictions to 0\n",
" emnist_train.targets = (emnist_train.targets == 24).type(torch.int64)\n",
"\n",
" test_idx = (emnist_test.targets == 15) | (emnist_test.targets == 24)\n",
" emnist_test.targets = emnist_test.targets[test_idx]\n",
" emnist_test.data = emnist_test.data[test_idx]\n",
"\n",
" # Convert Xs predictions to 1, Os predictions to 0\n",
" emnist_test.targets = (emnist_test.targets == 24).type(torch.int64)\n",
"\n",
" return emnist_train, emnist_test\n",
"\n",
"\n",
"def get_data_loaders(train_dataset, test_dataset,\n",
" batch_size=32, seed=0):\n",
" \"\"\"\n",
" Helper function to fetch dataloaders\n",
"\n",
" Args:\n",
" train_dataset: torch.tensor\n",
" Training data\n",
" test_dataset: torch.tensor\n",
" Test data\n",
" batch_size: int\n",
" Batch Size\n",
" seed: int\n",
" Set seed for reproducibility\n",
"\n",
" Returns:\n",
" emnist_train: torch.loader\n",
" Training Data\n",
" emnist_test: torch.loader\n",
" Test Data\n",
" \"\"\"\n",
" g_seed = torch.Generator()\n",
" g_seed.manual_seed(seed)\n",
"\n",
" train_loader = DataLoader(train_dataset,\n",
" batch_size=batch_size,\n",
" shuffle=True,\n",
" num_workers=2,\n",
" worker_init_fn=seed_worker,\n",
" generator=g_seed)\n",
" test_loader = DataLoader(test_dataset,\n",
" batch_size=batch_size,\n",
" shuffle=True,\n",
" num_workers=2,\n",
" worker_init_fn=seed_worker,\n",
" generator=g_seed)\n",
"\n",
" return train_loader, test_loader"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"emnist_train, emnist_test = get_Xvs0_dataset(normalize=False, download=False)\n",
"train_loader, test_loader = get_data_loaders(emnist_train, emnist_test,\n",
" seed=SEED)\n",
"\n",
"# Index of an image in the dataset that corresponds to an X and O\n",
"x_img_idx = 4\n",
"o_img_idx = 15"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Let's view a couple samples from the dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"fig, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4, figsize=(12, 6))\n",
"ax1.imshow(emnist_train[0][0].reshape(28, 28), cmap='gray')\n",
"ax2.imshow(emnist_train[10][0].reshape(28, 28), cmap='gray')\n",
"ax3.imshow(emnist_train[4][0].reshape(28, 28), cmap='gray')\n",
"ax4.imshow(emnist_train[6][0].reshape(28, 28), cmap='gray')\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Interactive Demo 3: Visualization of Convolution with Multiple Filters\n",
"\n",
"Change the number of input channels (e.g., the color channels of an image or the output channels of a previous layer) and the output channels (number of different filters to apply)."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Important:** Change the bool variable `run_demo` to `True` by ticking the box, in order to experiment with the demo. Due to video rendering on jupyter-book, we had to remove it from the automatic execution."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" *Run this cell to enable the widget!*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown *Run this cell to enable the widget!*\n",
"\n",
"from IPython.display import HTML\n",
"\n",
"id_html = 3\n",
"url = f'https://raw.githubusercontent.com/NeuromatchAcademy/course-content-dl/main/tutorials/W2D2_ConvnetsAndDlThinking/static/interactive_demo{id_html}.html'\n",
"run_demo = False # @param {type:\"boolean\"}\n",
"if run_demo:\n",
" display(HTML(url))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Visualization_of_Convolution_with_Multiple_Filters_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.1: Multiple Filters\n",
"\n",
"The following network sets up 3 filters and runs them on an image of the dataset from the $X$ class. Note that we are using \"thicker\" filters than those presented in the videos. Here, the filters are $5 \\times 5$, whereas in the videos $3 \\times 3$."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"class Net2(nn.Module):\n",
" \"\"\"\n",
" Neural Network instance\n",
" \"\"\"\n",
"\n",
" def __init__(self, padding=0):\n",
" \"\"\"\n",
" Initialize parameters of Net2\n",
"\n",
" Args:\n",
" padding: int or tuple, optional\n",
" Zero-padding added to both sides of the input. Default: 0\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" super(Net2, self).__init__()\n",
" self.conv1 = nn.Conv2d(in_channels=1, out_channels=3, kernel_size=5,\n",
" padding=padding)\n",
"\n",
" # First kernel - leading diagonal\n",
" kernel_1 = torch.Tensor([[[1., 1., -1., -1., -1.],\n",
" [1., 1., 1., -1., -1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [-1., -1., 1., 1., 1.],\n",
" [-1., -1., -1., 1., 1.]]])\n",
"\n",
" # Second kernel - other diagonal\n",
" kernel_2 = torch.Tensor([[[-1., -1., -1., 1., 1.],\n",
" [-1., -1., 1., 1., 1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [1., 1., 1., -1., -1.],\n",
" [1., 1., -1., -1., -1.]]])\n",
"\n",
" # tThird kernel - checkerboard pattern\n",
" kernel_3 = torch.Tensor([[[1., 1., -1., 1., 1.],\n",
" [1., 1., 1., 1., 1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [1., 1., 1., 1., 1.],\n",
" [1., 1., -1., 1., 1.]]])\n",
"\n",
"\n",
" # Stack all kernels in one tensor with (3, 1, 5, 5) dimensions\n",
" multiple_kernels = torch.stack([kernel_1, kernel_2, kernel_3], dim=0)\n",
"\n",
" self.conv1.weight = torch.nn.Parameter(multiple_kernels)\n",
"\n",
" # Negative bias\n",
" self.conv1.bias = torch.nn.Parameter(torch.Tensor([-4, -4, -12]))\n",
"\n",
" def forward(self, x):\n",
" \"\"\"\n",
" Forward Pass of Net2\n",
"\n",
" Args:\n",
" x: torch.tensor\n",
" Input features\n",
"\n",
" Returns:\n",
" x: torch.tensor\n",
" Convolution output\n",
" \"\"\"\n",
" x = self.conv1(x)\n",
" return x"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Note:** We add a negative bias to give a threshold to select the high output value, which corresponds to the features we want to detect (e.g., 45 degree oriented bar).\n",
"\n",
"Now, let's visualize the filters using the code given below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"net2 = Net2().to(DEVICE)\n",
"fig, (ax11, ax12, ax13) = plt.subplots(1, 3)\n",
"# Show the filters\n",
"ax11.set_title(\"filter 1\")\n",
"ax11.imshow(net2.conv1.weight[0, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax12.set_title(\"filter 2\")\n",
"ax12.imshow(net2.conv1.weight[1, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax13.set_title(\"filter 3\")\n",
"ax13.imshow(net2.conv1.weight[2, 0].detach().cpu().numpy(), cmap=\"gray\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! 3.1: Do you see how these filters would help recognize an `X`?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_800ed014.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Multiple_Filters_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We apply the filters to the images."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"net2 = Net2().to(DEVICE)\n",
"x_img = emnist_train[x_img_idx][0].unsqueeze(dim=0).to(DEVICE)\n",
"output_x = net2(x_img)\n",
"output_x = output_x.squeeze(dim=0).detach().cpu().numpy()\n",
"\n",
"o_img = emnist_train[o_img_idx][0].unsqueeze(dim=0).to(DEVICE)\n",
"output_o = net2(o_img)\n",
"output_o = output_o.squeeze(dim=0).detach().cpu().numpy()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Let us view the image of $X$ and $O$ and what the output of the filters applied to them looks like. Pay special attention to the areas with very high vs. very low output patterns."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"fig, ((ax11, ax12, ax13, ax14),\n",
" (ax21, ax22, ax23, ax24),\n",
" (ax31, ax32, ax33, ax34)) = plt.subplots(3, 4)\n",
"\n",
"# Show the filters\n",
"ax11.axis(\"off\")\n",
"ax12.set_title(\"filter 1\")\n",
"ax12.imshow(net2.conv1.weight[0, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax13.set_title(\"filter 2\")\n",
"ax13.imshow(net2.conv1.weight[1, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax14.set_title(\"filter 3\")\n",
"ax14.imshow(net2.conv1.weight[2, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"\n",
"vmin, vmax = -6, 10\n",
"# Show x and the filters applied to x\n",
"ax21.set_title(\"image x\")\n",
"ax21.imshow(emnist_train[x_img_idx][0].reshape(28, 28), cmap='gray')\n",
"ax22.set_title(\"output filter 1\")\n",
"ax22.imshow(output_x[0], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax23.set_title(\"output filter 2\")\n",
"ax23.imshow(output_x[1], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax24.set_title(\"output filter 3\")\n",
"ax24.imshow(output_x[2], cmap='gray', vmin=vmin, vmax=vmax)\n",
"\n",
"# Show o and the filters applied to o\n",
"ax31.set_title(\"image o\")\n",
"ax31.imshow(emnist_train[o_img_idx][0].reshape(28, 28), cmap='gray')\n",
"ax32.set_title(\"output filter 1\")\n",
"ax32.imshow(output_o[0], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax33.set_title(\"output filter 2\")\n",
"ax33.imshow(output_o[1], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax34.set_title(\"output filter 3\")\n",
"ax34.imshow(output_o[2], cmap='gray', vmin=vmin, vmax=vmax)\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.2: ReLU after convolutions\n",
"\n",
"Up until now we've talked about the convolution operation, which is linear. But the real strength of neural networks comes from the incorporation of non-linear functions. Furthermore, in the real world, we often have learning problems where the relationship between the input and output is non-linear and complex.\n",
"\n",
"The ReLU (Rectified Linear Unit) introduces non-linearity into our model, allowing us to learn a more complex function that can better predict the class of an image.\n",
"\n",
"The ReLU function is shown below.\n",
"\n",
" \n",
"\n",
"\n",
"
\n",
" The Rectified Linear Unit (ReLU) Activation Function\n",
"
\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Now let us incorporate ReLU into our previous model and visualize the output."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"class Net3(nn.Module):\n",
" \"\"\"\n",
" Neural Network Instance\n",
" \"\"\"\n",
"\n",
" def __init__(self, padding=0):\n",
" \"\"\"\n",
" Initialize Net3 parameters\n",
"\n",
" Args:\n",
" padding: int or tuple, optional\n",
" Zero-padding added to both sides of the input. Default: 0\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" super(Net3, self).__init__()\n",
" self.conv1 = nn.Conv2d(in_channels=1, out_channels=3, kernel_size=5,\n",
" padding=padding)\n",
"\n",
" # First kernel - leading diagonal\n",
" kernel_1 = torch.Tensor([[[1., 1., -1., -1., -1.],\n",
" [1., 1., 1., -1., -1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [-1., -1., 1., 1., 1.],\n",
" [-1., -1., -1., 1., 1.]]])\n",
"\n",
" # Second kernel - other diagonal\n",
" kernel_2 = torch.Tensor([[[-1., -1., -1., 1., 1.],\n",
" [-1., -1., 1., 1., 1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [1., 1., 1., -1., -1.],\n",
" [1., 1., -1., -1., -1.]]])\n",
"\n",
" # Third kernel -checkerboard pattern\n",
" kernel_3 = torch.Tensor([[[1., 1., -1., 1., 1.],\n",
" [1., 1., 1., 1., 1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [1., 1., 1., 1., 1.],\n",
" [1., 1., -1., 1., 1.]]])\n",
"\n",
"\n",
" # Stack all kernels in one tensor with (3, 1, 5, 5) dimensions\n",
" multiple_kernels = torch.stack([kernel_1, kernel_2, kernel_3], dim=0)\n",
"\n",
" self.conv1.weight = torch.nn.Parameter(multiple_kernels)\n",
"\n",
" # Negative bias\n",
" self.conv1.bias = torch.nn.Parameter(torch.Tensor([-4, -4, -12]))\n",
"\n",
" def forward(self, x):\n",
" \"\"\"\n",
" Forward Pass of Net3\n",
"\n",
" Args:\n",
" x: torch.tensor\n",
" Input features\n",
"\n",
" Returns:\n",
" x: torch.tensor\n",
" Convolution output\n",
" \"\"\"\n",
" x = self.conv1(x)\n",
" x = F.relu(x)\n",
" return x"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We apply the filters and relus to the images."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"net3 = Net3().to(DEVICE)\n",
"x_img = emnist_train[x_img_idx][0].unsqueeze(dim=0).to(DEVICE)\n",
"output_x_relu = net3(x_img)\n",
"output_x_relu = output_x_relu.squeeze(dim=0).detach().cpu().numpy()\n",
"\n",
"o_img = emnist_train[o_img_idx][0].unsqueeze(dim=0).to(DEVICE)\n",
"output_o_relu = net3(o_img)\n",
"output_o_relu = output_o_relu.squeeze(dim=0).detach().cpu().numpy()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Let us view the image of $X$ and $O$ and what the output of the filters applied to them look like."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" *Execute this cell to view the filtered images*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown *Execute this cell to view the filtered images*\n",
"fig, ((ax11, ax12, ax13, ax14, ax15, ax16, ax17),\n",
" (ax21, ax22, ax23, ax24, ax25, ax26, ax27),\n",
" (ax31, ax32, ax33, ax34, ax35, ax36, ax37)) = plt.subplots(3, 4 + 3,\n",
" figsize=(14, 6))\n",
"# Show the filters\n",
"ax11.axis(\"off\")\n",
"ax12.set_title(\"filter 1\")\n",
"ax12.imshow(net3.conv1.weight[0, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax13.set_title(\"filter 2\")\n",
"ax13.imshow(net3.conv1.weight[1, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax14.set_title(\"filter 3\")\n",
"ax14.imshow(net3.conv1.weight[2, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"\n",
"ax15.set_title(\"filter 1\")\n",
"ax15.imshow(net3.conv1.weight[0, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax16.set_title(\"filter 2\")\n",
"ax16.imshow(net3.conv1.weight[1, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax17.set_title(\"filter 3\")\n",
"ax17.imshow(net3.conv1.weight[2, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"\n",
"vmin, vmax = -6, 10\n",
"# Show x and the filters applied to `x`\n",
"ax21.set_title(\"image x\")\n",
"ax21.imshow(emnist_train[x_img_idx][0].reshape(28, 28), cmap='gray')\n",
"ax22.set_title(\"output filter 1\")\n",
"ax22.imshow(output_x[0], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax23.set_title(\"output filter 2\")\n",
"ax23.imshow(output_x[1], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax24.set_title(\"output filter 3\")\n",
"ax24.imshow(output_x[2], cmap='gray', vmin=vmin, vmax=vmax)\n",
"\n",
"ax25.set_title(\"filter 1 + ReLU\")\n",
"ax25.imshow(output_x_relu[0], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax26.set_title(\"filter 2 + ReLU\")\n",
"ax26.imshow(output_x_relu[1], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax27.set_title(\"filter 3 + ReLU\")\n",
"ax27.imshow(output_x_relu[2], cmap='gray', vmin=vmin, vmax=vmax)\n",
"\n",
"# Show o and the filters applied to `o`\n",
"ax31.set_title(\"image o\")\n",
"ax31.imshow(emnist_train[o_img_idx][0].reshape(28, 28), cmap='gray')\n",
"ax32.set_title(\"output filter 1\")\n",
"ax32.imshow(output_o[0], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax33.set_title(\"output filter 2\")\n",
"ax33.imshow(output_o[1], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax34.set_title(\"output filter 3\")\n",
"ax34.imshow(output_o[2], cmap='gray', vmin=vmin, vmax=vmax)\n",
"\n",
"ax35.set_title(\"filter 1 + ReLU\")\n",
"ax35.imshow(output_o_relu[0], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax36.set_title(\"filter 2 + ReLU\")\n",
"ax36.imshow(output_o_relu[1], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax37.set_title(\"filter 3 + ReLU\")\n",
"ax37.imshow(output_o_relu[2], cmap='gray', vmin=vmin, vmax=vmax)\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Discuss with your pod how the ReLU activations help strengthen the features necessary to detect an $X$.\n",
"\n",
" \n",
"\n",
"[Here](https://stats.stackexchange.com/a/226927) you can found a discussion which talks about how ReLU is useful as an activation funciton.\n",
"\n",
"[Here](https://stats.stackexchange.com/questions/126238/what-are-the-advantages-of-relu-over-sigmoid-function-in-deep-neural-networks?sfb=2) you can found a another excellent discussion about the advantages of using ReLU."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.3: Pooling\n",
"\n",
"Convolutional layers create feature maps that summarize the presence of particular features (e.g., edges) in the input. However, these feature maps record the _precise_ position of features in the input. That means that small changes to the position of an object in an image can result in a very different feature map. But a cup is a cup (and an $X$ is an $X$) no matter where it appears in the image! We need to achieve _translational invariance_.\n",
"\n",
"A common approach to this problem is called downsampling. Downsampling creates a lower-resolution version of an image, retaining the large structural elements and removing some of the fine detail that may be less relevant to the task. In CNNs, Max-Pooling and Average-Pooling are used to downsample. These operations shrink the size of the hidden layers, and produce features that are more translationally invariant, which can be better leveraged by subsequent layers."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 4: Pooling\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 4: Pooling\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'XOss-NUlpo0'), ('Bilibili', 'BV1264y1z7JZ')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Pooling_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Like convolutional layers, pooling layers have fixed-shape windows (pooling windows) that are systematically applied to the input. As with filters, we can change the shape of the window and the size of the stride. And, just like with filters, every time we apply a pooling operation we produce a single output.\n",
"\n",
"Pooling performs a kind of information compression that provides summary statistics for a _neighborhood_ of the input.\n",
"- In Maxpooling, we compute the maximum value of all pixels in the pooling window.\n",
"- In Avgpooling, we compute the average value of all pixels in the pooling window.\n",
"\n",
"The example below shows the result of Maxpooling within the yellow pooling windows to create the red pooling output matrix.\n",
"\n",
"\n",
"
\n",
" An Example of Pooling with a kernel size of 2\n",
"
\n",
"\n",
"\n",
"Pooling gives our network translational invariance by providing a summary of the values in each pooling window. Thus, a small change in the features of the underlying image won't make a huge difference to the output.\n",
"\n",
"Note that, unlike a convolutional layer, the pooling layer contains no learned parameters! Pooling just computes a pre-determined summary of the input and passes that along. This is in contrast to the convolutional layer, where there are filters to be learned.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 3.3: The effect of the stride"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Important:** Change the bool variable `run_demo` to `True` by ticking the box, in order to experiment with the demo. Due to video rendering on jupyter-book, we had to remove it from the automatic execution."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The following animation depicts how changing the stride changes the output. The stride defines how much the pooling region is moved over the input matrix to produce the next output (red arrows in the animation). Give it a try! Change the stride and see how it affects the output shape. You can also try MaxPool or AvgPool.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" *Run this cell to enable the widget!*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown *Run this cell to enable the widget!*\n",
"\n",
"from IPython.display import HTML\n",
"\n",
"id_html = 3.3\n",
"url = f'https://raw.githubusercontent.com/NeuromatchAcademy/course-content-dl/main/tutorials/W2D2_ConvnetsAndDlThinking/static/interactive_demo{id_html}.html'\n",
"run_demo = False # @param {type:\"boolean\"}\n",
"if run_demo:\n",
" display(HTML(url))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_The_effect_of_the_stride_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 3.3: Implement MaxPooling\n",
"\n",
"Let us now implement MaxPooling in PyTorch and observe the effects of Pooling on the dimension of the input image. Use a kernel of size 2 and stride of 2 for the MaxPooling layer."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"class Net4(nn.Module):\n",
" \"\"\"\n",
" Neural Network instance\n",
" \"\"\"\n",
"\n",
" def __init__(self, padding=0, stride=2):\n",
" \"\"\"\n",
" Initialise parameters of Net4\n",
"\n",
" Args:\n",
" padding: int or tuple, optional\n",
" Zero-padding added to both sides of the input. Default: 0\n",
" stride: int\n",
" Stride\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" super(Net4, self).__init__()\n",
" self.conv1 = nn.Conv2d(in_channels=1, out_channels=3, kernel_size=5,\n",
" padding=padding)\n",
"\n",
" # First kernel - leading diagonal\n",
" kernel_1 = torch.Tensor([[[1., 1., -1., -1., -1.],\n",
" [1., 1., 1., -1., -1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [-1., -1., 1., 1., 1.],\n",
" [-1., -1., -1., 1., 1.]]])\n",
"\n",
" # Second kernel - other diagonal\n",
" kernel_2 = torch.Tensor([[[-1., -1., -1., 1., 1.],\n",
" [-1., -1., 1., 1., 1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [1., 1., 1., -1., -1.],\n",
" [1., 1., -1., -1., -1.]]])\n",
"\n",
" # Third kernel -checkerboard pattern\n",
" kernel_3 = torch.Tensor([[[1., 1., -1., 1., 1.],\n",
" [1., 1., 1., 1., 1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [1., 1., 1., 1., 1.],\n",
" [1., 1., -1., 1., 1.]]])\n",
"\n",
"\n",
" # Stack all kernels in one tensor with (3, 1, 5, 5) dimensions\n",
" multiple_kernels = torch.stack([kernel_1, kernel_2, kernel_3], dim=0)\n",
"\n",
" self.conv1.weight = torch.nn.Parameter(multiple_kernels)\n",
"\n",
" # Negative bias\n",
" self.conv1.bias = torch.nn.Parameter(torch.Tensor([-4, -4, -12]))\n",
" ####################################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Define the maxpool layer\")\n",
" ####################################################################\n",
" self.pool = nn.MaxPool2d(kernel_size=..., stride=...)\n",
"\n",
" def forward(self, x):\n",
" \"\"\"\n",
" Forward Pass of Net4\n",
"\n",
" Args:\n",
" x: torch.tensor\n",
" Input features\n",
"\n",
" Returns:\n",
" x: torch.tensor\n",
" Convolution + ReLU output\n",
" \"\"\"\n",
" x = self.conv1(x)\n",
" x = F.relu(x)\n",
" ####################################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Define the maxpool layer\")\n",
" ####################################################################\n",
" x = ... # Pass through a max pool layer\n",
" return x\n",
"\n",
"\n",
"\n",
"## Check if your implementation is correct\n",
"# net4 = Net4().to(DEVICE)\n",
"# check_pooling_net(net4, device=DEVICE)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"```\n",
"✅ Your network produced the correct output.\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_168b8fcf.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Implement_MaxPooling_Exercise\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"x_img = emnist_train[x_img_idx][0].unsqueeze(dim=0).to(DEVICE)\n",
"output_x_pool = net4(x_img)\n",
"output_x_pool = output_x_pool.squeeze(dim=0).detach().cpu().numpy()\n",
"\n",
"o_img = emnist_train[o_img_idx][0].unsqueeze(dim=0).to(DEVICE)\n",
"output_o_pool = net4(o_img)\n",
"output_o_pool = output_o_pool.squeeze(dim=0).detach().cpu().numpy()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" *Run the cell to plot the outputs!*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown *Run the cell to plot the outputs!*\n",
"\n",
"fig, ((ax11, ax12, ax13, ax14),\n",
" (ax21, ax22, ax23, ax24),\n",
" (ax31, ax32, ax33, ax34)) = plt.subplots(3, 4)\n",
"# Show the filters\n",
"ax11.axis(\"off\")\n",
"ax12.set_title(\"filter 1\")\n",
"ax12.imshow(net4.conv1.weight[0, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax13.set_title(\"filter 2\")\n",
"ax13.imshow(net4.conv1.weight[1, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax14.set_title(\"filter 3\")\n",
"ax14.imshow(net4.conv1.weight[2, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"\n",
"vmin, vmax = -6, 10\n",
"# Show x and the filters applied to x\n",
"ax21.set_title(\"image x\")\n",
"ax21.imshow(emnist_train[x_img_idx][0].reshape(28, 28), cmap='gray')\n",
"ax22.set_title(\"output filter 1\")\n",
"ax22.imshow(output_x_pool[0], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax23.set_title(\"output filter 2\")\n",
"ax23.imshow(output_x_pool[1], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax24.set_title(\"output filter 3\")\n",
"ax24.imshow(output_x_pool[2], cmap='gray', vmin=vmin, vmax=vmax)\n",
"\n",
"# Show o and the filters applied to o\n",
"ax31.set_title(\"image o\")\n",
"ax31.imshow(emnist_train[o_img_idx][0].reshape(28, 28), cmap='gray')\n",
"ax32.set_title(\"output filter 1\")\n",
"ax32.imshow(output_o_pool[0], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax33.set_title(\"output filter 2\")\n",
"ax33.imshow(output_o_pool[1], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax34.set_title(\"output filter 3\")\n",
"ax34.imshow(output_o_pool[2], cmap='gray', vmin=vmin, vmax=vmax)\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"You should observe the size of the output as being half of what you saw after the ReLU section, which is due to the Maxpool layer.\n",
"\n",
"Despite the reduction in the size of the output, the important or high-level features in the output still remains intact."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 4: Putting it all together\n",
"\n",
"*Time estimate: ~33mins*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 5: Putting it all together\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 5: Putting it all together\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', '-TJixd9fRCw'), ('Bilibili', 'BV1Fy4y1j7dU')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Putting_it_all_together_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 4.1: Number of Parameters in Convolutional vs. Fully-connected Models\n",
"Convolutional networks encourage weight-sharing by learning a single kernel that is repeated over the entire input image. In general, this kernel is just a few parameters, compared to the huge number of parameters in a dense network.\n",
"\n",
"Let's use the animation below to calculate few-layer network parameters for image data of shape $32\\times32$ using both convolutional layers and dense layers. The `Num_Dense` in this exercise is the number of dense layers we use in the network, with each dense layer having the same input and output dimensions. `Num_Convs` is the number of convolutional blocks in the network, with each block containing a single kernel. The kernel size is the length and width of this kernel.\n",
"\n",
"**Note:** you must run the cell before you can use the sliders.\n",
"\n",
" \n",
"
 "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 1: Introduction to CNNs\n",
"\n",
"**Week 2, Day 2: Convnets and DL Thinking**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"__Content creators:__ Dawn Estes McKnight, Richard Gerum, Cassidy Pirlot, Rohan Saha, Liam Peet-Pare, Saeed Najafi, Alona Fyshe\n",
"\n",
"__Content reviewers:__ Saeed Salehi, Lily Cheng, Yu-Fang Yang, Polina Turishcheva, Bettina Hein, Kelson Shilling-Scrivo\n",
"\n",
"__Content editors:__ Gagana B, Nina Kudryashova, Anmol Gupta, Xiaoxiong Lin, Spiros Chavlis\n",
"\n",
"__Production editors:__ Alex Tran-Van-Minh, Gagana B, Spiros Chavlis\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 1: Introduction to CNNs\n",
"\n",
"**Week 2, Day 2: Convnets and DL Thinking**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"__Content creators:__ Dawn Estes McKnight, Richard Gerum, Cassidy Pirlot, Rohan Saha, Liam Peet-Pare, Saeed Najafi, Alona Fyshe\n",
"\n",
"__Content reviewers:__ Saeed Salehi, Lily Cheng, Yu-Fang Yang, Polina Turishcheva, Bettina Hein, Kelson Shilling-Scrivo\n",
"\n",
"__Content editors:__ Gagana B, Nina Kudryashova, Anmol Gupta, Xiaoxiong Lin, Spiros Chavlis\n",
"\n",
"__Production editors:__ Alex Tran-Van-Minh, Gagana B, Spiros Chavlis\n",
"\n",
" \n",
"
\n",
"  \n",
"\n",
"Adopted from A. Zhang, Z. C. Lipton, M. Li and A. J. Smola, _[Dive into Deep Learning](http://d2l.ai/chapter_convolutional-neural-networks/conv-layer.html)_.\n",
"\n",
"
\n",
"\n",
"Adopted from A. Zhang, Z. C. Lipton, M. Li and A. J. Smola, _[Dive into Deep Learning](http://d2l.ai/chapter_convolutional-neural-networks/conv-layer.html)_.\n",
"\n",
" \n",
"\n",
"
\n",
"\n",
" \n",
"\n",
"
\n",
"\n",
" \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Convolution_of_a_simple_kernel_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 2.2: Convolution Output Size\n",
"\n",
"Now, you have manually calculated a convolution. How did this change the shape of the output? When you know the shapes of the input matrix and kernel, what is the shape of the output?\n",
"\n",
"**Hint:** If you have problems figuring out what the output shape should look like, go back to the visualisation and see how the output shape changes as you modify the image and kernel size."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def calculate_output_shape(image_shape, kernel_shape):\n",
" \"\"\"\n",
" Helper function to calculate output shape\n",
"\n",
" Args:\n",
" image_shape: tuple\n",
" Image shape\n",
" kernel_shape: tuple\n",
" Kernel shape\n",
"\n",
" Returns:\n",
" output_height: int\n",
" Output Height\n",
" output_width: int\n",
" Output Width\n",
" \"\"\"\n",
" image_height, image_width = image_shape\n",
" kernel_height, kernel_width = kernel_shape\n",
" ####################################################################\n",
" # Fill in missing code below, then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Fill in the lines below, then delete this\")\n",
" ####################################################################\n",
" output_height = ...\n",
" output_width = ...\n",
" return output_height, output_width\n",
"\n",
"\n",
"\n",
"# Here we check if your function works correcly by applying it to different image\n",
"# and kernel shapes\n",
"# check_shape_function(calculate_output_shape, image_shape=(3, 3), kernel_shape=(2, 2))\n",
"# check_shape_function(calculate_output_shape, image_shape=(3, 4), kernel_shape=(2, 3))\n",
"# check_shape_function(calculate_output_shape, image_shape=(5, 5), kernel_shape=(5, 5))\n",
"# check_shape_function(calculate_output_shape, image_shape=(10, 20), kernel_shape=(3, 2))\n",
"# check_shape_function(calculate_output_shape, image_shape=(100, 200), kernel_shape=(40, 30))"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_7c652c63.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Convolution_output_size_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 2.3: Coding a Convolution\n",
"\n",
"Here, we have the skeleton of a function that performs convolution using the provided image and kernel matrices.\n",
"\n",
"*Exercise:* Fill in the missing lines of code. You can test your function by uncommenting the sections beneath it.\n",
"\n",
"Note: in more general situations, once you understand convolutions, you can use functions already available in `pytorch`/`numpy` to perform convolution (such as `scipy.signal.correlate2d` or `scipy.signal.convolve2d`)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def convolution2d(image, kernel):\n",
" \"\"\"\n",
" Convolves a 2D image matrix with a kernel matrix.\n",
"\n",
" Args:\n",
" image: np.ndarray\n",
" Image\n",
" kernel: np.ndarray\n",
" Kernel\n",
"\n",
" Returns:\n",
" output: np.ndarray\n",
" Output of convolution\n",
" \"\"\"\n",
"\n",
" # Get the height/width of the image, kernel, and output\n",
" im_h, im_w = image.shape\n",
" ker_h, ker_w = kernel.shape\n",
" out_h = im_h - ker_h + 1\n",
" out_w = im_w - ker_w + 1\n",
"\n",
" # Create an empty matrix in which to store the output\n",
" output = np.zeros((out_h, out_w))\n",
"\n",
" # Iterate over the different positions at which to apply the kernel,\n",
" # storing the results in the output matrix\n",
" for out_row in range(out_h):\n",
" for out_col in range(out_w):\n",
" # Overlay the kernel on part of the image\n",
" # (multiply each element of the kernel with some element of the image, then sum)\n",
" # to determine the output of the matrix at a point\n",
" current_product = 0\n",
" for i in range(ker_h):\n",
" for j in range(ker_w):\n",
" ####################################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Implement the convolution function\")\n",
" ####################################################################\n",
" current_product += ...\n",
"\n",
" output[out_row, out_col] = current_product\n",
"\n",
" return output\n",
"\n",
"\n",
"\n",
"## Tests\n",
"# First, we test the parameters we used before in the manual-calculation example\n",
"image = np.array([[0, 200, 200], [0, 0, 200], [0, 0, 0]])\n",
"kernel = np.array([[0.25, 0.25], [0.25, 0.25]])\n",
"# check_conv_function(convolution2d, image, kernel)\n",
"\n",
"# Next, we test with a different input and kernel (the numbers 1-9 and 1-4)\n",
"image = np.arange(9).reshape(3, 3)\n",
"kernel = np.arange(4).reshape(2, 2)\n",
"# check_conv_function(convolution2d, image, kernel)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_4f643447.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Coding_a_Convolution_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Convolution on the Chicago Skyline\n",
"\n",
"After you have finished programming the above convolution function, run the coding cell below, which applies two different kernels to a greyscale picture of Chicago and takes the geometric average of the results.\n",
"\n",
"**Make sure you remove all print statements from your convolution2d implementation, or this will run for a _very_ long time.** It should take somewhere between 10 seconds and 1 minute.\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" ### Load images (run me)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown ### Load images (run me)\n",
"\n",
"import requests, os\n",
"\n",
"if not os.path.exists('images/'):\n",
" os.mkdir('images/')\n",
"\n",
"url = \"https://raw.githubusercontent.com/NeuromatchAcademy/course-content-dl/main/tutorials/W2D2_ConvnetsAndDlThinking/static/chicago_skyline_shrunk_v2.bmp\"\n",
"r = requests.get(url, allow_redirects=True)\n",
"with open(\"images/chicago_skyline_shrunk_v2.bmp\", 'wb') as fd:\n",
" fd.write(r.content)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Visualize the output of your function\n",
"from IPython.display import display as IPydisplay\n",
"\n",
"with open(\"images/chicago_skyline_shrunk_v2.bmp\", 'rb') as skyline_image_file:\n",
" img_skyline_orig = Image.open(skyline_image_file)\n",
" img_skyline_mat = np.asarray(img_skyline_orig)\n",
" kernel_ver = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]])\n",
" kernel_hor = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]).T\n",
" img_processed_mat_ver = convolution2d(img_skyline_mat, kernel_ver)\n",
" img_processed_mat_hor = convolution2d(img_skyline_mat, kernel_hor)\n",
" img_processed_mat = np.sqrt(np.multiply(img_processed_mat_ver,\n",
" img_processed_mat_ver) + \\\n",
" np.multiply(img_processed_mat_hor,\n",
" img_processed_mat_hor))\n",
"\n",
" img_processed_mat *= 255.0/img_processed_mat.max()\n",
" img_processed_mat = img_processed_mat.astype(np.uint8)\n",
" img_processed = Image.fromarray(img_processed_mat, 'L')\n",
" width, height = img_skyline_orig.size\n",
" scale = 0.6\n",
" IPydisplay(img_skyline_orig.resize((int(width*scale), int(height*scale))),\n",
" Image.NEAREST)\n",
" IPydisplay(img_processed.resize((int(width*scale), int(height*scale))),\n",
" Image.NEAREST)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Pretty cool, right? We will go into more detail on what's happening in the next section."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 2.1: Demonstration of a CNN in PyTorch\n",
"At this point, you should have a fair idea of how to perform a convolution on an image given a kernel. In the following cell, we provide a code snippet that demonstrates setting up a convolutional network using PyTorch.\n",
"\n",
"We look at the `nn` module in PyTorch. The `nn` module contains a plethora of functions that will make implementing a neural network easier. In particular we will look at the `nn.Conv2d()` function, which creates a convolutional layer that is applied to whatever image that you feed the resulting network.\n",
"\n",
"Look at the code below. In it, we define a `Net` class that you can instantiate with a kernel to create a Neural Network object. When you apply the network object to an image (or anything in the form of a matrix), it convolves the kernel over that image."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"class Net(nn.Module):\n",
" \"\"\"\n",
" A convolutional neural network class.\n",
" When an instance of it is constructed with a kernel, you can apply that instance\n",
" to a matrix and it will convolve the kernel over that image.\n",
" i.e. Net(kernel)(image)\n",
" \"\"\"\n",
"\n",
" def __init__(self, kernel=None, padding=0):\n",
" super(Net, self).__init__()\n",
" \"\"\"\n",
" Summary of the nn.conv2d parameters (you can also get this by hovering\n",
" over the method):\n",
" - in_channels (int): Number of channels in the input image\n",
" - out_channels (int): Number of channels produced by the convolution\n",
" - kernel_size (int or tuple): Size of the convolving kernel\n",
"\n",
" Args:\n",
" padding: int or tuple, optional\n",
" Zero-padding added to both sides of the input. Default: 0\n",
" kernel: np.ndarray\n",
" Convolving kernel. Default: None\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" self.conv1 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=2,\n",
" padding=padding)\n",
"\n",
" # Set up a default kernel if a default one isn't provided\n",
" if kernel is not None:\n",
" dim1, dim2 = kernel.shape[0], kernel.shape[1]\n",
" kernel = kernel.reshape(1, 1, dim1, dim2)\n",
"\n",
" self.conv1.weight = torch.nn.Parameter(kernel)\n",
" self.conv1.bias = torch.nn.Parameter(torch.zeros_like(self.conv1.bias))\n",
"\n",
" def forward(self, x):\n",
" \"\"\"\n",
" Forward Pass of nn.conv2d\n",
"\n",
" Args:\n",
" x: torch.tensor\n",
" Input features\n",
"\n",
" Returns:\n",
" x: torch.tensor\n",
" Convolution output\n",
" \"\"\"\n",
" x = self.conv1(x)\n",
" return x"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Format a default 2x2 kernel of numbers from 0 through 3\n",
"kernel = torch.Tensor(np.arange(4).reshape(2, 2))\n",
"\n",
"# Prepare the network with that default kernel\n",
"net = Net(kernel=kernel, padding=0).to(DEVICE)\n",
"\n",
"# Set up a 3x3 image matrix of numbers from 0 through 8\n",
"image = torch.Tensor(np.arange(9).reshape(3, 3))\n",
"image = image.reshape(1, 1, 3, 3).to(DEVICE) # BatchSize X Channels X Height X Width\n",
"\n",
"print(\"Image:\\n\" + str(image))\n",
"print(\"Kernel:\\n\" + str(kernel))\n",
"output = net(image) # Apply the convolution\n",
"print(\"Output:\\n\" + str(output))"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As a quick aside, notice the difference in the input and output size. The input had a size of 3×3, and the output is of size 2×2. This is because of the fact that the kernel can't produce values for the edges of the image - when it slides to an end of the image and is centered on a border pixel, it overlaps space outside of the image that is undefined. If we don't want to lose that information, we will have to pad the image with some defaults (such as 0s) on the border. This process is, somewhat predictably, called *padding*. We will talk more about padding in the next section."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"print(\"Image (before padding):\\n\" + str(image))\n",
"print(\"Kernel:\\n\" + str(kernel))\n",
"\n",
"# Prepare the network with the aforementioned default kernel, but this\n",
"# time with padding\n",
"net = Net(kernel=kernel, padding=1).to(DEVICE)\n",
"output = net(image) # Apply the convolution onto the padded image\n",
"print(\"Output:\\n\" + str(output))"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 2.2: Padding and Edge Detection"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Before we start in on the exercises, here's a visualization to help you think about padding."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 2.2: Visualization of Convolution with Padding and Stride\n",
"\n",
"\n",
"Recall that\n",
"* Padding adds rows and columns of zeros to the outside edge of an image\n",
"* Stride length adjusts the distance by which a filter is shifted after each convolution.\n",
"\n",
"Change the padding and stride and see how this affects the shape of the output. How does the padding need to be configured to maintain the shape of the input?"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Important:** Change the bool variable `run_demo` to `True` by ticking the box, in order to experiment with the demo. Due to video rendering on jupyter-book, we had to remove it from the automatic execution."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" *Run this cell to enable the widget!*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown *Run this cell to enable the widget!*\n",
"\n",
"from IPython.display import HTML\n",
"\n",
"id_html = 2.2\n",
"url = f'https://raw.githubusercontent.com/NeuromatchAcademy/course-content-dl/main/tutorials/W2D2_ConvnetsAndDlThinking/static/interactive_demo{id_html}.html'\n",
"run_demo = False # @param {type:\"boolean\"}\n",
"if run_demo:\n",
" display(HTML(url))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Visualization_of_Convolution_with_Padding_and_Stride_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! 2.2.1: Edge Detection"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"One of the simpler tasks performed by a convolutional layer is edge detection; that is, finding a place in the image where there is a large and abrupt change in color. Edge-detecting filters are usually learned by the first layers in a CNN. Observe the following simple kernel and discuss whether this will detect vertical edges (where the trace of the edge is vertical; i.e. there is a boundary between left and right), or whether it will detect horizontal edges (where the trace of the edge is horizontal; i.e., there is a boundary between top and bottom).\n",
"\n",
"\\begin{equation}\n",
"\\textbf{Kernel} =\n",
"\\begin{bmatrix} 1 & -1 \\\\ 1 & -1\n",
"\\end{bmatrix}\n",
"\\end{equation}"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_309474b2.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Edge_Detection_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Consider the image below, which has a black vertical stripe with white on the side. This is like a very zoomed-in vertical edge within an image!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Prepare an image that's basically just a vertical black stripe\n",
"X = np.ones((6, 8))\n",
"X[:, 2:6] = 0\n",
"print(X)\n",
"plt.imshow(X, cmap=plt.get_cmap('gray'))\n",
"plt.show()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Format the image that's basically just a vertical stripe\n",
"image = torch.from_numpy(X)\n",
"image = image.reshape(1, 1, 6, 8) # BatchSize X Channels X Height X Width\n",
"\n",
"# Prepare a 2x2 kernel with 1s in the first column and -1s in the\n",
"# This exact kernel was discussed above!\n",
"kernel = torch.Tensor([[1.0, -1.0], [1.0, -1.0]])\n",
"net = Net(kernel=kernel)\n",
"\n",
"# Apply the kernel to the image and prepare for display\n",
"processed_image = net(image.float())\n",
"processed_image = processed_image.reshape(5, 7).detach().numpy()\n",
"print(processed_image)\n",
"plt.imshow(processed_image, cmap=plt.get_cmap('gray'))\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As you can see, this kernel detects vertical edges (the black stripe corresponds to a highly positive result, while the white stripe corresponds to a highly negative result. However, to display the image, all the pixels are normalized between 0=black and 1=white)."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! 2.2.2 Kernel structure\n",
"\n",
"If the kernel were transposed (i.e., the columns become rows and the rows become columns), what would the kernel detect? What would be produced by running this kernel on the vertical edge image above?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_7cc3340b.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Kernel_structure_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 3: Kernels, Pooling and Subsampling\n",
"\n",
"*Time estimate: ~50mins*"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"To visualize the various components of a CNN, we will build a simple CNN step by step. Recall that the MNIST dataset consists of binarized images of handwritten digits. This time, we will use the EMNIST letters dataset, which consists of binarized images of handwritten characters $(A, ..., Z)$.\n",
"\n",
"We will simplify the problem further by only keeping the images that correspond to $X$ (labeled as `24` in the dataset) and $O$ (labeled as `15` in the dataset). Then, we will train a CNN to classify an image either an $X$ or an $O$."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Download EMNIST dataset\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Download EMNIST dataset\n",
"\n",
"# webpage: https://www.itl.nist.gov/iaui/vip/cs_links/EMNIST/gzip.zip\n",
"fname = 'EMNIST.zip'\n",
"folder = 'EMNIST'\n",
"url = \"https://osf.io/xwfaj/download\"\n",
"download_data(fname, folder, url, tar=False)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Dataset/DataLoader Functions *(Run me!)*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Dataset/DataLoader Functions *(Run me!)*\n",
"\n",
"def get_Xvs0_dataset(normalize=False, download=False):\n",
" \"\"\"\n",
" Load Dataset\n",
"\n",
" Args:\n",
" normalize: boolean\n",
" If true, normalise dataloader\n",
" download: boolean\n",
" If true, download dataset\n",
"\n",
" Returns:\n",
" emnist_train: torch.loader\n",
" Training Data\n",
" emnist_test: torch.loader\n",
" Test Data\n",
" \"\"\"\n",
" if normalize:\n",
" transform = transforms.Compose([\n",
" transforms.ToTensor(),\n",
" transforms.Normalize((0.1307,), (0.3081,))\n",
" ])\n",
" else:\n",
" transform = transforms.Compose([\n",
" transforms.ToTensor(),\n",
" ])\n",
"\n",
" emnist_train = datasets.EMNIST(root='.',\n",
" split='letters',\n",
" download=download,\n",
" train=True,\n",
" transform=transform)\n",
" emnist_test = datasets.EMNIST(root='.',\n",
" split='letters',\n",
" download=download,\n",
" train=False,\n",
" transform=transform)\n",
"\n",
" # Only want O (15) and X (24) labels\n",
" train_idx = (emnist_train.targets == 15) | (emnist_train.targets == 24)\n",
" emnist_train.targets = emnist_train.targets[train_idx]\n",
" emnist_train.data = emnist_train.data[train_idx]\n",
"\n",
" # Convert Xs predictions to 1, Os predictions to 0\n",
" emnist_train.targets = (emnist_train.targets == 24).type(torch.int64)\n",
"\n",
" test_idx = (emnist_test.targets == 15) | (emnist_test.targets == 24)\n",
" emnist_test.targets = emnist_test.targets[test_idx]\n",
" emnist_test.data = emnist_test.data[test_idx]\n",
"\n",
" # Convert Xs predictions to 1, Os predictions to 0\n",
" emnist_test.targets = (emnist_test.targets == 24).type(torch.int64)\n",
"\n",
" return emnist_train, emnist_test\n",
"\n",
"\n",
"def get_data_loaders(train_dataset, test_dataset,\n",
" batch_size=32, seed=0):\n",
" \"\"\"\n",
" Helper function to fetch dataloaders\n",
"\n",
" Args:\n",
" train_dataset: torch.tensor\n",
" Training data\n",
" test_dataset: torch.tensor\n",
" Test data\n",
" batch_size: int\n",
" Batch Size\n",
" seed: int\n",
" Set seed for reproducibility\n",
"\n",
" Returns:\n",
" emnist_train: torch.loader\n",
" Training Data\n",
" emnist_test: torch.loader\n",
" Test Data\n",
" \"\"\"\n",
" g_seed = torch.Generator()\n",
" g_seed.manual_seed(seed)\n",
"\n",
" train_loader = DataLoader(train_dataset,\n",
" batch_size=batch_size,\n",
" shuffle=True,\n",
" num_workers=2,\n",
" worker_init_fn=seed_worker,\n",
" generator=g_seed)\n",
" test_loader = DataLoader(test_dataset,\n",
" batch_size=batch_size,\n",
" shuffle=True,\n",
" num_workers=2,\n",
" worker_init_fn=seed_worker,\n",
" generator=g_seed)\n",
"\n",
" return train_loader, test_loader"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"emnist_train, emnist_test = get_Xvs0_dataset(normalize=False, download=False)\n",
"train_loader, test_loader = get_data_loaders(emnist_train, emnist_test,\n",
" seed=SEED)\n",
"\n",
"# Index of an image in the dataset that corresponds to an X and O\n",
"x_img_idx = 4\n",
"o_img_idx = 15"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Let's view a couple samples from the dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"fig, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4, figsize=(12, 6))\n",
"ax1.imshow(emnist_train[0][0].reshape(28, 28), cmap='gray')\n",
"ax2.imshow(emnist_train[10][0].reshape(28, 28), cmap='gray')\n",
"ax3.imshow(emnist_train[4][0].reshape(28, 28), cmap='gray')\n",
"ax4.imshow(emnist_train[6][0].reshape(28, 28), cmap='gray')\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Interactive Demo 3: Visualization of Convolution with Multiple Filters\n",
"\n",
"Change the number of input channels (e.g., the color channels of an image or the output channels of a previous layer) and the output channels (number of different filters to apply)."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Important:** Change the bool variable `run_demo` to `True` by ticking the box, in order to experiment with the demo. Due to video rendering on jupyter-book, we had to remove it from the automatic execution."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" *Run this cell to enable the widget!*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown *Run this cell to enable the widget!*\n",
"\n",
"from IPython.display import HTML\n",
"\n",
"id_html = 3\n",
"url = f'https://raw.githubusercontent.com/NeuromatchAcademy/course-content-dl/main/tutorials/W2D2_ConvnetsAndDlThinking/static/interactive_demo{id_html}.html'\n",
"run_demo = False # @param {type:\"boolean\"}\n",
"if run_demo:\n",
" display(HTML(url))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Visualization_of_Convolution_with_Multiple_Filters_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.1: Multiple Filters\n",
"\n",
"The following network sets up 3 filters and runs them on an image of the dataset from the $X$ class. Note that we are using \"thicker\" filters than those presented in the videos. Here, the filters are $5 \\times 5$, whereas in the videos $3 \\times 3$."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"class Net2(nn.Module):\n",
" \"\"\"\n",
" Neural Network instance\n",
" \"\"\"\n",
"\n",
" def __init__(self, padding=0):\n",
" \"\"\"\n",
" Initialize parameters of Net2\n",
"\n",
" Args:\n",
" padding: int or tuple, optional\n",
" Zero-padding added to both sides of the input. Default: 0\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" super(Net2, self).__init__()\n",
" self.conv1 = nn.Conv2d(in_channels=1, out_channels=3, kernel_size=5,\n",
" padding=padding)\n",
"\n",
" # First kernel - leading diagonal\n",
" kernel_1 = torch.Tensor([[[1., 1., -1., -1., -1.],\n",
" [1., 1., 1., -1., -1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [-1., -1., 1., 1., 1.],\n",
" [-1., -1., -1., 1., 1.]]])\n",
"\n",
" # Second kernel - other diagonal\n",
" kernel_2 = torch.Tensor([[[-1., -1., -1., 1., 1.],\n",
" [-1., -1., 1., 1., 1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [1., 1., 1., -1., -1.],\n",
" [1., 1., -1., -1., -1.]]])\n",
"\n",
" # tThird kernel - checkerboard pattern\n",
" kernel_3 = torch.Tensor([[[1., 1., -1., 1., 1.],\n",
" [1., 1., 1., 1., 1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [1., 1., 1., 1., 1.],\n",
" [1., 1., -1., 1., 1.]]])\n",
"\n",
"\n",
" # Stack all kernels in one tensor with (3, 1, 5, 5) dimensions\n",
" multiple_kernels = torch.stack([kernel_1, kernel_2, kernel_3], dim=0)\n",
"\n",
" self.conv1.weight = torch.nn.Parameter(multiple_kernels)\n",
"\n",
" # Negative bias\n",
" self.conv1.bias = torch.nn.Parameter(torch.Tensor([-4, -4, -12]))\n",
"\n",
" def forward(self, x):\n",
" \"\"\"\n",
" Forward Pass of Net2\n",
"\n",
" Args:\n",
" x: torch.tensor\n",
" Input features\n",
"\n",
" Returns:\n",
" x: torch.tensor\n",
" Convolution output\n",
" \"\"\"\n",
" x = self.conv1(x)\n",
" return x"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Note:** We add a negative bias to give a threshold to select the high output value, which corresponds to the features we want to detect (e.g., 45 degree oriented bar).\n",
"\n",
"Now, let's visualize the filters using the code given below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"net2 = Net2().to(DEVICE)\n",
"fig, (ax11, ax12, ax13) = plt.subplots(1, 3)\n",
"# Show the filters\n",
"ax11.set_title(\"filter 1\")\n",
"ax11.imshow(net2.conv1.weight[0, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax12.set_title(\"filter 2\")\n",
"ax12.imshow(net2.conv1.weight[1, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax13.set_title(\"filter 3\")\n",
"ax13.imshow(net2.conv1.weight[2, 0].detach().cpu().numpy(), cmap=\"gray\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! 3.1: Do you see how these filters would help recognize an `X`?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_800ed014.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Multiple_Filters_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We apply the filters to the images."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"net2 = Net2().to(DEVICE)\n",
"x_img = emnist_train[x_img_idx][0].unsqueeze(dim=0).to(DEVICE)\n",
"output_x = net2(x_img)\n",
"output_x = output_x.squeeze(dim=0).detach().cpu().numpy()\n",
"\n",
"o_img = emnist_train[o_img_idx][0].unsqueeze(dim=0).to(DEVICE)\n",
"output_o = net2(o_img)\n",
"output_o = output_o.squeeze(dim=0).detach().cpu().numpy()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Let us view the image of $X$ and $O$ and what the output of the filters applied to them looks like. Pay special attention to the areas with very high vs. very low output patterns."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"fig, ((ax11, ax12, ax13, ax14),\n",
" (ax21, ax22, ax23, ax24),\n",
" (ax31, ax32, ax33, ax34)) = plt.subplots(3, 4)\n",
"\n",
"# Show the filters\n",
"ax11.axis(\"off\")\n",
"ax12.set_title(\"filter 1\")\n",
"ax12.imshow(net2.conv1.weight[0, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax13.set_title(\"filter 2\")\n",
"ax13.imshow(net2.conv1.weight[1, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax14.set_title(\"filter 3\")\n",
"ax14.imshow(net2.conv1.weight[2, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"\n",
"vmin, vmax = -6, 10\n",
"# Show x and the filters applied to x\n",
"ax21.set_title(\"image x\")\n",
"ax21.imshow(emnist_train[x_img_idx][0].reshape(28, 28), cmap='gray')\n",
"ax22.set_title(\"output filter 1\")\n",
"ax22.imshow(output_x[0], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax23.set_title(\"output filter 2\")\n",
"ax23.imshow(output_x[1], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax24.set_title(\"output filter 3\")\n",
"ax24.imshow(output_x[2], cmap='gray', vmin=vmin, vmax=vmax)\n",
"\n",
"# Show o and the filters applied to o\n",
"ax31.set_title(\"image o\")\n",
"ax31.imshow(emnist_train[o_img_idx][0].reshape(28, 28), cmap='gray')\n",
"ax32.set_title(\"output filter 1\")\n",
"ax32.imshow(output_o[0], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax33.set_title(\"output filter 2\")\n",
"ax33.imshow(output_o[1], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax34.set_title(\"output filter 3\")\n",
"ax34.imshow(output_o[2], cmap='gray', vmin=vmin, vmax=vmax)\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.2: ReLU after convolutions\n",
"\n",
"Up until now we've talked about the convolution operation, which is linear. But the real strength of neural networks comes from the incorporation of non-linear functions. Furthermore, in the real world, we often have learning problems where the relationship between the input and output is non-linear and complex.\n",
"\n",
"The ReLU (Rectified Linear Unit) introduces non-linearity into our model, allowing us to learn a more complex function that can better predict the class of an image.\n",
"\n",
"The ReLU function is shown below.\n",
"\n",
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Convolution_of_a_simple_kernel_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 2.2: Convolution Output Size\n",
"\n",
"Now, you have manually calculated a convolution. How did this change the shape of the output? When you know the shapes of the input matrix and kernel, what is the shape of the output?\n",
"\n",
"**Hint:** If you have problems figuring out what the output shape should look like, go back to the visualisation and see how the output shape changes as you modify the image and kernel size."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def calculate_output_shape(image_shape, kernel_shape):\n",
" \"\"\"\n",
" Helper function to calculate output shape\n",
"\n",
" Args:\n",
" image_shape: tuple\n",
" Image shape\n",
" kernel_shape: tuple\n",
" Kernel shape\n",
"\n",
" Returns:\n",
" output_height: int\n",
" Output Height\n",
" output_width: int\n",
" Output Width\n",
" \"\"\"\n",
" image_height, image_width = image_shape\n",
" kernel_height, kernel_width = kernel_shape\n",
" ####################################################################\n",
" # Fill in missing code below, then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Fill in the lines below, then delete this\")\n",
" ####################################################################\n",
" output_height = ...\n",
" output_width = ...\n",
" return output_height, output_width\n",
"\n",
"\n",
"\n",
"# Here we check if your function works correcly by applying it to different image\n",
"# and kernel shapes\n",
"# check_shape_function(calculate_output_shape, image_shape=(3, 3), kernel_shape=(2, 2))\n",
"# check_shape_function(calculate_output_shape, image_shape=(3, 4), kernel_shape=(2, 3))\n",
"# check_shape_function(calculate_output_shape, image_shape=(5, 5), kernel_shape=(5, 5))\n",
"# check_shape_function(calculate_output_shape, image_shape=(10, 20), kernel_shape=(3, 2))\n",
"# check_shape_function(calculate_output_shape, image_shape=(100, 200), kernel_shape=(40, 30))"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_7c652c63.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Convolution_output_size_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 2.3: Coding a Convolution\n",
"\n",
"Here, we have the skeleton of a function that performs convolution using the provided image and kernel matrices.\n",
"\n",
"*Exercise:* Fill in the missing lines of code. You can test your function by uncommenting the sections beneath it.\n",
"\n",
"Note: in more general situations, once you understand convolutions, you can use functions already available in `pytorch`/`numpy` to perform convolution (such as `scipy.signal.correlate2d` or `scipy.signal.convolve2d`)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def convolution2d(image, kernel):\n",
" \"\"\"\n",
" Convolves a 2D image matrix with a kernel matrix.\n",
"\n",
" Args:\n",
" image: np.ndarray\n",
" Image\n",
" kernel: np.ndarray\n",
" Kernel\n",
"\n",
" Returns:\n",
" output: np.ndarray\n",
" Output of convolution\n",
" \"\"\"\n",
"\n",
" # Get the height/width of the image, kernel, and output\n",
" im_h, im_w = image.shape\n",
" ker_h, ker_w = kernel.shape\n",
" out_h = im_h - ker_h + 1\n",
" out_w = im_w - ker_w + 1\n",
"\n",
" # Create an empty matrix in which to store the output\n",
" output = np.zeros((out_h, out_w))\n",
"\n",
" # Iterate over the different positions at which to apply the kernel,\n",
" # storing the results in the output matrix\n",
" for out_row in range(out_h):\n",
" for out_col in range(out_w):\n",
" # Overlay the kernel on part of the image\n",
" # (multiply each element of the kernel with some element of the image, then sum)\n",
" # to determine the output of the matrix at a point\n",
" current_product = 0\n",
" for i in range(ker_h):\n",
" for j in range(ker_w):\n",
" ####################################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Implement the convolution function\")\n",
" ####################################################################\n",
" current_product += ...\n",
"\n",
" output[out_row, out_col] = current_product\n",
"\n",
" return output\n",
"\n",
"\n",
"\n",
"## Tests\n",
"# First, we test the parameters we used before in the manual-calculation example\n",
"image = np.array([[0, 200, 200], [0, 0, 200], [0, 0, 0]])\n",
"kernel = np.array([[0.25, 0.25], [0.25, 0.25]])\n",
"# check_conv_function(convolution2d, image, kernel)\n",
"\n",
"# Next, we test with a different input and kernel (the numbers 1-9 and 1-4)\n",
"image = np.arange(9).reshape(3, 3)\n",
"kernel = np.arange(4).reshape(2, 2)\n",
"# check_conv_function(convolution2d, image, kernel)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_4f643447.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Coding_a_Convolution_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Convolution on the Chicago Skyline\n",
"\n",
"After you have finished programming the above convolution function, run the coding cell below, which applies two different kernels to a greyscale picture of Chicago and takes the geometric average of the results.\n",
"\n",
"**Make sure you remove all print statements from your convolution2d implementation, or this will run for a _very_ long time.** It should take somewhere between 10 seconds and 1 minute.\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" ### Load images (run me)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown ### Load images (run me)\n",
"\n",
"import requests, os\n",
"\n",
"if not os.path.exists('images/'):\n",
" os.mkdir('images/')\n",
"\n",
"url = \"https://raw.githubusercontent.com/NeuromatchAcademy/course-content-dl/main/tutorials/W2D2_ConvnetsAndDlThinking/static/chicago_skyline_shrunk_v2.bmp\"\n",
"r = requests.get(url, allow_redirects=True)\n",
"with open(\"images/chicago_skyline_shrunk_v2.bmp\", 'wb') as fd:\n",
" fd.write(r.content)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Visualize the output of your function\n",
"from IPython.display import display as IPydisplay\n",
"\n",
"with open(\"images/chicago_skyline_shrunk_v2.bmp\", 'rb') as skyline_image_file:\n",
" img_skyline_orig = Image.open(skyline_image_file)\n",
" img_skyline_mat = np.asarray(img_skyline_orig)\n",
" kernel_ver = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]])\n",
" kernel_hor = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]).T\n",
" img_processed_mat_ver = convolution2d(img_skyline_mat, kernel_ver)\n",
" img_processed_mat_hor = convolution2d(img_skyline_mat, kernel_hor)\n",
" img_processed_mat = np.sqrt(np.multiply(img_processed_mat_ver,\n",
" img_processed_mat_ver) + \\\n",
" np.multiply(img_processed_mat_hor,\n",
" img_processed_mat_hor))\n",
"\n",
" img_processed_mat *= 255.0/img_processed_mat.max()\n",
" img_processed_mat = img_processed_mat.astype(np.uint8)\n",
" img_processed = Image.fromarray(img_processed_mat, 'L')\n",
" width, height = img_skyline_orig.size\n",
" scale = 0.6\n",
" IPydisplay(img_skyline_orig.resize((int(width*scale), int(height*scale))),\n",
" Image.NEAREST)\n",
" IPydisplay(img_processed.resize((int(width*scale), int(height*scale))),\n",
" Image.NEAREST)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Pretty cool, right? We will go into more detail on what's happening in the next section."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 2.1: Demonstration of a CNN in PyTorch\n",
"At this point, you should have a fair idea of how to perform a convolution on an image given a kernel. In the following cell, we provide a code snippet that demonstrates setting up a convolutional network using PyTorch.\n",
"\n",
"We look at the `nn` module in PyTorch. The `nn` module contains a plethora of functions that will make implementing a neural network easier. In particular we will look at the `nn.Conv2d()` function, which creates a convolutional layer that is applied to whatever image that you feed the resulting network.\n",
"\n",
"Look at the code below. In it, we define a `Net` class that you can instantiate with a kernel to create a Neural Network object. When you apply the network object to an image (or anything in the form of a matrix), it convolves the kernel over that image."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"class Net(nn.Module):\n",
" \"\"\"\n",
" A convolutional neural network class.\n",
" When an instance of it is constructed with a kernel, you can apply that instance\n",
" to a matrix and it will convolve the kernel over that image.\n",
" i.e. Net(kernel)(image)\n",
" \"\"\"\n",
"\n",
" def __init__(self, kernel=None, padding=0):\n",
" super(Net, self).__init__()\n",
" \"\"\"\n",
" Summary of the nn.conv2d parameters (you can also get this by hovering\n",
" over the method):\n",
" - in_channels (int): Number of channels in the input image\n",
" - out_channels (int): Number of channels produced by the convolution\n",
" - kernel_size (int or tuple): Size of the convolving kernel\n",
"\n",
" Args:\n",
" padding: int or tuple, optional\n",
" Zero-padding added to both sides of the input. Default: 0\n",
" kernel: np.ndarray\n",
" Convolving kernel. Default: None\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" self.conv1 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=2,\n",
" padding=padding)\n",
"\n",
" # Set up a default kernel if a default one isn't provided\n",
" if kernel is not None:\n",
" dim1, dim2 = kernel.shape[0], kernel.shape[1]\n",
" kernel = kernel.reshape(1, 1, dim1, dim2)\n",
"\n",
" self.conv1.weight = torch.nn.Parameter(kernel)\n",
" self.conv1.bias = torch.nn.Parameter(torch.zeros_like(self.conv1.bias))\n",
"\n",
" def forward(self, x):\n",
" \"\"\"\n",
" Forward Pass of nn.conv2d\n",
"\n",
" Args:\n",
" x: torch.tensor\n",
" Input features\n",
"\n",
" Returns:\n",
" x: torch.tensor\n",
" Convolution output\n",
" \"\"\"\n",
" x = self.conv1(x)\n",
" return x"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Format a default 2x2 kernel of numbers from 0 through 3\n",
"kernel = torch.Tensor(np.arange(4).reshape(2, 2))\n",
"\n",
"# Prepare the network with that default kernel\n",
"net = Net(kernel=kernel, padding=0).to(DEVICE)\n",
"\n",
"# Set up a 3x3 image matrix of numbers from 0 through 8\n",
"image = torch.Tensor(np.arange(9).reshape(3, 3))\n",
"image = image.reshape(1, 1, 3, 3).to(DEVICE) # BatchSize X Channels X Height X Width\n",
"\n",
"print(\"Image:\\n\" + str(image))\n",
"print(\"Kernel:\\n\" + str(kernel))\n",
"output = net(image) # Apply the convolution\n",
"print(\"Output:\\n\" + str(output))"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As a quick aside, notice the difference in the input and output size. The input had a size of 3×3, and the output is of size 2×2. This is because of the fact that the kernel can't produce values for the edges of the image - when it slides to an end of the image and is centered on a border pixel, it overlaps space outside of the image that is undefined. If we don't want to lose that information, we will have to pad the image with some defaults (such as 0s) on the border. This process is, somewhat predictably, called *padding*. We will talk more about padding in the next section."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"print(\"Image (before padding):\\n\" + str(image))\n",
"print(\"Kernel:\\n\" + str(kernel))\n",
"\n",
"# Prepare the network with the aforementioned default kernel, but this\n",
"# time with padding\n",
"net = Net(kernel=kernel, padding=1).to(DEVICE)\n",
"output = net(image) # Apply the convolution onto the padded image\n",
"print(\"Output:\\n\" + str(output))"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 2.2: Padding and Edge Detection"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Before we start in on the exercises, here's a visualization to help you think about padding."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 2.2: Visualization of Convolution with Padding and Stride\n",
"\n",
"\n",
"Recall that\n",
"* Padding adds rows and columns of zeros to the outside edge of an image\n",
"* Stride length adjusts the distance by which a filter is shifted after each convolution.\n",
"\n",
"Change the padding and stride and see how this affects the shape of the output. How does the padding need to be configured to maintain the shape of the input?"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Important:** Change the bool variable `run_demo` to `True` by ticking the box, in order to experiment with the demo. Due to video rendering on jupyter-book, we had to remove it from the automatic execution."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" *Run this cell to enable the widget!*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown *Run this cell to enable the widget!*\n",
"\n",
"from IPython.display import HTML\n",
"\n",
"id_html = 2.2\n",
"url = f'https://raw.githubusercontent.com/NeuromatchAcademy/course-content-dl/main/tutorials/W2D2_ConvnetsAndDlThinking/static/interactive_demo{id_html}.html'\n",
"run_demo = False # @param {type:\"boolean\"}\n",
"if run_demo:\n",
" display(HTML(url))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Visualization_of_Convolution_with_Padding_and_Stride_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! 2.2.1: Edge Detection"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"One of the simpler tasks performed by a convolutional layer is edge detection; that is, finding a place in the image where there is a large and abrupt change in color. Edge-detecting filters are usually learned by the first layers in a CNN. Observe the following simple kernel and discuss whether this will detect vertical edges (where the trace of the edge is vertical; i.e. there is a boundary between left and right), or whether it will detect horizontal edges (where the trace of the edge is horizontal; i.e., there is a boundary between top and bottom).\n",
"\n",
"\\begin{equation}\n",
"\\textbf{Kernel} =\n",
"\\begin{bmatrix} 1 & -1 \\\\ 1 & -1\n",
"\\end{bmatrix}\n",
"\\end{equation}"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_309474b2.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Edge_Detection_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Consider the image below, which has a black vertical stripe with white on the side. This is like a very zoomed-in vertical edge within an image!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Prepare an image that's basically just a vertical black stripe\n",
"X = np.ones((6, 8))\n",
"X[:, 2:6] = 0\n",
"print(X)\n",
"plt.imshow(X, cmap=plt.get_cmap('gray'))\n",
"plt.show()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Format the image that's basically just a vertical stripe\n",
"image = torch.from_numpy(X)\n",
"image = image.reshape(1, 1, 6, 8) # BatchSize X Channels X Height X Width\n",
"\n",
"# Prepare a 2x2 kernel with 1s in the first column and -1s in the\n",
"# This exact kernel was discussed above!\n",
"kernel = torch.Tensor([[1.0, -1.0], [1.0, -1.0]])\n",
"net = Net(kernel=kernel)\n",
"\n",
"# Apply the kernel to the image and prepare for display\n",
"processed_image = net(image.float())\n",
"processed_image = processed_image.reshape(5, 7).detach().numpy()\n",
"print(processed_image)\n",
"plt.imshow(processed_image, cmap=plt.get_cmap('gray'))\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As you can see, this kernel detects vertical edges (the black stripe corresponds to a highly positive result, while the white stripe corresponds to a highly negative result. However, to display the image, all the pixels are normalized between 0=black and 1=white)."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! 2.2.2 Kernel structure\n",
"\n",
"If the kernel were transposed (i.e., the columns become rows and the rows become columns), what would the kernel detect? What would be produced by running this kernel on the vertical edge image above?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_7cc3340b.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Kernel_structure_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 3: Kernels, Pooling and Subsampling\n",
"\n",
"*Time estimate: ~50mins*"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"To visualize the various components of a CNN, we will build a simple CNN step by step. Recall that the MNIST dataset consists of binarized images of handwritten digits. This time, we will use the EMNIST letters dataset, which consists of binarized images of handwritten characters $(A, ..., Z)$.\n",
"\n",
"We will simplify the problem further by only keeping the images that correspond to $X$ (labeled as `24` in the dataset) and $O$ (labeled as `15` in the dataset). Then, we will train a CNN to classify an image either an $X$ or an $O$."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Download EMNIST dataset\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Download EMNIST dataset\n",
"\n",
"# webpage: https://www.itl.nist.gov/iaui/vip/cs_links/EMNIST/gzip.zip\n",
"fname = 'EMNIST.zip'\n",
"folder = 'EMNIST'\n",
"url = \"https://osf.io/xwfaj/download\"\n",
"download_data(fname, folder, url, tar=False)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Dataset/DataLoader Functions *(Run me!)*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Dataset/DataLoader Functions *(Run me!)*\n",
"\n",
"def get_Xvs0_dataset(normalize=False, download=False):\n",
" \"\"\"\n",
" Load Dataset\n",
"\n",
" Args:\n",
" normalize: boolean\n",
" If true, normalise dataloader\n",
" download: boolean\n",
" If true, download dataset\n",
"\n",
" Returns:\n",
" emnist_train: torch.loader\n",
" Training Data\n",
" emnist_test: torch.loader\n",
" Test Data\n",
" \"\"\"\n",
" if normalize:\n",
" transform = transforms.Compose([\n",
" transforms.ToTensor(),\n",
" transforms.Normalize((0.1307,), (0.3081,))\n",
" ])\n",
" else:\n",
" transform = transforms.Compose([\n",
" transforms.ToTensor(),\n",
" ])\n",
"\n",
" emnist_train = datasets.EMNIST(root='.',\n",
" split='letters',\n",
" download=download,\n",
" train=True,\n",
" transform=transform)\n",
" emnist_test = datasets.EMNIST(root='.',\n",
" split='letters',\n",
" download=download,\n",
" train=False,\n",
" transform=transform)\n",
"\n",
" # Only want O (15) and X (24) labels\n",
" train_idx = (emnist_train.targets == 15) | (emnist_train.targets == 24)\n",
" emnist_train.targets = emnist_train.targets[train_idx]\n",
" emnist_train.data = emnist_train.data[train_idx]\n",
"\n",
" # Convert Xs predictions to 1, Os predictions to 0\n",
" emnist_train.targets = (emnist_train.targets == 24).type(torch.int64)\n",
"\n",
" test_idx = (emnist_test.targets == 15) | (emnist_test.targets == 24)\n",
" emnist_test.targets = emnist_test.targets[test_idx]\n",
" emnist_test.data = emnist_test.data[test_idx]\n",
"\n",
" # Convert Xs predictions to 1, Os predictions to 0\n",
" emnist_test.targets = (emnist_test.targets == 24).type(torch.int64)\n",
"\n",
" return emnist_train, emnist_test\n",
"\n",
"\n",
"def get_data_loaders(train_dataset, test_dataset,\n",
" batch_size=32, seed=0):\n",
" \"\"\"\n",
" Helper function to fetch dataloaders\n",
"\n",
" Args:\n",
" train_dataset: torch.tensor\n",
" Training data\n",
" test_dataset: torch.tensor\n",
" Test data\n",
" batch_size: int\n",
" Batch Size\n",
" seed: int\n",
" Set seed for reproducibility\n",
"\n",
" Returns:\n",
" emnist_train: torch.loader\n",
" Training Data\n",
" emnist_test: torch.loader\n",
" Test Data\n",
" \"\"\"\n",
" g_seed = torch.Generator()\n",
" g_seed.manual_seed(seed)\n",
"\n",
" train_loader = DataLoader(train_dataset,\n",
" batch_size=batch_size,\n",
" shuffle=True,\n",
" num_workers=2,\n",
" worker_init_fn=seed_worker,\n",
" generator=g_seed)\n",
" test_loader = DataLoader(test_dataset,\n",
" batch_size=batch_size,\n",
" shuffle=True,\n",
" num_workers=2,\n",
" worker_init_fn=seed_worker,\n",
" generator=g_seed)\n",
"\n",
" return train_loader, test_loader"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"emnist_train, emnist_test = get_Xvs0_dataset(normalize=False, download=False)\n",
"train_loader, test_loader = get_data_loaders(emnist_train, emnist_test,\n",
" seed=SEED)\n",
"\n",
"# Index of an image in the dataset that corresponds to an X and O\n",
"x_img_idx = 4\n",
"o_img_idx = 15"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Let's view a couple samples from the dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"fig, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4, figsize=(12, 6))\n",
"ax1.imshow(emnist_train[0][0].reshape(28, 28), cmap='gray')\n",
"ax2.imshow(emnist_train[10][0].reshape(28, 28), cmap='gray')\n",
"ax3.imshow(emnist_train[4][0].reshape(28, 28), cmap='gray')\n",
"ax4.imshow(emnist_train[6][0].reshape(28, 28), cmap='gray')\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Interactive Demo 3: Visualization of Convolution with Multiple Filters\n",
"\n",
"Change the number of input channels (e.g., the color channels of an image or the output channels of a previous layer) and the output channels (number of different filters to apply)."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Important:** Change the bool variable `run_demo` to `True` by ticking the box, in order to experiment with the demo. Due to video rendering on jupyter-book, we had to remove it from the automatic execution."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" *Run this cell to enable the widget!*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown *Run this cell to enable the widget!*\n",
"\n",
"from IPython.display import HTML\n",
"\n",
"id_html = 3\n",
"url = f'https://raw.githubusercontent.com/NeuromatchAcademy/course-content-dl/main/tutorials/W2D2_ConvnetsAndDlThinking/static/interactive_demo{id_html}.html'\n",
"run_demo = False # @param {type:\"boolean\"}\n",
"if run_demo:\n",
" display(HTML(url))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Visualization_of_Convolution_with_Multiple_Filters_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.1: Multiple Filters\n",
"\n",
"The following network sets up 3 filters and runs them on an image of the dataset from the $X$ class. Note that we are using \"thicker\" filters than those presented in the videos. Here, the filters are $5 \\times 5$, whereas in the videos $3 \\times 3$."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"class Net2(nn.Module):\n",
" \"\"\"\n",
" Neural Network instance\n",
" \"\"\"\n",
"\n",
" def __init__(self, padding=0):\n",
" \"\"\"\n",
" Initialize parameters of Net2\n",
"\n",
" Args:\n",
" padding: int or tuple, optional\n",
" Zero-padding added to both sides of the input. Default: 0\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" super(Net2, self).__init__()\n",
" self.conv1 = nn.Conv2d(in_channels=1, out_channels=3, kernel_size=5,\n",
" padding=padding)\n",
"\n",
" # First kernel - leading diagonal\n",
" kernel_1 = torch.Tensor([[[1., 1., -1., -1., -1.],\n",
" [1., 1., 1., -1., -1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [-1., -1., 1., 1., 1.],\n",
" [-1., -1., -1., 1., 1.]]])\n",
"\n",
" # Second kernel - other diagonal\n",
" kernel_2 = torch.Tensor([[[-1., -1., -1., 1., 1.],\n",
" [-1., -1., 1., 1., 1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [1., 1., 1., -1., -1.],\n",
" [1., 1., -1., -1., -1.]]])\n",
"\n",
" # tThird kernel - checkerboard pattern\n",
" kernel_3 = torch.Tensor([[[1., 1., -1., 1., 1.],\n",
" [1., 1., 1., 1., 1.],\n",
" [-1., 1., 1., 1., -1.],\n",
" [1., 1., 1., 1., 1.],\n",
" [1., 1., -1., 1., 1.]]])\n",
"\n",
"\n",
" # Stack all kernels in one tensor with (3, 1, 5, 5) dimensions\n",
" multiple_kernels = torch.stack([kernel_1, kernel_2, kernel_3], dim=0)\n",
"\n",
" self.conv1.weight = torch.nn.Parameter(multiple_kernels)\n",
"\n",
" # Negative bias\n",
" self.conv1.bias = torch.nn.Parameter(torch.Tensor([-4, -4, -12]))\n",
"\n",
" def forward(self, x):\n",
" \"\"\"\n",
" Forward Pass of Net2\n",
"\n",
" Args:\n",
" x: torch.tensor\n",
" Input features\n",
"\n",
" Returns:\n",
" x: torch.tensor\n",
" Convolution output\n",
" \"\"\"\n",
" x = self.conv1(x)\n",
" return x"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Note:** We add a negative bias to give a threshold to select the high output value, which corresponds to the features we want to detect (e.g., 45 degree oriented bar).\n",
"\n",
"Now, let's visualize the filters using the code given below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"net2 = Net2().to(DEVICE)\n",
"fig, (ax11, ax12, ax13) = plt.subplots(1, 3)\n",
"# Show the filters\n",
"ax11.set_title(\"filter 1\")\n",
"ax11.imshow(net2.conv1.weight[0, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax12.set_title(\"filter 2\")\n",
"ax12.imshow(net2.conv1.weight[1, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax13.set_title(\"filter 3\")\n",
"ax13.imshow(net2.conv1.weight[2, 0].detach().cpu().numpy(), cmap=\"gray\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! 3.1: Do you see how these filters would help recognize an `X`?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_800ed014.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Multiple_Filters_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We apply the filters to the images."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"net2 = Net2().to(DEVICE)\n",
"x_img = emnist_train[x_img_idx][0].unsqueeze(dim=0).to(DEVICE)\n",
"output_x = net2(x_img)\n",
"output_x = output_x.squeeze(dim=0).detach().cpu().numpy()\n",
"\n",
"o_img = emnist_train[o_img_idx][0].unsqueeze(dim=0).to(DEVICE)\n",
"output_o = net2(o_img)\n",
"output_o = output_o.squeeze(dim=0).detach().cpu().numpy()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Let us view the image of $X$ and $O$ and what the output of the filters applied to them looks like. Pay special attention to the areas with very high vs. very low output patterns."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"fig, ((ax11, ax12, ax13, ax14),\n",
" (ax21, ax22, ax23, ax24),\n",
" (ax31, ax32, ax33, ax34)) = plt.subplots(3, 4)\n",
"\n",
"# Show the filters\n",
"ax11.axis(\"off\")\n",
"ax12.set_title(\"filter 1\")\n",
"ax12.imshow(net2.conv1.weight[0, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax13.set_title(\"filter 2\")\n",
"ax13.imshow(net2.conv1.weight[1, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"ax14.set_title(\"filter 3\")\n",
"ax14.imshow(net2.conv1.weight[2, 0].detach().cpu().numpy(), cmap=\"gray\")\n",
"\n",
"vmin, vmax = -6, 10\n",
"# Show x and the filters applied to x\n",
"ax21.set_title(\"image x\")\n",
"ax21.imshow(emnist_train[x_img_idx][0].reshape(28, 28), cmap='gray')\n",
"ax22.set_title(\"output filter 1\")\n",
"ax22.imshow(output_x[0], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax23.set_title(\"output filter 2\")\n",
"ax23.imshow(output_x[1], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax24.set_title(\"output filter 3\")\n",
"ax24.imshow(output_x[2], cmap='gray', vmin=vmin, vmax=vmax)\n",
"\n",
"# Show o and the filters applied to o\n",
"ax31.set_title(\"image o\")\n",
"ax31.imshow(emnist_train[o_img_idx][0].reshape(28, 28), cmap='gray')\n",
"ax32.set_title(\"output filter 1\")\n",
"ax32.imshow(output_o[0], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax33.set_title(\"output filter 2\")\n",
"ax33.imshow(output_o[1], cmap='gray', vmin=vmin, vmax=vmax)\n",
"ax34.set_title(\"output filter 3\")\n",
"ax34.imshow(output_o[2], cmap='gray', vmin=vmin, vmax=vmax)\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.2: ReLU after convolutions\n",
"\n",
"Up until now we've talked about the convolution operation, which is linear. But the real strength of neural networks comes from the incorporation of non-linear functions. Furthermore, in the real world, we often have learning problems where the relationship between the input and output is non-linear and complex.\n",
"\n",
"The ReLU (Rectified Linear Unit) introduces non-linearity into our model, allowing us to learn a more complex function that can better predict the class of an image.\n",
"\n",
"The ReLU function is shown below.\n",
"\n",
"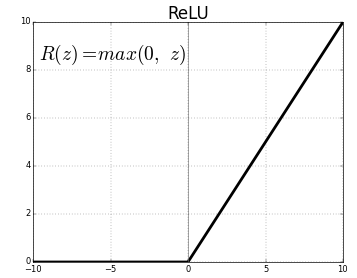 \n",
"
\n",
"  \n",
"
\n",
" 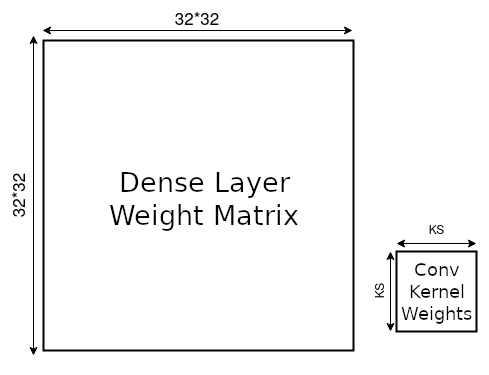 \n",
"
\n",
"  \n",
"\n",
"\n",
"
\n",
"\n",
"\n",
" \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Code_the_training_loop_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Think! Bonus 1: Overfitting\n",
"Do you think this network is overfitting?\n",
"If yes, what can you do to combat this?\n",
"\n",
"**Hint**: Overfitting occurs when the training accuracy greatly exceeds the validation accuracy\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_3ef24bd7.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Overfitting_Bonus_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus 2: Overfitting - symptoms and cures\n",
"\n",
"*Time estimate: ~30mins*"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"So you spent some time last week learning about regularization techniques. Below is a copy of the CNN model we used previously. Now we want you to add some dropout regularization, and check if that helps reduce overfitting. If you're up for a challenge, you can try methods other than dropout as well."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus 2.1: Regularization"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise Bonus 2.1: Adding Regularization\n",
"\n",
"Add various regularization methods, feel free to add any and play around!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"class FMNIST_Net2(nn.Module):\n",
" \"\"\"\n",
" Neural Network instance\n",
" \"\"\"\n",
"\n",
" def __init__(self, num_classes):\n",
" \"\"\"\n",
" Initialise parameters of FMNIST_Net2\n",
"\n",
" Args:\n",
" num_classes: int\n",
" Number of classes\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" super(FMNIST_Net2, self).__init__()\n",
" ####################################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Add regularization layers\")\n",
" ####################################################################\n",
" self.conv1 = nn.Conv2d(1, 32, 3, 1)\n",
" self.conv2 = nn.Conv2d(32, 64, 3, 1)\n",
" self.dropout1 = ...\n",
" self.dropout2 = ...\n",
" self.fc1 = nn.Linear(9216, 128)\n",
" self.fc2 = nn.Linear(128, num_classes)\n",
"\n",
" def forward(self, x):\n",
" \"\"\"\n",
" Forward pass of FMNIST_Net2\n",
"\n",
" Args:\n",
" x: torch.tensor\n",
" Input features\n",
"\n",
" Returns:\n",
" x: torch.tensor\n",
" Output after passing through FMNIST_Net2\n",
" \"\"\"\n",
" ####################################################################\n",
" # Now add the layers in your forward pass in appropriate order\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Add regularization in the forward pass\")\n",
" ####################################################################\n",
" x = self.conv1(x)\n",
" x = F.relu(x)\n",
" x = self.conv2(x)\n",
" x = F.relu(x)\n",
" x = F.max_pool2d(x, 2)\n",
" x = ...\n",
" x = torch.flatten(x, 1)\n",
" x = self.fc1(x)\n",
" x = F.relu(x)\n",
" x = ...\n",
" x = self.fc2(x)\n",
"\n",
" return x\n",
"\n",
"\n",
"set_seed(SEED)\n",
"## Uncomment below to check your code\n",
"# net2 = FMNIST_Net2(num_classes=2).to(DEVICE)\n",
"# train_loss, train_acc, validation_loss, validation_acc = train(net2, DEVICE, train_loader, validation_loader, 20)\n",
"# print(f'Test accuracy is: {test(net2, DEVICE, test_loader)}')\n",
"# plot_loss_accuracy(train_loss, train_acc, validation_loss, validation_acc)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_0adbc972.py)\n",
"\n",
"*Example output:*\n",
"\n",
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Code_the_training_loop_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Think! Bonus 1: Overfitting\n",
"Do you think this network is overfitting?\n",
"If yes, what can you do to combat this?\n",
"\n",
"**Hint**: Overfitting occurs when the training accuracy greatly exceeds the validation accuracy\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_3ef24bd7.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Overfitting_Bonus_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus 2: Overfitting - symptoms and cures\n",
"\n",
"*Time estimate: ~30mins*"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"So you spent some time last week learning about regularization techniques. Below is a copy of the CNN model we used previously. Now we want you to add some dropout regularization, and check if that helps reduce overfitting. If you're up for a challenge, you can try methods other than dropout as well."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus 2.1: Regularization"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise Bonus 2.1: Adding Regularization\n",
"\n",
"Add various regularization methods, feel free to add any and play around!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"class FMNIST_Net2(nn.Module):\n",
" \"\"\"\n",
" Neural Network instance\n",
" \"\"\"\n",
"\n",
" def __init__(self, num_classes):\n",
" \"\"\"\n",
" Initialise parameters of FMNIST_Net2\n",
"\n",
" Args:\n",
" num_classes: int\n",
" Number of classes\n",
"\n",
" Returns:\n",
" Nothing\n",
" \"\"\"\n",
" super(FMNIST_Net2, self).__init__()\n",
" ####################################################################\n",
" # Fill in missing code below (...),\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Add regularization layers\")\n",
" ####################################################################\n",
" self.conv1 = nn.Conv2d(1, 32, 3, 1)\n",
" self.conv2 = nn.Conv2d(32, 64, 3, 1)\n",
" self.dropout1 = ...\n",
" self.dropout2 = ...\n",
" self.fc1 = nn.Linear(9216, 128)\n",
" self.fc2 = nn.Linear(128, num_classes)\n",
"\n",
" def forward(self, x):\n",
" \"\"\"\n",
" Forward pass of FMNIST_Net2\n",
"\n",
" Args:\n",
" x: torch.tensor\n",
" Input features\n",
"\n",
" Returns:\n",
" x: torch.tensor\n",
" Output after passing through FMNIST_Net2\n",
" \"\"\"\n",
" ####################################################################\n",
" # Now add the layers in your forward pass in appropriate order\n",
" # then remove or comment the line below to test your function\n",
" raise NotImplementedError(\"Add regularization in the forward pass\")\n",
" ####################################################################\n",
" x = self.conv1(x)\n",
" x = F.relu(x)\n",
" x = self.conv2(x)\n",
" x = F.relu(x)\n",
" x = F.max_pool2d(x, 2)\n",
" x = ...\n",
" x = torch.flatten(x, 1)\n",
" x = self.fc1(x)\n",
" x = F.relu(x)\n",
" x = ...\n",
" x = self.fc2(x)\n",
"\n",
" return x\n",
"\n",
"\n",
"set_seed(SEED)\n",
"## Uncomment below to check your code\n",
"# net2 = FMNIST_Net2(num_classes=2).to(DEVICE)\n",
"# train_loss, train_acc, validation_loss, validation_acc = train(net2, DEVICE, train_loader, validation_loader, 20)\n",
"# print(f'Test accuracy is: {test(net2, DEVICE, test_loader)}')\n",
"# plot_loss_accuracy(train_loss, train_acc, validation_loss, validation_acc)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_0adbc972.py)\n",
"\n",
"*Example output:*\n",
"\n",
" \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Adding_Regularization_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! Bonus 2.1: Regularization\n",
"\n",
"1. Is the training accuracy slightly reduced from before adding regularization? What accuracy were you able to reduce it to?\n",
"\n",
"2. Why does the validation accuracy start higher than training accuracy?\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_6e9ea2ef.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Adding_Regularization_Bonus_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo Bonus 2.1: Dropout exploration\n",
"\n",
"If you want to try out more dropout parameter combinations, but do not have the time to run them, we have here precalculated some combinations you can use the sliders to explore them."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" *Run this cell to enable the widget*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown *Run this cell to enable the widget*\n",
"\n",
"import io, base64\n",
"from ipywidgets import widgets, interactive_output\n",
"\n",
"data = [[0, 0, [0.3495898238046372, 0.2901147632522786, 0.2504794800931469, 0.23571575765914105, 0.21297093365896255, 0.19087818914905508, 0.186408187797729, 0.19487689035211472, 0.16774938120803934, 0.1548648244958926, 0.1390149021382503, 0.10919439224922593, 0.10054351237820501, 0.09900783193594914, 0.08370604479507088, 0.07831853718318521, 0.06859792241866285, 0.06152600247383197, 0.046342475851873885, 0.055123823092992796], [0.83475, 0.8659166666666667, 0.8874166666666666, 0.8913333333333333, 0.8998333333333334, 0.9140833333333334, 0.9178333333333333, 0.9138333333333334, 0.9251666666666667, 0.92975, 0.939, 0.9525833333333333, 0.9548333333333333, 0.9585833333333333, 0.9655833333333333, 0.9661666666666666, 0.9704166666666667, 0.9743333333333334, 0.9808333333333333, 0.9775], [0.334623601436615, 0.2977438402175903, 0.2655304968357086, 0.25506321132183074, 0.2588835284113884, 0.2336345863342285, 0.3029863876104355, 0.240766831189394, 0.2719801160693169, 0.25231350839138034, 0.2500132185220718, 0.26699506521224975, 0.2934862145781517, 0.361227530837059, 0.33196919202804565, 0.36985905408859254, 0.4042587959766388, 0.3716402840614319, 0.3707024946808815, 0.4652537405490875], [0.866875, 0.851875, 0.8775, 0.889375, 0.881875, 0.900625, 0.85, 0.898125, 0.885625, 0.876875, 0.899375, 0.90625, 0.89875, 0.87, 0.898125, 0.884375, 0.874375, 0.89375, 0.903125, 0.890625]], [0, 0.25, [0.35404509995528993, 0.30616586227366266, 0.2872369573946963, 0.27564131199045383, 0.25969504263806853, 0.24728168408445855, 0.23505379509260046, 0.21552803914280647, 0.209761732277718, 0.19977611067526518, 0.19632092922767427, 0.18672360206379535, 0.16564940239124476, 0.1654047035671612, 0.1684555298985636, 0.1627526102349796, 0.13878319327263755, 0.12881529055773577, 0.12628930977525862, 0.11346105090837846], [0.8324166666666667, 0.8604166666666667, 0.8680833333333333, 0.8728333333333333, 0.8829166666666667, 0.88625, 0.89425, 0.90125, 0.9015833333333333, 0.90925, 0.9114166666666667, 0.917, 0.9268333333333333, 0.92475, 0.921, 0.9255833333333333, 0.9385, 0.9428333333333333, 0.9424166666666667, 0.9484166666666667], [0.3533937376737595, 0.29569859683513644, 0.27531551957130435, 0.2576177391409874, 0.26947550356388095, 0.25361743807792664, 0.2527468180656433, 0.24179009914398195, 0.28664454460144045, 0.23347773611545564, 0.24672816634178163, 0.27822364538908007, 0.2380720081925392, 0.24426509588956832, 0.2443918392062187, 0.24207917481660843, 0.2519641682505608, 0.3075403380393982, 0.2798181238770485, 0.26709021866321564], [0.826875, 0.87, 0.870625, 0.8875, 0.883125, 0.88625, 0.891875, 0.891875, 0.890625, 0.903125, 0.89375, 0.885625, 0.903125, 0.888125, 0.899375, 0.898125, 0.905, 0.905625, 0.898125, 0.901875]], [0, 0.5, [0.39775496332886373, 0.33771887778284704, 0.321900939132939, 0.3079229625774191, 0.304149763301966, 0.28249239723416086, 0.2861261191044716, 0.27356165798103554, 0.2654648520686525, 0.2697350280557541, 0.25354846321204877, 0.24612889034633942, 0.23482802549892284, 0.2389904112416379, 0.23742155821875055, 0.232423192127905, 0.22337309338469455, 0.2141852991932884, 0.20677659985549907, 0.19355326712607068], [0.8155, 0.83625, 0.8481666666666666, 0.8530833333333333, 0.8571666666666666, 0.86775, 0.8623333333333333, 0.8711666666666666, 0.8748333333333334, 0.8685833333333334, 0.8785, 0.8804166666666666, 0.8835833333333334, 0.8840833333333333, 0.88875, 0.8919166666666667, 0.8946666666666667, 0.8960833333333333, 0.906, 0.9063333333333333], [0.3430288594961166, 0.4062050700187683, 0.29745822548866274, 0.27728439271450045, 0.28092808067798614, 0.2577864158153534, 0.2651400637626648, 0.25632822573184966, 0.3082498562335968, 0.2812121778726578, 0.26345942318439486, 0.2577408078312874, 0.25757989794015884, 0.26434457510709763, 0.24917411386966706, 0.27261342853307724, 0.2445397639274597, 0.26001051396131514, 0.24147838801145555, 0.2471102523803711], [0.82875, 0.795625, 0.87, 0.87375, 0.865625, 0.8825, 0.8825, 0.87625, 0.848125, 0.87875, 0.8675, 0.889375, 0.8925, 0.866875, 0.87375, 0.87125, 0.895625, 0.90375, 0.90125, 0.88625]], [0, 0.75, [0.4454924576777093, 0.43416607585993217, 0.42200265769311723, 0.40520024616667566, 0.41137005166804536, 0.404100904280835, 0.40118067664034823, 0.40139733080534223, 0.3797615355158106, 0.3596332479030528, 0.3600061919460905, 0.3554147962242999, 0.34480382890460337, 0.3329520877054397, 0.33164913056695716, 0.31860941466181836, 0.30702565340919696, 0.30605297186907304, 0.2953788426486736, 0.2877389984403519], [0.7788333333333334, 0.7825, 0.7854166666666667, 0.7916666666666666, 0.7885, 0.7833333333333333, 0.7923333333333333, 0.79525, 0.805, 0.81475, 0.8161666666666667, 0.8188333333333333, 0.817, 0.8266666666666667, 0.82225, 0.8360833333333333, 0.8456666666666667, 0.8430833333333333, 0.8491666666666666, 0.8486666666666667], [0.3507828885316849, 0.3337512403726578, 0.34320746660232543, 0.3476085543632507, 0.3326113569736481, 0.33033264458179473, 0.32014619171619413, 0.3182142299413681, 0.30076164126396177, 0.3263852882385254, 0.27597591280937195, 0.29062016785144806, 0.2765174686908722, 0.269492534995079, 0.2679423809051514, 0.2691828978061676, 0.2726386785507202, 0.2541181230545044, 0.2580208206176758, 0.26315389811992645], [0.839375, 0.843125, 0.823125, 0.821875, 0.81875, 0.819375, 0.8225, 0.826875, 0.835625, 0.865, 0.868125, 0.855625, 0.868125, 0.884375, 0.883125, 0.875, 0.87375, 0.883125, 0.8975, 0.885]], [0.25, 0, [0.34561181647029326, 0.2834314257699124, 0.2583787844298368, 0.23892096465730922, 0.23207981773513428, 0.20245029634617745, 0.183908417583146, 0.17489413774393975, 0.17696723581707857, 0.15615438255778652, 0.14469048382833283, 0.12424647461305907, 0.11314761043189371, 0.11249036608422373, 0.10725672634199579, 0.09081190969160896, 0.0942245383271353, 0.08525650047677312, 0.06622548752583246, 0.06039895973307021], [0.8356666666666667, 0.8675833333333334, 0.88175, 0.8933333333333333, 0.8975833333333333, 0.91175, 0.91825, 0.9249166666666667, 0.9238333333333333, 0.9305, 0.938, 0.9465833333333333, 0.9525833333333333, 0.9539166666666666, 0.9555, 0.9615, 0.9606666666666667, 0.96275, 0.9725, 0.9764166666666667], [0.31630186855792997, 0.2702121251821518, 0.2915778249502182, 0.26050266206264494, 0.27837209939956664, 0.24276352763175965, 0.3567117482423782, 0.2752074319124222, 0.2423130339384079, 0.2565067422389984, 0.28710135877132414, 0.266545415520668, 0.31818037331104276, 0.28757534325122835, 0.2777567034959793, 0.2998969575762749, 0.3292293107509613, 0.30775387287139894, 0.32681577146053314, 0.44882203072309496], [0.85375, 0.879375, 0.875625, 0.89, 0.86125, 0.884375, 0.851875, 0.8875, 0.89625, 0.875625, 0.8675, 0.895, 0.888125, 0.89125, 0.889375, 0.880625, 0.87875, 0.8875, 0.894375, 0.891875]], [0.25, 0.25, [0.35970850011452715, 0.31336131549261986, 0.2881505932421126, 0.2732012960267194, 0.26232245425753137, 0.2490472443639598, 0.24866499093935845, 0.22930880945096624, 0.21745950407645803, 0.20700296882460725, 0.197304340356842, 0.20665066804182022, 0.19864868348900308, 0.184807124210799, 0.1684703354703936, 0.17377675851767369, 0.16638460063791655, 0.15944768343754906, 0.14876513817208878, 0.1388207479835825], [0.83375, 0.85175, 0.86725, 0.8719166666666667, 0.8761666666666666, 0.8865833333333333, 0.88275, 0.8956666666666667, 0.8995833333333333, 0.9034166666666666, 0.90825, 0.9043333333333333, 0.9093333333333333, 0.9145, 0.9196666666666666, 0.9196666666666666, 0.9216666666666666, 0.9273333333333333, 0.9299166666666666, 0.93675], [0.3166788029670715, 0.28422485530376435, 0.38055971562862395, 0.2586472672224045, 0.2588653892278671, 0.27983254253864287, 0.25693483114242555, 0.26412731170654297, 0.2733065390586853, 0.24399636536836625, 0.24481021404266357, 0.2689305514097214, 0.2527604129910469, 0.24829535871744157, 0.2654112687706947, 0.23074268400669098, 0.24625462979078294, 0.26423920392990113, 0.25540480852127073, 0.25536185175180437], [0.856875, 0.86625, 0.815, 0.8825, 0.88125, 0.875625, 0.89, 0.8775, 0.870625, 0.895, 0.8975, 0.87375, 0.88625, 0.89125, 0.903125, 0.9, 0.893125, 0.89, 0.8925, 0.899375]], [0.25, 0.5, [0.3975753842040579, 0.34884724409339274, 0.3296900932142075, 0.3150389680361494, 0.31285368667003954, 0.30415422033439293, 0.29553352716438314, 0.289314468094009, 0.2806722329969102, 0.2724469883486311, 0.26634286379719035, 0.2645016222241077, 0.2619251853766594, 0.2551752221473354, 0.26411766035759704, 0.24515971153023394, 0.2390686312412962, 0.23573122312255362, 0.221005061562074, 0.22358600648635246], [0.8106666666666666, 0.8286666666666667, 0.844, 0.8513333333333334, 0.84975, 0.8570833333333333, 0.8624166666666667, 0.8626666666666667, 0.866, 0.8706666666666667, 0.8738333333333334, 0.8748333333333334, 0.8778333333333334, 0.8798333333333334, 0.87375, 0.8865, 0.8898333333333334, 0.8885833333333333, 0.8991666666666667, 0.8968333333333334], [0.3597823417186737, 0.31115993797779085, 0.29929635107517244, 0.2986589139699936, 0.2938830828666687, 0.28118040919303894, 0.2711684626340866, 0.2844697123765945, 0.26613601863384245, 0.2783134698867798, 0.2540236383676529, 0.25821100890636445, 0.2618845862150192, 0.2554920208454132, 0.26543013513088226, 0.24074569433927537, 0.26475649774074556, 0.25578504264354707, 0.2648500043153763, 0.25700133621692656], [0.825, 0.8375, 0.85875, 0.855625, 0.861875, 0.868125, 0.875, 0.85375, 0.886875, 0.86375, 0.88375, 0.885625, 0.875625, 0.87375, 0.8875, 0.895, 0.874375, 0.89125, 0.88625, 0.895625]], [0.25, 0.75, [0.4584837538447786, 0.4506375778545725, 0.4378386567089152, 0.4066803843734112, 0.3897064097542712, 0.3855383962868376, 0.39160584618753574, 0.3731403942120836, 0.37915910170116324, 0.36966170814443144, 0.35735995298687445, 0.35630573094525236, 0.346426092167484, 0.34040802899510303, 0.32829743726773464, 0.3284692421872565, 0.3186114077713895, 0.32295761503120685, 0.3201326223764014, 0.30581602454185486], [0.7803333333333333, 0.7709166666666667, 0.7723333333333333, 0.7850833333333334, 0.7885, 0.7903333333333333, 0.7986666666666666, 0.805, 0.8011666666666667, 0.8068333333333333, 0.8095833333333333, 0.8226666666666667, 0.8285, 0.83125, 0.8369166666666666, 0.8395, 0.8441666666666666, 0.8393333333333334, 0.8490833333333333, 0.8546666666666667], [0.43526833415031435, 0.3598956459760666, 0.3492005372047424, 0.33501910269260404, 0.31689528703689573, 0.3113307124376297, 0.32388085544109346, 0.3084335786104202, 0.3013568025827408, 0.28992725372314454, 0.28726822674274444, 0.26945948660373686, 0.276592333316803, 0.27462401330471037, 0.27574350595474245, 0.2710308712720871, 0.2702724140882492, 0.27323003828525544, 0.25551479041576386, 0.26488787233829497], [0.808125, 0.81625, 0.805, 0.8325, 0.846875, 0.835625, 0.850625, 0.838125, 0.836875, 0.861875, 0.85375, 0.866875, 0.858125, 0.8825, 0.879375, 0.874375, 0.874375, 0.886875, 0.883125, 0.86875]], [0.5, 0, [0.3579516930783049, 0.29596046564426826, 0.2779693031247626, 0.2563994538356015, 0.24771526356802342, 0.2324555875693864, 0.2139121579362991, 0.20474095547452886, 0.19138856208387842, 0.18883306279461434, 0.1763652620757831, 0.1698919345248253, 0.16033914366221808, 0.1557997044651432, 0.1432509447467771, 0.13817814606776896, 0.12609625801919622, 0.11830132696381275, 0.11182412960903441, 0.112559904720872], [0.8314166666666667, 0.8611666666666666, 0.8736666666666667, 0.8800833333333333, 0.885, 0.8944166666666666, 0.9036666666666666, 0.9090833333333334, 0.9193333333333333, 0.9161666666666667, 0.92225, 0.9255, 0.93075, 0.93225, 0.939, 0.9414166666666667, 0.94375, 0.9485833333333333, 0.9535833333333333, 0.9524166666666667], [0.30677567660808563, 0.32954772651195524, 0.25747098088264464, 0.2736126834154129, 0.2561805549263954, 0.23671718776226044, 0.24553639352321624, 0.2338863667845726, 0.24586652517318724, 0.23423030972480774, 0.26579618513584136, 0.2781539523601532, 0.27084136098623274, 0.23948652744293214, 0.26023868829011915, 0.2419952344894409, 0.2511997854709625, 0.23935708701610564, 0.2701922015845776, 0.27307246536016466], [0.870625, 0.855625, 0.886875, 0.875625, 0.878125, 0.8925, 0.885, 0.890625, 0.876875, 0.896875, 0.881875, 0.8875, 0.89, 0.898125, 0.896875, 0.89, 0.89875, 0.904375, 0.906875, 0.894375]], [0.5, 0.25, [0.3712943946903056, 0.3198322071594761, 0.29978102302931725, 0.295274139798068, 0.2861913934032968, 0.27165328782606635, 0.25972246442069397, 0.2543164194819141, 0.24795781916126292, 0.24630710007028378, 0.23296909834793272, 0.23382153587931015, 0.2239028559799524, 0.21443849290780564, 0.2149274461367663, 0.20642021417300752, 0.19801520536396097, 0.1978839404009124, 0.19118623847657062, 0.18144798041024107], [0.8235833333333333, 0.8538333333333333, 0.8604166666666667, 0.86075, 0.8664166666666666, 0.8754166666666666, 0.8799166666666667, 0.8815833333333334, 0.88725, 0.8848333333333334, 0.8936666666666667, 0.8935, 0.895, 0.8995, 0.89625, 0.9068333333333334, 0.9098333333333334, 0.9120833333333334, 0.91375, 0.9175833333333333], [0.3184810388088226, 0.2948088157176971, 0.29438531696796416, 0.27669853866100313, 0.2634278678894043, 0.25847582578659056, 0.2500907778739929, 0.2538330048322678, 0.25127841770648957, 0.2519759064912796, 0.2455715072154999, 0.2437664610147476, 0.259639236330986, 0.24515749186277389, 0.2553828465938568, 0.2324645048379898, 0.24492083072662355, 0.24482838332653045, 0.23327024638652802, 0.2520161652565002], [0.855, 0.865, 0.8525, 0.856875, 0.876875, 0.88125, 0.8825, 0.8875, 0.8925, 0.8925, 0.88875, 0.889375, 0.87375, 0.895, 0.889375, 0.90625, 0.883125, 0.895, 0.899375, 0.901875]], [0.5, 0.5, [0.40442772225496615, 0.36662670541951, 0.355034276367502, 0.3396551510755052, 0.3378269396563794, 0.32084332002287214, 0.31314464951766297, 0.2982726935693558, 0.2885229691387491, 0.2888992782285873, 0.2893476904706752, 0.281817957996688, 0.2771622718490185, 0.2693793097550565, 0.2617615883416952, 0.2657115764995205, 0.25631817549150043, 0.24793559907281654, 0.2538738044652533, 0.23912971732305718], [0.8093333333333333, 0.82825, 0.8341666666666666, 0.84525, 0.84525, 0.8515, 0.8583333333333333, 0.8626666666666667, 0.8688333333333333, 0.8685, 0.8689166666666667, 0.8693333333333333, 0.8711666666666666, 0.8766666666666667, 0.88275, 0.88175, 0.8839166666666667, 0.8866666666666667, 0.8839166666666667, 0.8929166666666667], [0.38392188608646394, 0.3653419762849808, 0.3050421380996704, 0.30614266455173494, 0.2937217426300049, 0.30008585572242735, 0.2794034606218338, 0.27541795969009397, 0.31378355383872986, 0.2670704126358032, 0.26745485186576845, 0.2471194839477539, 0.26509816259145735, 0.25458798944950106, 0.2481587851047516, 0.25591064751148224, 0.2596563971042633, 0.2569611769914627, 0.2435744071006775, 0.2507249677181244], [0.820625, 0.846875, 0.856875, 0.868125, 0.860625, 0.87125, 0.86625, 0.87375, 0.865625, 0.87875, 0.878125, 0.889375, 0.87875, 0.886875, 0.89125, 0.89, 0.87375, 0.884375, 0.88875, 0.89375]], [0.5, 0.75, [0.46106574311852455, 0.4519433615372536, 0.4446939624687459, 0.4284856241751224, 0.4527993325857406, 0.4220876024758562, 0.40969764266876463, 0.39233948219012704, 0.42498463344700793, 0.3869199570506177, 0.38021832910623954, 0.3855376149270129, 0.3721433773319772, 0.3662295250340979, 0.3629763710530514, 0.358500304691335, 0.3490118366131123, 0.34879197790584665, 0.33399240054348683, 0.3347948451149971], [0.7866666666666666, 0.7865, 0.784, 0.79375, 0.7755833333333333, 0.79125, 0.7973333333333333, 0.8085833333333333, 0.7913333333333333, 0.8125833333333333, 0.81675, 0.812, 0.8173333333333334, 0.8235833333333333, 0.831, 0.8306666666666667, 0.8353333333333334, 0.8320833333333333, 0.84375, 0.8410833333333333], [0.35159709095954894, 0.3579048192501068, 0.3501501774787903, 0.33594816565513613, 0.3741619431972504, 0.34183687329292295, 0.3353554099798203, 0.32617265462875367, 0.3640907108783722, 0.33187183618545535, 0.32401839792728426, 0.30536725163459777, 0.31303414940834046, 0.2893040508031845, 0.3063929396867752, 0.2909839802980423, 0.2858921372890472, 0.2850045281648636, 0.28049838364124297, 0.2873564797639847], [0.816875, 0.793125, 0.810625, 0.821875, 0.8175, 0.82, 0.816875, 0.814375, 0.828125, 0.83875, 0.818125, 0.843125, 0.834375, 0.85875, 0.874375, 0.85375, 0.870625, 0.85375, 0.883125, 0.848125]], [0.75, 0, [0.37716902824158366, 0.3260373148195287, 0.3128290904012132, 0.2998493126732238, 0.29384377892030045, 0.2759418967873492, 0.26431119905665834, 0.2577077782455277, 0.25772295725789474, 0.24954422610871335, 0.24065862928933285, 0.23703582263848882, 0.23237684028262787, 0.2200249534575863, 0.22110319957929722, 0.21804759631607126, 0.21419822757548473, 0.19927451733816812, 0.19864692467641323, 0.18966749441274938], [0.8215833333333333, 0.848, 0.8526666666666667, 0.8585, 0.8639166666666667, 0.8716666666666667, 0.8783333333333333, 0.8849166666666667, 0.88325, 0.88325, 0.8918333333333334, 0.8913333333333333, 0.896, 0.9010833333333333, 0.8996666666666666, 0.9016666666666666, 0.902, 0.9120833333333334, 0.9105833333333333, 0.9160833333333334], [0.3255926352739334, 0.3397491586208343, 0.3148202610015869, 0.30447013437747955, 0.27427292466163633, 0.2607581865787506, 0.2583494257926941, 0.24150457441806794, 0.24839721441268922, 0.24157819360494615, 0.24594406485557557, 0.2547012311220169, 0.24132476687431337, 0.2433958488702774, 0.2358475297689438, 0.24675665378570558, 0.23343635857105255, 0.22841362684965133, 0.2247604575753212, 0.24281086921691894], [0.85125, 0.85125, 0.853125, 0.851875, 0.876875, 0.87875, 0.883125, 0.888125, 0.89, 0.888125, 0.88375, 0.86625, 0.88375, 0.888125, 0.898125, 0.88875, 0.896875, 0.894375, 0.899375, 0.88625]], [0.75, 0.25, [0.3795942336796446, 0.33614943612446174, 0.3235826115024851, 0.3267444484728448, 0.30353531146303137, 0.29750882636042353, 0.2964640334248543, 0.28714796314214136, 0.2744278162717819, 0.27310871372514584, 0.2624819800257683, 0.2579742945889209, 0.25963644726954876, 0.25635017161356644, 0.2501001837960583, 0.24249463702769988, 0.23696896695393196, 0.23254455582417072, 0.22419108628751117, 0.22851746232110134], [0.8204166666666667, 0.839, 0.847, 0.8506666666666667, 0.8571666666666666, 0.8635, 0.8639166666666667, 0.8711666666666666, 0.8711666666666666, 0.87475, 0.87875, 0.87925, 0.8805833333333334, 0.8845, 0.88675, 0.8908333333333334, 0.8926666666666667, 0.89525, 0.8985, 0.8955833333333333], [0.3383863967657089, 0.31120560944080355, 0.32110977828502657, 0.3080899566411972, 0.2866462391614914, 0.27701647162437437, 0.29040718913078306, 0.2702513742446899, 0.2590403389930725, 0.26199558019638064, 0.26484714448451996, 0.2940529054403305, 0.2654808533191681, 0.25154681205749513, 0.26637687146663663, 0.24435366928577423, 0.24174826145172118, 0.2444209086894989, 0.247626873254776, 0.24192263156175614], [0.843125, 0.8575, 0.86, 0.86375, 0.87, 0.875625, 0.865, 0.88, 0.879375, 0.885, 0.888125, 0.85625, 0.87625, 0.88375, 0.879375, 0.888125, 0.8875, 0.886875, 0.8825, 0.8925]], [0.75, 0.5, [0.41032169133107715, 0.37122817583223605, 0.35897897873470125, 0.3438001747064768, 0.33858899811797954, 0.3389760729797343, 0.32536247420184156, 0.3152934226425404, 0.30936657058748795, 0.3078679118226183, 0.30974164977669716, 0.30031369174731537, 0.29489042173991814, 0.28921707251921613, 0.28369594476324445, 0.2849519875772456, 0.27076949349584734, 0.26930386248104116, 0.26349931491657774, 0.26431971300948176], [0.8086666666666666, 0.82875, 0.8284166666666667, 0.8381666666666666, 0.837, 0.8389166666666666, 0.8490833333333333, 0.8488333333333333, 0.8533333333333334, 0.8551666666666666, 0.8509166666666667, 0.8615, 0.8628333333333333, 0.86225, 0.8715, 0.86775, 0.8748333333333334, 0.8719166666666667, 0.8814166666666666, 0.8835], [0.3464747530221939, 0.3193131250143051, 0.3464068531990051, 0.3129056388139725, 0.3131117367744446, 0.30689118325710296, 0.2929005026817322, 0.3131696957349777, 0.302835636138916, 0.27934255003929137, 0.300513002872467, 0.26962003886699676, 0.2676294481754303, 0.26430738389492037, 0.2525753951072693, 0.2508367341756821, 0.25303518533706665, 0.24774718701839446, 0.24518848478794097, 0.26084545016288757], [0.8225, 0.85375, 0.849375, 0.853125, 0.85875, 0.848125, 0.856875, 0.8575, 0.87, 0.869375, 0.863125, 0.886875, 0.8725, 0.878125, 0.894375, 0.888125, 0.8875, 0.89125, 0.88875, 0.86875]], [0.75, 0.75, [0.4765880586619073, 0.4503744399928032, 0.4249279998401378, 0.42333967214886176, 0.4236916420941657, 0.4269233151002133, 0.4192506206479478, 0.41413671872083174, 0.41084911515738104, 0.389948022413127, 0.39566395788433706, 0.3741930383951106, 0.3794517093040842, 0.3692300356131919, 0.3640432547223061, 0.3608953575504587, 0.3419572095129084, 0.34907091543712515, 0.33601277535583113, 0.3408893179544743], [0.77625, 0.7823333333333333, 0.7916666666666666, 0.80075, 0.7973333333333333, 0.7810833333333334, 0.7928333333333333, 0.7930833333333334, 0.7951666666666667, 0.8015833333333333, 0.8000833333333334, 0.8126666666666666, 0.811, 0.81775, 0.8236666666666667, 0.8215, 0.8305833333333333, 0.8251666666666667, 0.8299166666666666, 0.836], [0.3674533206224442, 0.36733597874641416, 0.35894496202468873, 0.3514183223247528, 0.35345671892166136, 0.36494161546230314, 0.35217500329017637, 0.3447349113225937, 0.34697150766849516, 0.36931039452552794, 0.3350031852722168, 0.3416145300865173, 0.32389605045318604, 0.3109715062379837, 0.3322615468502045, 0.327584428191185, 0.31910278856754304, 0.311815539598465, 0.2950947880744934, 0.2948034608364105], [0.808125, 0.789375, 0.826875, 0.821875, 0.81375, 0.804375, 0.80625, 0.83, 0.820625, 0.848125, 0.816875, 0.8125, 0.83, 0.84625, 0.824375, 0.828125, 0.825625, 0.840625, 0.8475, 0.844375]]]\n",
"data = [[0, 0, [0.400307985173582, 0.2597426520640662, 0.20706942731312025, 0.17091670006251475, 0.13984850759524653, 0.11444453444522518, 0.0929887340481538, 0.07584588486117436, 0.06030314570384176, 0.04997897459031356, 0.037156337104278056, 0.02793900864590992, 0.02030197833807442, 0.01789472087045391, 0.0175876492686666, 0.019220354652448274, 0.013543135874294319, 0.006956856955481477, 0.0024507183060002227, 0.00206579088377317], [0.8547833333333333, 0.9049, 0.9241666666666667, 0.9360166666666667, 0.94695, 0.9585833333333333, 0.9658666666666667, 0.9723166666666667, 0.9780333333333333, 0.9820166666666666, 0.9868, 0.9906666666666667, 0.9936833333333334, 0.9941333333333333, 0.99405, 0.9932833333333333, 0.9960666666666667, 0.9979666666666667, 0.9996666666666667, 0.9995666666666667], [0.36797549843788147, 0.2586278670430183, 0.24208260095119477, 0.24353929474949837, 0.24164094921946525, 0.2638056704550982, 0.2579395814836025, 0.27675500786304474, 0.2851512663513422, 0.30380481338500975, 0.3235128371268511, 0.3284085538983345, 0.3443841063082218, 0.41086878085136413, 0.457796107493341, 0.4356938077956438, 0.4109785168170929, 0.4433729724138975, 0.4688420155197382, 0.4773445381522179], [0.87, 0.908375, 0.91475, 0.915125, 0.91525, 0.91725, 0.924875, 0.91975, 0.922375, 0.92025, 0.920375, 0.924875, 0.9235, 0.918125, 0.91525, 0.918875, 0.923625, 0.9235, 0.92625, 0.925]], [0, 0.25, [0.4710115425463424, 0.3166707545550647, 0.25890692547440275, 0.22350736999753187, 0.19296910860009794, 0.17304379170113154, 0.15315235079105285, 0.13728606270383925, 0.12178339355929034, 0.10961619754736898, 0.10074329449495337, 0.08793247367408294, 0.07651288138686625, 0.06934997136779089, 0.06243234033510685, 0.056774082654433795, 0.05116950291028218, 0.04961718403588313, 0.04289388027836952, 0.040430180404756245], [0.8289666666666666, 0.8851833333333333, 0.9045166666666666, 0.9167666666666666, 0.9294166666666667, 0.93545, 0.94275, 0.9486666666666667, 0.95365, 0.95855, 0.9618833333333333, 0.9667, 0.9717666666666667, 0.9745833333333334, 0.9765833333333334, 0.9793, 0.9809833333333333, 0.9820333333333333, 0.9839166666666667, 0.9849166666666667], [0.3629846270084381, 0.31240448981523516, 0.24729759228229523, 0.2697310926616192, 0.24718070650100707, 0.23403583562374114, 0.2295891786813736, 0.22117181441187858, 0.2475375788807869, 0.23771390727162361, 0.2562992911040783, 0.25533875498175623, 0.27057862806320193, 0.2820998176634312, 0.29471745146811007, 0.2795617451965809, 0.3008101430237293, 0.28815430629253386, 0.31814645100384953, 0.3106237706840038], [0.874125, 0.88875, 0.908875, 0.9045, 0.9145, 0.918125, 0.919375, 0.9245, 0.91975, 0.926, 0.923625, 0.925875, 0.92475, 0.926375, 0.925125, 0.92525, 0.924625, 0.930875, 0.924875, 0.926625]], [0, 0.5, [0.6091368444629316, 0.40709905083309106, 0.33330900164873106, 0.29541655938063605, 0.26824146830864043, 0.24633059249535552, 0.22803501166832219, 0.21262132842689435, 0.20038021789160745, 0.18430457027680647, 0.1744787511763288, 0.165271017740149, 0.15522625095554507, 0.1432937567076608, 0.13617747858651222, 0.12876031456241158, 0.12141566201230325, 0.11405601029369686, 0.11116664642408522, 0.10308189516060992], [0.7803833333333333, 0.8559166666666667, 0.8823, 0.89505, 0.9027333333333334, 0.9099166666666667, 0.9162333333333333, 0.9224833333333333, 0.9243166666666667, 0.9321, 0.9345833333333333, 0.9375333333333333, 0.9418833333333333, 0.9456666666666667, 0.9482333333333334, 0.9513666666666667, 0.9527333333333333, 0.9559, 0.9576166666666667, 0.9611], [0.36491659212112426, 0.29200539910793305, 0.2840233483910561, 0.2591339669823646, 0.24114771646261215, 0.2436459481716156, 0.2374294084906578, 0.24284198743104934, 0.22679156363010405, 0.2229055170416832, 0.21932773572206496, 0.23045065227150918, 0.23631879675388337, 0.22048399156332016, 0.2563135535418987, 0.2494968646839261, 0.24099056956171988, 0.23974315640330315, 0.24684958010911942, 0.25887142738699914], [0.8665, 0.8925, 0.897, 0.907375, 0.914125, 0.9125, 0.913875, 0.911875, 0.921125, 0.922625, 0.923375, 0.924125, 0.922625, 0.926, 0.915625, 0.926125, 0.932625, 0.927875, 0.93, 0.92525]], [0, 0.75, [1.187068938827718, 0.9080034740316842, 0.6863665148329887, 0.5706229420867301, 0.5069490017921432, 0.46316734996876485, 0.42913920047885573, 0.4107565824855874, 0.3908677859061054, 0.37283689377785745, 0.3606657798388111, 0.353545261082301, 0.34009441143986, 0.3239413740506559, 0.3193119444620253, 0.31045137204404577, 0.3003838519091164, 0.29092520530194615, 0.28635713599447504, 0.2760026559138349], [0.5551333333333334, 0.6467, 0.7338666666666667, 0.7841333333333333, 0.8128, 0.82845, 0.8430833333333333, 0.8501666666666666, 0.8580833333333333, 0.8646166666666667, 0.8667666666666667, 0.8709833333333333, 0.8766166666666667, 0.8816666666666667, 0.8812, 0.88465, 0.8898833333333334, 0.8934666666666666, 0.8940833333333333, 0.8977666666666667], [0.6463955206871033, 0.5193838343620301, 0.4155286856889725, 0.3316091845035553, 0.3148408111333847, 0.29354524302482604, 0.2875490103960037, 0.26903486740589144, 0.27737221759557723, 0.262776792883873, 0.25498255288600924, 0.2390553195178509, 0.24918611392378806, 0.23830307483673097, 0.23538302001357078, 0.24996423116326333, 0.2464654156267643, 0.24081429636478424, 0.23204647853970528, 0.23771219885349273], [0.763875, 0.81925, 0.8685, 0.8885, 0.8895, 0.895625, 0.902, 0.904125, 0.906125, 0.908, 0.909375, 0.9145, 0.916125, 0.9175, 0.91875, 0.91425, 0.915375, 0.918875, 0.91975, 0.91825]], [0.25, 0, [0.4140813298491654, 0.27481235485118843, 0.22397600941614174, 0.1890777693286951, 0.16538111197112848, 0.1448796250478132, 0.12440053254032313, 0.10817898457734855, 0.09634132136696025, 0.08548538653410352, 0.07339220296349257, 0.06470446296305314, 0.060030178171393875, 0.053294485403614034, 0.04429284706704323, 0.04014099264770115, 0.03974721442450951, 0.03304463665041803, 0.02955428938137994, 0.026940144761875052], [0.8496666666666667, 0.8982666666666667, 0.9162166666666667, 0.9292166666666667, 0.93805, 0.9457666666666666, 0.9534333333333334, 0.9596, 0.9645833333333333, 0.9679, 0.9726166666666667, 0.9761666666666666, 0.9775, 0.9800166666666666, 0.9842, 0.9855333333333334, 0.9857, 0.98805, 0.9895666666666667, 0.9905833333333334], [0.3327465409040451, 0.27738857254385946, 0.23834018683433533, 0.24359044748544692, 0.23630736249685289, 0.26239568686485293, 0.23089197066426276, 0.23183160039782524, 0.2287161501646042, 0.23795067170262338, 0.2680365410447121, 0.28079107534885406, 0.2745736412107945, 0.27641161236166956, 0.2967236565724015, 0.29836027943715454, 0.28526886811852453, 0.3188628684282303, 0.3159900237545371, 0.33990017675608397], [0.876875, 0.899875, 0.918125, 0.9105, 0.918125, 0.91, 0.92075, 0.922625, 0.924, 0.921, 0.920875, 0.921, 0.9285, 0.927625, 0.9265, 0.927375, 0.925875, 0.927, 0.92575, 0.925875]], [0.25, 0.25, [0.48859380523978013, 0.3269256727337075, 0.275135099903734, 0.24039912359244914, 0.21368402032566858, 0.19328243048317523, 0.17890911489359732, 0.16624130663682402, 0.15215728174088827, 0.1416037013468299, 0.13273427299440288, 0.12227611260405227, 0.11463099068699917, 0.10616964906720179, 0.09988978996809357, 0.09424899211093815, 0.08670466838887077, 0.0835973875783781, 0.0778748192367698, 0.07327510508696741], [0.82055, 0.8806666666666667, 0.9004333333333333, 0.9117333333333333, 0.9206333333333333, 0.92785, 0.9333, 0.9384166666666667, 0.9430333333333333, 0.9471833333333334, 0.95055, 0.9540166666666666, 0.9568833333333333, 0.9601666666666666, 0.9620333333333333, 0.9652, 0.9676833333333333, 0.9682666666666667, 0.9706, 0.9724333333333334], [0.34025013536214826, 0.29788709819316866, 0.2680273652672768, 0.2463292105793953, 0.23471139985322953, 0.22580294385552407, 0.21676637730002404, 0.20925517010688782, 0.23552959233522416, 0.21975916308164598, 0.23494828915596008, 0.21611644634604454, 0.22251244640350343, 0.22066593673825263, 0.2214409472346306, 0.22849382662773132, 0.24493269926309585, 0.2397777333110571, 0.23578458192944526, 0.2563280282020569], [0.870875, 0.8875, 0.900375, 0.906625, 0.9145, 0.921125, 0.92125, 0.92425, 0.916, 0.923125, 0.920375, 0.92675, 0.92575, 0.924875, 0.925, 0.924875, 0.922875, 0.931125, 0.932375, 0.929]], [0.25, 0.5, [0.6104797730917362, 0.42115319246994154, 0.3527538229359874, 0.3136731511446586, 0.2857721160565104, 0.26646374052426197, 0.24732486170523965, 0.23057452346613286, 0.21953405395769743, 0.20952929538100767, 0.19584925043811677, 0.18926965880162044, 0.18003955145856973, 0.17379174885878176, 0.16635702809354644, 0.15807223409366633, 0.1509416516620054, 0.1477138751140758, 0.14028569269798266, 0.13906246528172417], [0.7786833333333333, 0.8482166666666666, 0.8730833333333333, 0.888, 0.8978, 0.9033666666666667, 0.9089166666666667, 0.9147666666666666, 0.91955, 0.9221833333333334, 0.92715, 0.9309666666666667, 0.9334, 0.93495, 0.9376833333333333, 0.9402666666666667, 0.94405, 0.9439166666666666, 0.9466833333333333, 0.9464833333333333], [0.3859497320652008, 0.3124091213941574, 0.28177140313386917, 0.2564259949326515, 0.24969424712657928, 0.23137387067079543, 0.22758139592409135, 0.22978509336709976, 0.2293499847650528, 0.22430640310049058, 0.21563700905442237, 0.21529569518566133, 0.22171301135420798, 0.2105387990772724, 0.21190602815151213, 0.21494245541095733, 0.21312989933788776, 0.20670134457945824, 0.2146600303351879, 0.21474341893941165], [0.86, 0.888, 0.89625, 0.907, 0.908, 0.915, 0.917875, 0.92, 0.921125, 0.917625, 0.924, 0.921875, 0.925875, 0.92575, 0.928125, 0.92775, 0.928625, 0.93075, 0.92975, 0.930375]], [0.25, 0.75, [1.1724896589194789, 0.8803599189911315, 0.692622532690766, 0.5974764075837156, 0.5319996399920124, 0.49373906012028773, 0.4741932853007876, 0.45601858158927483, 0.43706520244892216, 0.4238534729236733, 0.41077356216813454, 0.38932509837882606, 0.3771154705856019, 0.3687882057305719, 0.34927689276937485, 0.3379922736602933, 0.33547254843212393, 0.3263144160448107, 0.31800466419251233, 0.3133781185822446], [0.5631833333333334, 0.6579333333333334, 0.7342166666666666, 0.7765833333333333, 0.8036333333333333, 0.8197166666666666, 0.82755, 0.8320166666666666, 0.8397833333333333, 0.8432666666666667, 0.8519333333333333, 0.85835, 0.86285, 0.8641, 0.87105, 0.8756666666666667, 0.8775166666666666, 0.87965, 0.88255, 0.8832333333333333], [0.5745115535259246, 0.4740168128013611, 0.4092038922309876, 0.345498643040657, 0.32894178831577303, 0.2999964846372604, 0.28456189918518066, 0.28186965006589887, 0.26958267349004744, 0.26703972268104553, 0.2667745503783226, 0.2553461962342262, 0.25764305877685545, 0.2528705199956894, 0.24987997275590895, 0.24210182267427444, 0.2366510547697544, 0.24053962442278862, 0.22825994032621383, 0.2270425768494606], [0.776875, 0.822625, 0.848875, 0.87825, 0.88925, 0.899875, 0.9015, 0.904375, 0.9035, 0.906, 0.906875, 0.91125, 0.907, 0.908625, 0.91175, 0.917125, 0.91675, 0.916125, 0.919875, 0.917625]], [0.5, 0, [0.43062501005145276, 0.29807482149078646, 0.2541527441585623, 0.21918726423338278, 0.1950343672964555, 0.17517360023010387, 0.16213757058244144, 0.14869415854364, 0.13477844860392815, 0.12352272007129848, 0.11392300839184412, 0.10589898744228679, 0.09751250602896692, 0.089864786467088, 0.08516462990539526, 0.07973235945548934, 0.07441158362824137, 0.07053931183896578, 0.06258528833356954, 0.06177985634201014], [0.8429, 0.88905, 0.9052166666666667, 0.9182166666666667, 0.92755, 0.9337666666666666, 0.93835, 0.944, 0.9489333333333333, 0.95365, 0.9565333333333333, 0.9599166666666666, 0.9637833333333333, 0.9659666666666666, 0.9685666666666667, 0.9705, 0.9713666666666667, 0.9738, 0.9770166666666666, 0.9769833333333333], [0.32814766228199005, 0.29447353577613833, 0.25052148789167406, 0.22761481428146363, 0.23280890756845474, 0.23155913531780242, 0.21984874603152274, 0.2166314404308796, 0.2202563073039055, 0.22508277136087418, 0.2237191815972328, 0.2246915928721428, 0.22815296687185765, 0.2254556802213192, 0.2337513281852007, 0.2381753808259964, 0.24798179551959038, 0.24766947883367538, 0.24877363580465317, 0.2518915164768696], [0.879625, 0.89025, 0.907875, 0.916625, 0.91625, 0.91825, 0.920875, 0.923625, 0.922625, 0.923, 0.92575, 0.927125, 0.928625, 0.92625, 0.925375, 0.925625, 0.926375, 0.92475, 0.9255, 0.92675]], [0.5, 0.25, [0.5022556754285847, 0.3545388207554436, 0.2965180559564374, 0.2689443711818917, 0.24340009927622544, 0.22504497168144819, 0.21177587015574167, 0.19926073912507308, 0.18498492261557692, 0.1792394390810273, 0.16716771742809555, 0.16088557891500022, 0.15540826101420022, 0.1471743908549931, 0.14383414784458273, 0.1351151093741311, 0.1312572255915305, 0.12904865093140014, 0.12332957751079918, 0.11934908895072208], [0.8186333333333333, 0.8711666666666666, 0.8905666666666666, 0.9020666666666667, 0.9106333333333333, 0.9169333333333334, 0.9227, 0.9258166666666666, 0.9317, 0.9329666666666667, 0.9384833333333333, 0.9394333333333333, 0.94185, 0.9447666666666666, 0.9449833333333333, 0.9489, 0.9506, 0.9520333333333333, 0.95295, 0.9556833333333333], [0.37072600054740906, 0.2894986196160316, 0.2896255247592926, 0.2553737629055977, 0.2347450014948845, 0.23144772934913635, 0.22532679361104965, 0.2152210614681244, 0.21610748746991157, 0.22872606116533278, 0.22058768355846406, 0.20230921444296837, 0.2118315652012825, 0.20028054055571556, 0.20844366964697839, 0.20884322375059128, 0.21231223946809769, 0.19875787001848222, 0.2072589308321476, 0.22480831852555275], [0.862, 0.894, 0.892375, 0.906375, 0.912625, 0.91375, 0.916875, 0.918875, 0.92125, 0.9185, 0.920375, 0.92825, 0.9255, 0.92925, 0.926875, 0.9285, 0.926375, 0.93075, 0.931125, 0.922875]], [0.5, 0.5, [0.6208003907124879, 0.4341448332582201, 0.3655890760454796, 0.3245583019102179, 0.3000562671722888, 0.2840681741280215, 0.2686156402947679, 0.25843519997844566, 0.24892204790227196, 0.23988707410469493, 0.22968693327770304, 0.22323107979953416, 0.21376596502403714, 0.21353628940340172, 0.208721635311143, 0.20283085862393063, 0.19862186088204892, 0.1939613972542319, 0.18833921627917968, 0.18451892669552933], [0.7769666666666667, 0.8453333333333334, 0.86965, 0.88425, 0.8911, 0.8957666666666667, 0.90125, 0.9056666666666666, 0.9083833333333333, 0.9122666666666667, 0.91455, 0.9176833333333333, 0.92035, 0.9217, 0.9232333333333334, 0.9238333333333333, 0.9270333333333334, 0.9283, 0.93035, 0.9312333333333334], [0.390482270359993, 0.3140819278359413, 0.286346542596817, 0.26530489122867584, 0.25648517191410064, 0.25534764647483826, 0.24066219604015351, 0.22813884472846985, 0.22091108289361, 0.22591463786363603, 0.22548504903912545, 0.21807716876268388, 0.23463654381036758, 0.21917386519908905, 0.2077158398628235, 0.2112607652246952, 0.205703763961792, 0.21748955991864205, 0.20092388433218003, 0.20742826372385026], [0.859125, 0.884375, 0.89225, 0.9035, 0.9045, 0.904875, 0.907875, 0.915375, 0.914875, 0.915375, 0.916375, 0.92075, 0.91575, 0.91825, 0.92375, 0.924, 0.924875, 0.917125, 0.926875, 0.920875]], [0.5, 0.75, [1.1608194957918196, 0.8736483463918222, 0.7270457689632485, 0.6118623841482439, 0.5539627463769302, 0.5169604117872872, 0.4843029365547176, 0.4664089765979537, 0.449539397952399, 0.4308713404481599, 0.4170197155842903, 0.4104185118508746, 0.3983522486299086, 0.3890672579232945, 0.38423672571047535, 0.38125834129512437, 0.36963055836461756, 0.36898326972273116, 0.3608236700328174, 0.35822524538617145], [0.56785, 0.6591833333333333, 0.71765, 0.7660333333333333, 0.7931666666666667, 0.8079666666666667, 0.8198833333333333, 0.8275166666666667, 0.8349833333333333, 0.8422, 0.8473666666666667, 0.8486833333333333, 0.85425, 0.85675, 0.8578666666666667, 0.8603333333333333, 0.8643333333333333, 0.8637833333333333, 0.8684333333333333, 0.8680166666666667], [0.5984484012126923, 0.5152713191509247, 0.42289899206161496, 0.3746640253067017, 0.3369040569067001, 0.32359291434288023, 0.2978636801838875, 0.2998174095153809, 0.2883352539539337, 0.2839300352931023, 0.2775397801399231, 0.2616970262527466, 0.259125192284584, 0.25470315623283385, 0.2535187450051308, 0.2600560383200645, 0.25031394577026367, 0.2547155976295471, 0.23950587111711502, 0.24401323813199996], [0.750875, 0.78025, 0.86225, 0.869875, 0.884875, 0.891625, 0.898875, 0.89275, 0.901875, 0.9005, 0.899875, 0.908375, 0.91125, 0.910375, 0.910375, 0.907, 0.9135, 0.910375, 0.914125, 0.911625]], [0.75, 0, [0.5018121279410716, 0.3649225841834347, 0.31199926770985253, 0.2825479824850554, 0.25993211727057186, 0.2431308363737074, 0.22870161555913973, 0.22126636312587428, 0.2113911879540824, 0.20279224649834227, 0.19300907663603836, 0.18686007729360163, 0.1815741605866057, 0.1759802805684777, 0.17041425832084564, 0.16513840764014323, 0.15892388751861383, 0.1548161118118557, 0.1498002242614656, 0.14744469122107284], [0.8158, 0.8648, 0.8846833333333334, 0.8954666666666666, 0.9035333333333333, 0.9097666666666666, 0.9142666666666667, 0.91615, 0.9219166666666667, 0.9239333333333334, 0.9268166666666666, 0.9287666666666666, 0.9304833333333333, 0.9327333333333333, 0.9365, 0.9368666666666666, 0.9395333333333333, 0.9418833333333333, 0.9445, 0.9450166666666666], [0.35916801404953, 0.30038927191495896, 0.2824265750646591, 0.28094157111644746, 0.2402345055937767, 0.24779821130633353, 0.2263277245759964, 0.22270147562026976, 0.22010754531621932, 0.20850908517837524, 0.21723379525542258, 0.20454896742105483, 0.2065480750799179, 0.20593296563625335, 0.21030707907676696, 0.2015896993279457, 0.19770563289523124, 0.19552358242869378, 0.197759574085474, 0.19900305101275445], [0.867125, 0.890875, 0.896875, 0.896, 0.912125, 0.90875, 0.9185, 0.916875, 0.920375, 0.925125, 0.919375, 0.92675, 0.927125, 0.924625, 0.924125, 0.9275, 0.928, 0.928875, 0.93325, 0.930125]], [0.75, 0.25, [0.564780301424359, 0.41836969141385705, 0.3581543931924204, 0.3251280398018706, 0.30215959723538427, 0.28700008430778345, 0.27507679125488693, 0.26540731782439164, 0.25373875692105496, 0.24964979071734048, 0.24098571216357922, 0.23604591902512223, 0.2270722362135392, 0.2229606584985373, 0.22031292727570545, 0.21439386613126885, 0.21020108821200156, 0.2042837777872012, 0.20376247368149283, 0.20021205727082453], [0.7927, 0.8474166666666667, 0.8672166666666666, 0.8811833333333333, 0.8883, 0.8952833333333333, 0.89795, 0.9011333333333333, 0.9055833333333333, 0.9071166666666667, 0.9100333333333334, 0.911, 0.91515, 0.9162166666666667, 0.91775, 0.9197833333333333, 0.9218666666666666, 0.9239, 0.9236833333333333, 0.92455], [0.39558523416519165, 0.3187315353155136, 0.30105597496032716, 0.2717038299441338, 0.25286867189407347, 0.24664685553312302, 0.24286985045671464, 0.23643679201602935, 0.23006864881515504, 0.2277349520921707, 0.22591854375600814, 0.2165311907827854, 0.21385486593842506, 0.21402871897816658, 0.2096972267627716, 0.21242560443282127, 0.2098898750245571, 0.2062524998188019, 0.19932547932863234, 0.20170186588168143], [0.850625, 0.88125, 0.8845, 0.897125, 0.9065, 0.9085, 0.907625, 0.91275, 0.917125, 0.9135, 0.91825, 0.922625, 0.91925, 0.921125, 0.923625, 0.92225, 0.923375, 0.922875, 0.925625, 0.92775]], [0.75, 0.5, [0.6916971901205303, 0.4947840944567977, 0.41710148827988963, 0.38678343986460906, 0.36429949198513906, 0.34339441834831796, 0.33055868282564665, 0.3199633415272114, 0.31550557391920575, 0.3022628513289921, 0.2959158662110885, 0.2941135993993867, 0.28555906579089063, 0.27903660322462065, 0.2769482293601102, 0.27154609372716215, 0.26548120195963487, 0.26188135733291795, 0.2588035051009929, 0.2574938320115939], [0.7497333333333334, 0.8236833333333333, 0.8482333333333333, 0.8618666666666667, 0.8703666666666666, 0.8772166666666666, 0.8803333333333333, 0.8829166666666667, 0.88525, 0.88945, 0.89275, 0.8937166666666667, 0.8969, 0.8977666666666667, 0.9, 0.90175, 0.9041666666666667, 0.9035, 0.9049, 0.9046166666666666], [0.41916924858093263, 0.3380992366075516, 0.31549062132835387, 0.2921286026239395, 0.2786481494307518, 0.28516836106777194, 0.25556409001350405, 0.2538892236948013, 0.24726227968931197, 0.24262803781032563, 0.24080126863718032, 0.24242325466871262, 0.23416680485010147, 0.22847312396764755, 0.22423979061841964, 0.2311997367441654, 0.22794704174995423, 0.21943940049409866, 0.21820387506484987, 0.21150743806362152], [0.8435, 0.87725, 0.88425, 0.890375, 0.898125, 0.89275, 0.905625, 0.906125, 0.911, 0.910625, 0.911, 0.909875, 0.914875, 0.915375, 0.917875, 0.915, 0.91475, 0.919625, 0.923875, 0.92425]], [0.75, 0.75, [1.162218615571573, 0.8284856370453642, 0.7309887468624217, 0.6590983641744931, 0.6089096262510906, 0.5663433943285363, 0.5383681068733048, 0.5242803116787725, 0.49926126579930785, 0.48940120944018556, 0.4789252862779062, 0.46633604049746163, 0.4596060775458686, 0.4464966354847971, 0.4418302221593064, 0.43759817490254893, 0.42892070028827645, 0.4226101264516428, 0.418694807601763, 0.4110745745840103], [0.58005, 0.6824666666666667, 0.7223333333333334, 0.7464333333333333, 0.7711333333333333, 0.7891833333333333, 0.8012333333333334, 0.80635, 0.8172666666666667, 0.82225, 0.8271833333333334, 0.831, 0.8335833333333333, 0.8371833333333333, 0.8412166666666666, 0.84265, 0.8458833333333333, 0.8471166666666666, 0.8497666666666667, 0.8522833333333333], [0.5945872340202332, 0.518519122838974, 0.4681703653335571, 0.42978407418727876, 0.40349935555458066, 0.37377681517601014, 0.35234942865371705, 0.3359788683652878, 0.3217720929384232, 0.3279728285074234, 0.3114012089371681, 0.3060767319202423, 0.2949701727628708, 0.2981588536500931, 0.2855641575455666, 0.28112928783893587, 0.28212732630968096, 0.27846804082393645, 0.27372796374559405, 0.27415593349933626], [0.78525, 0.8215, 0.820125, 0.844375, 0.86375, 0.875125, 0.876625, 0.882, 0.887875, 0.884625, 0.890375, 0.892125, 0.897125, 0.894125, 0.902625, 0.89975, 0.89975, 0.90125, 0.902, 0.90075]]]\n",
"\n",
"\n",
"Dropout1 = 0.25 # param {type:\"slider\", min:0, max:0.75, step:0.25}\n",
"Dropout2 = 0.75 # param {type:\"slider\", min:0, max:0.75, step:0.25}\n",
"\n",
"def plot(Dropout1, Dropout2):\n",
" d1, d2, train_loss, train_acc, validation_loss, validation_acc = data[int(Dropout1 * 4) * 4 + int(Dropout2 * 4)]\n",
" print(d1, d2)\n",
" plot_loss_accuracy(train_loss, train_acc, validation_loss, validation_acc)\n",
" plt.gcf().axes[0].set_ylim(0, 1.2)\n",
" plt.gcf().axes[1].set_ylim(0.5, 1)\n",
"\n",
" my_stringIObytes = io.BytesIO()\n",
" plt.savefig(my_stringIObytes, format='png', dpi=90)\n",
" my_stringIObytes.seek(0)\n",
" my_base64_jpgData = base64.b64encode(my_stringIObytes.read())\n",
" plt.close()\n",
" p.value = \"\"\"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Adding_Regularization_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! Bonus 2.1: Regularization\n",
"\n",
"1. Is the training accuracy slightly reduced from before adding regularization? What accuracy were you able to reduce it to?\n",
"\n",
"2. Why does the validation accuracy start higher than training accuracy?\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_6e9ea2ef.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Adding_Regularization_Bonus_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo Bonus 2.1: Dropout exploration\n",
"\n",
"If you want to try out more dropout parameter combinations, but do not have the time to run them, we have here precalculated some combinations you can use the sliders to explore them."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" *Run this cell to enable the widget*\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown *Run this cell to enable the widget*\n",
"\n",
"import io, base64\n",
"from ipywidgets import widgets, interactive_output\n",
"\n",
"data = [[0, 0, [0.3495898238046372, 0.2901147632522786, 0.2504794800931469, 0.23571575765914105, 0.21297093365896255, 0.19087818914905508, 0.186408187797729, 0.19487689035211472, 0.16774938120803934, 0.1548648244958926, 0.1390149021382503, 0.10919439224922593, 0.10054351237820501, 0.09900783193594914, 0.08370604479507088, 0.07831853718318521, 0.06859792241866285, 0.06152600247383197, 0.046342475851873885, 0.055123823092992796], [0.83475, 0.8659166666666667, 0.8874166666666666, 0.8913333333333333, 0.8998333333333334, 0.9140833333333334, 0.9178333333333333, 0.9138333333333334, 0.9251666666666667, 0.92975, 0.939, 0.9525833333333333, 0.9548333333333333, 0.9585833333333333, 0.9655833333333333, 0.9661666666666666, 0.9704166666666667, 0.9743333333333334, 0.9808333333333333, 0.9775], [0.334623601436615, 0.2977438402175903, 0.2655304968357086, 0.25506321132183074, 0.2588835284113884, 0.2336345863342285, 0.3029863876104355, 0.240766831189394, 0.2719801160693169, 0.25231350839138034, 0.2500132185220718, 0.26699506521224975, 0.2934862145781517, 0.361227530837059, 0.33196919202804565, 0.36985905408859254, 0.4042587959766388, 0.3716402840614319, 0.3707024946808815, 0.4652537405490875], [0.866875, 0.851875, 0.8775, 0.889375, 0.881875, 0.900625, 0.85, 0.898125, 0.885625, 0.876875, 0.899375, 0.90625, 0.89875, 0.87, 0.898125, 0.884375, 0.874375, 0.89375, 0.903125, 0.890625]], [0, 0.25, [0.35404509995528993, 0.30616586227366266, 0.2872369573946963, 0.27564131199045383, 0.25969504263806853, 0.24728168408445855, 0.23505379509260046, 0.21552803914280647, 0.209761732277718, 0.19977611067526518, 0.19632092922767427, 0.18672360206379535, 0.16564940239124476, 0.1654047035671612, 0.1684555298985636, 0.1627526102349796, 0.13878319327263755, 0.12881529055773577, 0.12628930977525862, 0.11346105090837846], [0.8324166666666667, 0.8604166666666667, 0.8680833333333333, 0.8728333333333333, 0.8829166666666667, 0.88625, 0.89425, 0.90125, 0.9015833333333333, 0.90925, 0.9114166666666667, 0.917, 0.9268333333333333, 0.92475, 0.921, 0.9255833333333333, 0.9385, 0.9428333333333333, 0.9424166666666667, 0.9484166666666667], [0.3533937376737595, 0.29569859683513644, 0.27531551957130435, 0.2576177391409874, 0.26947550356388095, 0.25361743807792664, 0.2527468180656433, 0.24179009914398195, 0.28664454460144045, 0.23347773611545564, 0.24672816634178163, 0.27822364538908007, 0.2380720081925392, 0.24426509588956832, 0.2443918392062187, 0.24207917481660843, 0.2519641682505608, 0.3075403380393982, 0.2798181238770485, 0.26709021866321564], [0.826875, 0.87, 0.870625, 0.8875, 0.883125, 0.88625, 0.891875, 0.891875, 0.890625, 0.903125, 0.89375, 0.885625, 0.903125, 0.888125, 0.899375, 0.898125, 0.905, 0.905625, 0.898125, 0.901875]], [0, 0.5, [0.39775496332886373, 0.33771887778284704, 0.321900939132939, 0.3079229625774191, 0.304149763301966, 0.28249239723416086, 0.2861261191044716, 0.27356165798103554, 0.2654648520686525, 0.2697350280557541, 0.25354846321204877, 0.24612889034633942, 0.23482802549892284, 0.2389904112416379, 0.23742155821875055, 0.232423192127905, 0.22337309338469455, 0.2141852991932884, 0.20677659985549907, 0.19355326712607068], [0.8155, 0.83625, 0.8481666666666666, 0.8530833333333333, 0.8571666666666666, 0.86775, 0.8623333333333333, 0.8711666666666666, 0.8748333333333334, 0.8685833333333334, 0.8785, 0.8804166666666666, 0.8835833333333334, 0.8840833333333333, 0.88875, 0.8919166666666667, 0.8946666666666667, 0.8960833333333333, 0.906, 0.9063333333333333], [0.3430288594961166, 0.4062050700187683, 0.29745822548866274, 0.27728439271450045, 0.28092808067798614, 0.2577864158153534, 0.2651400637626648, 0.25632822573184966, 0.3082498562335968, 0.2812121778726578, 0.26345942318439486, 0.2577408078312874, 0.25757989794015884, 0.26434457510709763, 0.24917411386966706, 0.27261342853307724, 0.2445397639274597, 0.26001051396131514, 0.24147838801145555, 0.2471102523803711], [0.82875, 0.795625, 0.87, 0.87375, 0.865625, 0.8825, 0.8825, 0.87625, 0.848125, 0.87875, 0.8675, 0.889375, 0.8925, 0.866875, 0.87375, 0.87125, 0.895625, 0.90375, 0.90125, 0.88625]], [0, 0.75, [0.4454924576777093, 0.43416607585993217, 0.42200265769311723, 0.40520024616667566, 0.41137005166804536, 0.404100904280835, 0.40118067664034823, 0.40139733080534223, 0.3797615355158106, 0.3596332479030528, 0.3600061919460905, 0.3554147962242999, 0.34480382890460337, 0.3329520877054397, 0.33164913056695716, 0.31860941466181836, 0.30702565340919696, 0.30605297186907304, 0.2953788426486736, 0.2877389984403519], [0.7788333333333334, 0.7825, 0.7854166666666667, 0.7916666666666666, 0.7885, 0.7833333333333333, 0.7923333333333333, 0.79525, 0.805, 0.81475, 0.8161666666666667, 0.8188333333333333, 0.817, 0.8266666666666667, 0.82225, 0.8360833333333333, 0.8456666666666667, 0.8430833333333333, 0.8491666666666666, 0.8486666666666667], [0.3507828885316849, 0.3337512403726578, 0.34320746660232543, 0.3476085543632507, 0.3326113569736481, 0.33033264458179473, 0.32014619171619413, 0.3182142299413681, 0.30076164126396177, 0.3263852882385254, 0.27597591280937195, 0.29062016785144806, 0.2765174686908722, 0.269492534995079, 0.2679423809051514, 0.2691828978061676, 0.2726386785507202, 0.2541181230545044, 0.2580208206176758, 0.26315389811992645], [0.839375, 0.843125, 0.823125, 0.821875, 0.81875, 0.819375, 0.8225, 0.826875, 0.835625, 0.865, 0.868125, 0.855625, 0.868125, 0.884375, 0.883125, 0.875, 0.87375, 0.883125, 0.8975, 0.885]], [0.25, 0, [0.34561181647029326, 0.2834314257699124, 0.2583787844298368, 0.23892096465730922, 0.23207981773513428, 0.20245029634617745, 0.183908417583146, 0.17489413774393975, 0.17696723581707857, 0.15615438255778652, 0.14469048382833283, 0.12424647461305907, 0.11314761043189371, 0.11249036608422373, 0.10725672634199579, 0.09081190969160896, 0.0942245383271353, 0.08525650047677312, 0.06622548752583246, 0.06039895973307021], [0.8356666666666667, 0.8675833333333334, 0.88175, 0.8933333333333333, 0.8975833333333333, 0.91175, 0.91825, 0.9249166666666667, 0.9238333333333333, 0.9305, 0.938, 0.9465833333333333, 0.9525833333333333, 0.9539166666666666, 0.9555, 0.9615, 0.9606666666666667, 0.96275, 0.9725, 0.9764166666666667], [0.31630186855792997, 0.2702121251821518, 0.2915778249502182, 0.26050266206264494, 0.27837209939956664, 0.24276352763175965, 0.3567117482423782, 0.2752074319124222, 0.2423130339384079, 0.2565067422389984, 0.28710135877132414, 0.266545415520668, 0.31818037331104276, 0.28757534325122835, 0.2777567034959793, 0.2998969575762749, 0.3292293107509613, 0.30775387287139894, 0.32681577146053314, 0.44882203072309496], [0.85375, 0.879375, 0.875625, 0.89, 0.86125, 0.884375, 0.851875, 0.8875, 0.89625, 0.875625, 0.8675, 0.895, 0.888125, 0.89125, 0.889375, 0.880625, 0.87875, 0.8875, 0.894375, 0.891875]], [0.25, 0.25, [0.35970850011452715, 0.31336131549261986, 0.2881505932421126, 0.2732012960267194, 0.26232245425753137, 0.2490472443639598, 0.24866499093935845, 0.22930880945096624, 0.21745950407645803, 0.20700296882460725, 0.197304340356842, 0.20665066804182022, 0.19864868348900308, 0.184807124210799, 0.1684703354703936, 0.17377675851767369, 0.16638460063791655, 0.15944768343754906, 0.14876513817208878, 0.1388207479835825], [0.83375, 0.85175, 0.86725, 0.8719166666666667, 0.8761666666666666, 0.8865833333333333, 0.88275, 0.8956666666666667, 0.8995833333333333, 0.9034166666666666, 0.90825, 0.9043333333333333, 0.9093333333333333, 0.9145, 0.9196666666666666, 0.9196666666666666, 0.9216666666666666, 0.9273333333333333, 0.9299166666666666, 0.93675], [0.3166788029670715, 0.28422485530376435, 0.38055971562862395, 0.2586472672224045, 0.2588653892278671, 0.27983254253864287, 0.25693483114242555, 0.26412731170654297, 0.2733065390586853, 0.24399636536836625, 0.24481021404266357, 0.2689305514097214, 0.2527604129910469, 0.24829535871744157, 0.2654112687706947, 0.23074268400669098, 0.24625462979078294, 0.26423920392990113, 0.25540480852127073, 0.25536185175180437], [0.856875, 0.86625, 0.815, 0.8825, 0.88125, 0.875625, 0.89, 0.8775, 0.870625, 0.895, 0.8975, 0.87375, 0.88625, 0.89125, 0.903125, 0.9, 0.893125, 0.89, 0.8925, 0.899375]], [0.25, 0.5, [0.3975753842040579, 0.34884724409339274, 0.3296900932142075, 0.3150389680361494, 0.31285368667003954, 0.30415422033439293, 0.29553352716438314, 0.289314468094009, 0.2806722329969102, 0.2724469883486311, 0.26634286379719035, 0.2645016222241077, 0.2619251853766594, 0.2551752221473354, 0.26411766035759704, 0.24515971153023394, 0.2390686312412962, 0.23573122312255362, 0.221005061562074, 0.22358600648635246], [0.8106666666666666, 0.8286666666666667, 0.844, 0.8513333333333334, 0.84975, 0.8570833333333333, 0.8624166666666667, 0.8626666666666667, 0.866, 0.8706666666666667, 0.8738333333333334, 0.8748333333333334, 0.8778333333333334, 0.8798333333333334, 0.87375, 0.8865, 0.8898333333333334, 0.8885833333333333, 0.8991666666666667, 0.8968333333333334], [0.3597823417186737, 0.31115993797779085, 0.29929635107517244, 0.2986589139699936, 0.2938830828666687, 0.28118040919303894, 0.2711684626340866, 0.2844697123765945, 0.26613601863384245, 0.2783134698867798, 0.2540236383676529, 0.25821100890636445, 0.2618845862150192, 0.2554920208454132, 0.26543013513088226, 0.24074569433927537, 0.26475649774074556, 0.25578504264354707, 0.2648500043153763, 0.25700133621692656], [0.825, 0.8375, 0.85875, 0.855625, 0.861875, 0.868125, 0.875, 0.85375, 0.886875, 0.86375, 0.88375, 0.885625, 0.875625, 0.87375, 0.8875, 0.895, 0.874375, 0.89125, 0.88625, 0.895625]], [0.25, 0.75, [0.4584837538447786, 0.4506375778545725, 0.4378386567089152, 0.4066803843734112, 0.3897064097542712, 0.3855383962868376, 0.39160584618753574, 0.3731403942120836, 0.37915910170116324, 0.36966170814443144, 0.35735995298687445, 0.35630573094525236, 0.346426092167484, 0.34040802899510303, 0.32829743726773464, 0.3284692421872565, 0.3186114077713895, 0.32295761503120685, 0.3201326223764014, 0.30581602454185486], [0.7803333333333333, 0.7709166666666667, 0.7723333333333333, 0.7850833333333334, 0.7885, 0.7903333333333333, 0.7986666666666666, 0.805, 0.8011666666666667, 0.8068333333333333, 0.8095833333333333, 0.8226666666666667, 0.8285, 0.83125, 0.8369166666666666, 0.8395, 0.8441666666666666, 0.8393333333333334, 0.8490833333333333, 0.8546666666666667], [0.43526833415031435, 0.3598956459760666, 0.3492005372047424, 0.33501910269260404, 0.31689528703689573, 0.3113307124376297, 0.32388085544109346, 0.3084335786104202, 0.3013568025827408, 0.28992725372314454, 0.28726822674274444, 0.26945948660373686, 0.276592333316803, 0.27462401330471037, 0.27574350595474245, 0.2710308712720871, 0.2702724140882492, 0.27323003828525544, 0.25551479041576386, 0.26488787233829497], [0.808125, 0.81625, 0.805, 0.8325, 0.846875, 0.835625, 0.850625, 0.838125, 0.836875, 0.861875, 0.85375, 0.866875, 0.858125, 0.8825, 0.879375, 0.874375, 0.874375, 0.886875, 0.883125, 0.86875]], [0.5, 0, [0.3579516930783049, 0.29596046564426826, 0.2779693031247626, 0.2563994538356015, 0.24771526356802342, 0.2324555875693864, 0.2139121579362991, 0.20474095547452886, 0.19138856208387842, 0.18883306279461434, 0.1763652620757831, 0.1698919345248253, 0.16033914366221808, 0.1557997044651432, 0.1432509447467771, 0.13817814606776896, 0.12609625801919622, 0.11830132696381275, 0.11182412960903441, 0.112559904720872], [0.8314166666666667, 0.8611666666666666, 0.8736666666666667, 0.8800833333333333, 0.885, 0.8944166666666666, 0.9036666666666666, 0.9090833333333334, 0.9193333333333333, 0.9161666666666667, 0.92225, 0.9255, 0.93075, 0.93225, 0.939, 0.9414166666666667, 0.94375, 0.9485833333333333, 0.9535833333333333, 0.9524166666666667], [0.30677567660808563, 0.32954772651195524, 0.25747098088264464, 0.2736126834154129, 0.2561805549263954, 0.23671718776226044, 0.24553639352321624, 0.2338863667845726, 0.24586652517318724, 0.23423030972480774, 0.26579618513584136, 0.2781539523601532, 0.27084136098623274, 0.23948652744293214, 0.26023868829011915, 0.2419952344894409, 0.2511997854709625, 0.23935708701610564, 0.2701922015845776, 0.27307246536016466], [0.870625, 0.855625, 0.886875, 0.875625, 0.878125, 0.8925, 0.885, 0.890625, 0.876875, 0.896875, 0.881875, 0.8875, 0.89, 0.898125, 0.896875, 0.89, 0.89875, 0.904375, 0.906875, 0.894375]], [0.5, 0.25, [0.3712943946903056, 0.3198322071594761, 0.29978102302931725, 0.295274139798068, 0.2861913934032968, 0.27165328782606635, 0.25972246442069397, 0.2543164194819141, 0.24795781916126292, 0.24630710007028378, 0.23296909834793272, 0.23382153587931015, 0.2239028559799524, 0.21443849290780564, 0.2149274461367663, 0.20642021417300752, 0.19801520536396097, 0.1978839404009124, 0.19118623847657062, 0.18144798041024107], [0.8235833333333333, 0.8538333333333333, 0.8604166666666667, 0.86075, 0.8664166666666666, 0.8754166666666666, 0.8799166666666667, 0.8815833333333334, 0.88725, 0.8848333333333334, 0.8936666666666667, 0.8935, 0.895, 0.8995, 0.89625, 0.9068333333333334, 0.9098333333333334, 0.9120833333333334, 0.91375, 0.9175833333333333], [0.3184810388088226, 0.2948088157176971, 0.29438531696796416, 0.27669853866100313, 0.2634278678894043, 0.25847582578659056, 0.2500907778739929, 0.2538330048322678, 0.25127841770648957, 0.2519759064912796, 0.2455715072154999, 0.2437664610147476, 0.259639236330986, 0.24515749186277389, 0.2553828465938568, 0.2324645048379898, 0.24492083072662355, 0.24482838332653045, 0.23327024638652802, 0.2520161652565002], [0.855, 0.865, 0.8525, 0.856875, 0.876875, 0.88125, 0.8825, 0.8875, 0.8925, 0.8925, 0.88875, 0.889375, 0.87375, 0.895, 0.889375, 0.90625, 0.883125, 0.895, 0.899375, 0.901875]], [0.5, 0.5, [0.40442772225496615, 0.36662670541951, 0.355034276367502, 0.3396551510755052, 0.3378269396563794, 0.32084332002287214, 0.31314464951766297, 0.2982726935693558, 0.2885229691387491, 0.2888992782285873, 0.2893476904706752, 0.281817957996688, 0.2771622718490185, 0.2693793097550565, 0.2617615883416952, 0.2657115764995205, 0.25631817549150043, 0.24793559907281654, 0.2538738044652533, 0.23912971732305718], [0.8093333333333333, 0.82825, 0.8341666666666666, 0.84525, 0.84525, 0.8515, 0.8583333333333333, 0.8626666666666667, 0.8688333333333333, 0.8685, 0.8689166666666667, 0.8693333333333333, 0.8711666666666666, 0.8766666666666667, 0.88275, 0.88175, 0.8839166666666667, 0.8866666666666667, 0.8839166666666667, 0.8929166666666667], [0.38392188608646394, 0.3653419762849808, 0.3050421380996704, 0.30614266455173494, 0.2937217426300049, 0.30008585572242735, 0.2794034606218338, 0.27541795969009397, 0.31378355383872986, 0.2670704126358032, 0.26745485186576845, 0.2471194839477539, 0.26509816259145735, 0.25458798944950106, 0.2481587851047516, 0.25591064751148224, 0.2596563971042633, 0.2569611769914627, 0.2435744071006775, 0.2507249677181244], [0.820625, 0.846875, 0.856875, 0.868125, 0.860625, 0.87125, 0.86625, 0.87375, 0.865625, 0.87875, 0.878125, 0.889375, 0.87875, 0.886875, 0.89125, 0.89, 0.87375, 0.884375, 0.88875, 0.89375]], [0.5, 0.75, [0.46106574311852455, 0.4519433615372536, 0.4446939624687459, 0.4284856241751224, 0.4527993325857406, 0.4220876024758562, 0.40969764266876463, 0.39233948219012704, 0.42498463344700793, 0.3869199570506177, 0.38021832910623954, 0.3855376149270129, 0.3721433773319772, 0.3662295250340979, 0.3629763710530514, 0.358500304691335, 0.3490118366131123, 0.34879197790584665, 0.33399240054348683, 0.3347948451149971], [0.7866666666666666, 0.7865, 0.784, 0.79375, 0.7755833333333333, 0.79125, 0.7973333333333333, 0.8085833333333333, 0.7913333333333333, 0.8125833333333333, 0.81675, 0.812, 0.8173333333333334, 0.8235833333333333, 0.831, 0.8306666666666667, 0.8353333333333334, 0.8320833333333333, 0.84375, 0.8410833333333333], [0.35159709095954894, 0.3579048192501068, 0.3501501774787903, 0.33594816565513613, 0.3741619431972504, 0.34183687329292295, 0.3353554099798203, 0.32617265462875367, 0.3640907108783722, 0.33187183618545535, 0.32401839792728426, 0.30536725163459777, 0.31303414940834046, 0.2893040508031845, 0.3063929396867752, 0.2909839802980423, 0.2858921372890472, 0.2850045281648636, 0.28049838364124297, 0.2873564797639847], [0.816875, 0.793125, 0.810625, 0.821875, 0.8175, 0.82, 0.816875, 0.814375, 0.828125, 0.83875, 0.818125, 0.843125, 0.834375, 0.85875, 0.874375, 0.85375, 0.870625, 0.85375, 0.883125, 0.848125]], [0.75, 0, [0.37716902824158366, 0.3260373148195287, 0.3128290904012132, 0.2998493126732238, 0.29384377892030045, 0.2759418967873492, 0.26431119905665834, 0.2577077782455277, 0.25772295725789474, 0.24954422610871335, 0.24065862928933285, 0.23703582263848882, 0.23237684028262787, 0.2200249534575863, 0.22110319957929722, 0.21804759631607126, 0.21419822757548473, 0.19927451733816812, 0.19864692467641323, 0.18966749441274938], [0.8215833333333333, 0.848, 0.8526666666666667, 0.8585, 0.8639166666666667, 0.8716666666666667, 0.8783333333333333, 0.8849166666666667, 0.88325, 0.88325, 0.8918333333333334, 0.8913333333333333, 0.896, 0.9010833333333333, 0.8996666666666666, 0.9016666666666666, 0.902, 0.9120833333333334, 0.9105833333333333, 0.9160833333333334], [0.3255926352739334, 0.3397491586208343, 0.3148202610015869, 0.30447013437747955, 0.27427292466163633, 0.2607581865787506, 0.2583494257926941, 0.24150457441806794, 0.24839721441268922, 0.24157819360494615, 0.24594406485557557, 0.2547012311220169, 0.24132476687431337, 0.2433958488702774, 0.2358475297689438, 0.24675665378570558, 0.23343635857105255, 0.22841362684965133, 0.2247604575753212, 0.24281086921691894], [0.85125, 0.85125, 0.853125, 0.851875, 0.876875, 0.87875, 0.883125, 0.888125, 0.89, 0.888125, 0.88375, 0.86625, 0.88375, 0.888125, 0.898125, 0.88875, 0.896875, 0.894375, 0.899375, 0.88625]], [0.75, 0.25, [0.3795942336796446, 0.33614943612446174, 0.3235826115024851, 0.3267444484728448, 0.30353531146303137, 0.29750882636042353, 0.2964640334248543, 0.28714796314214136, 0.2744278162717819, 0.27310871372514584, 0.2624819800257683, 0.2579742945889209, 0.25963644726954876, 0.25635017161356644, 0.2501001837960583, 0.24249463702769988, 0.23696896695393196, 0.23254455582417072, 0.22419108628751117, 0.22851746232110134], [0.8204166666666667, 0.839, 0.847, 0.8506666666666667, 0.8571666666666666, 0.8635, 0.8639166666666667, 0.8711666666666666, 0.8711666666666666, 0.87475, 0.87875, 0.87925, 0.8805833333333334, 0.8845, 0.88675, 0.8908333333333334, 0.8926666666666667, 0.89525, 0.8985, 0.8955833333333333], [0.3383863967657089, 0.31120560944080355, 0.32110977828502657, 0.3080899566411972, 0.2866462391614914, 0.27701647162437437, 0.29040718913078306, 0.2702513742446899, 0.2590403389930725, 0.26199558019638064, 0.26484714448451996, 0.2940529054403305, 0.2654808533191681, 0.25154681205749513, 0.26637687146663663, 0.24435366928577423, 0.24174826145172118, 0.2444209086894989, 0.247626873254776, 0.24192263156175614], [0.843125, 0.8575, 0.86, 0.86375, 0.87, 0.875625, 0.865, 0.88, 0.879375, 0.885, 0.888125, 0.85625, 0.87625, 0.88375, 0.879375, 0.888125, 0.8875, 0.886875, 0.8825, 0.8925]], [0.75, 0.5, [0.41032169133107715, 0.37122817583223605, 0.35897897873470125, 0.3438001747064768, 0.33858899811797954, 0.3389760729797343, 0.32536247420184156, 0.3152934226425404, 0.30936657058748795, 0.3078679118226183, 0.30974164977669716, 0.30031369174731537, 0.29489042173991814, 0.28921707251921613, 0.28369594476324445, 0.2849519875772456, 0.27076949349584734, 0.26930386248104116, 0.26349931491657774, 0.26431971300948176], [0.8086666666666666, 0.82875, 0.8284166666666667, 0.8381666666666666, 0.837, 0.8389166666666666, 0.8490833333333333, 0.8488333333333333, 0.8533333333333334, 0.8551666666666666, 0.8509166666666667, 0.8615, 0.8628333333333333, 0.86225, 0.8715, 0.86775, 0.8748333333333334, 0.8719166666666667, 0.8814166666666666, 0.8835], [0.3464747530221939, 0.3193131250143051, 0.3464068531990051, 0.3129056388139725, 0.3131117367744446, 0.30689118325710296, 0.2929005026817322, 0.3131696957349777, 0.302835636138916, 0.27934255003929137, 0.300513002872467, 0.26962003886699676, 0.2676294481754303, 0.26430738389492037, 0.2525753951072693, 0.2508367341756821, 0.25303518533706665, 0.24774718701839446, 0.24518848478794097, 0.26084545016288757], [0.8225, 0.85375, 0.849375, 0.853125, 0.85875, 0.848125, 0.856875, 0.8575, 0.87, 0.869375, 0.863125, 0.886875, 0.8725, 0.878125, 0.894375, 0.888125, 0.8875, 0.89125, 0.88875, 0.86875]], [0.75, 0.75, [0.4765880586619073, 0.4503744399928032, 0.4249279998401378, 0.42333967214886176, 0.4236916420941657, 0.4269233151002133, 0.4192506206479478, 0.41413671872083174, 0.41084911515738104, 0.389948022413127, 0.39566395788433706, 0.3741930383951106, 0.3794517093040842, 0.3692300356131919, 0.3640432547223061, 0.3608953575504587, 0.3419572095129084, 0.34907091543712515, 0.33601277535583113, 0.3408893179544743], [0.77625, 0.7823333333333333, 0.7916666666666666, 0.80075, 0.7973333333333333, 0.7810833333333334, 0.7928333333333333, 0.7930833333333334, 0.7951666666666667, 0.8015833333333333, 0.8000833333333334, 0.8126666666666666, 0.811, 0.81775, 0.8236666666666667, 0.8215, 0.8305833333333333, 0.8251666666666667, 0.8299166666666666, 0.836], [0.3674533206224442, 0.36733597874641416, 0.35894496202468873, 0.3514183223247528, 0.35345671892166136, 0.36494161546230314, 0.35217500329017637, 0.3447349113225937, 0.34697150766849516, 0.36931039452552794, 0.3350031852722168, 0.3416145300865173, 0.32389605045318604, 0.3109715062379837, 0.3322615468502045, 0.327584428191185, 0.31910278856754304, 0.311815539598465, 0.2950947880744934, 0.2948034608364105], [0.808125, 0.789375, 0.826875, 0.821875, 0.81375, 0.804375, 0.80625, 0.83, 0.820625, 0.848125, 0.816875, 0.8125, 0.83, 0.84625, 0.824375, 0.828125, 0.825625, 0.840625, 0.8475, 0.844375]]]\n",
"data = [[0, 0, [0.400307985173582, 0.2597426520640662, 0.20706942731312025, 0.17091670006251475, 0.13984850759524653, 0.11444453444522518, 0.0929887340481538, 0.07584588486117436, 0.06030314570384176, 0.04997897459031356, 0.037156337104278056, 0.02793900864590992, 0.02030197833807442, 0.01789472087045391, 0.0175876492686666, 0.019220354652448274, 0.013543135874294319, 0.006956856955481477, 0.0024507183060002227, 0.00206579088377317], [0.8547833333333333, 0.9049, 0.9241666666666667, 0.9360166666666667, 0.94695, 0.9585833333333333, 0.9658666666666667, 0.9723166666666667, 0.9780333333333333, 0.9820166666666666, 0.9868, 0.9906666666666667, 0.9936833333333334, 0.9941333333333333, 0.99405, 0.9932833333333333, 0.9960666666666667, 0.9979666666666667, 0.9996666666666667, 0.9995666666666667], [0.36797549843788147, 0.2586278670430183, 0.24208260095119477, 0.24353929474949837, 0.24164094921946525, 0.2638056704550982, 0.2579395814836025, 0.27675500786304474, 0.2851512663513422, 0.30380481338500975, 0.3235128371268511, 0.3284085538983345, 0.3443841063082218, 0.41086878085136413, 0.457796107493341, 0.4356938077956438, 0.4109785168170929, 0.4433729724138975, 0.4688420155197382, 0.4773445381522179], [0.87, 0.908375, 0.91475, 0.915125, 0.91525, 0.91725, 0.924875, 0.91975, 0.922375, 0.92025, 0.920375, 0.924875, 0.9235, 0.918125, 0.91525, 0.918875, 0.923625, 0.9235, 0.92625, 0.925]], [0, 0.25, [0.4710115425463424, 0.3166707545550647, 0.25890692547440275, 0.22350736999753187, 0.19296910860009794, 0.17304379170113154, 0.15315235079105285, 0.13728606270383925, 0.12178339355929034, 0.10961619754736898, 0.10074329449495337, 0.08793247367408294, 0.07651288138686625, 0.06934997136779089, 0.06243234033510685, 0.056774082654433795, 0.05116950291028218, 0.04961718403588313, 0.04289388027836952, 0.040430180404756245], [0.8289666666666666, 0.8851833333333333, 0.9045166666666666, 0.9167666666666666, 0.9294166666666667, 0.93545, 0.94275, 0.9486666666666667, 0.95365, 0.95855, 0.9618833333333333, 0.9667, 0.9717666666666667, 0.9745833333333334, 0.9765833333333334, 0.9793, 0.9809833333333333, 0.9820333333333333, 0.9839166666666667, 0.9849166666666667], [0.3629846270084381, 0.31240448981523516, 0.24729759228229523, 0.2697310926616192, 0.24718070650100707, 0.23403583562374114, 0.2295891786813736, 0.22117181441187858, 0.2475375788807869, 0.23771390727162361, 0.2562992911040783, 0.25533875498175623, 0.27057862806320193, 0.2820998176634312, 0.29471745146811007, 0.2795617451965809, 0.3008101430237293, 0.28815430629253386, 0.31814645100384953, 0.3106237706840038], [0.874125, 0.88875, 0.908875, 0.9045, 0.9145, 0.918125, 0.919375, 0.9245, 0.91975, 0.926, 0.923625, 0.925875, 0.92475, 0.926375, 0.925125, 0.92525, 0.924625, 0.930875, 0.924875, 0.926625]], [0, 0.5, [0.6091368444629316, 0.40709905083309106, 0.33330900164873106, 0.29541655938063605, 0.26824146830864043, 0.24633059249535552, 0.22803501166832219, 0.21262132842689435, 0.20038021789160745, 0.18430457027680647, 0.1744787511763288, 0.165271017740149, 0.15522625095554507, 0.1432937567076608, 0.13617747858651222, 0.12876031456241158, 0.12141566201230325, 0.11405601029369686, 0.11116664642408522, 0.10308189516060992], [0.7803833333333333, 0.8559166666666667, 0.8823, 0.89505, 0.9027333333333334, 0.9099166666666667, 0.9162333333333333, 0.9224833333333333, 0.9243166666666667, 0.9321, 0.9345833333333333, 0.9375333333333333, 0.9418833333333333, 0.9456666666666667, 0.9482333333333334, 0.9513666666666667, 0.9527333333333333, 0.9559, 0.9576166666666667, 0.9611], [0.36491659212112426, 0.29200539910793305, 0.2840233483910561, 0.2591339669823646, 0.24114771646261215, 0.2436459481716156, 0.2374294084906578, 0.24284198743104934, 0.22679156363010405, 0.2229055170416832, 0.21932773572206496, 0.23045065227150918, 0.23631879675388337, 0.22048399156332016, 0.2563135535418987, 0.2494968646839261, 0.24099056956171988, 0.23974315640330315, 0.24684958010911942, 0.25887142738699914], [0.8665, 0.8925, 0.897, 0.907375, 0.914125, 0.9125, 0.913875, 0.911875, 0.921125, 0.922625, 0.923375, 0.924125, 0.922625, 0.926, 0.915625, 0.926125, 0.932625, 0.927875, 0.93, 0.92525]], [0, 0.75, [1.187068938827718, 0.9080034740316842, 0.6863665148329887, 0.5706229420867301, 0.5069490017921432, 0.46316734996876485, 0.42913920047885573, 0.4107565824855874, 0.3908677859061054, 0.37283689377785745, 0.3606657798388111, 0.353545261082301, 0.34009441143986, 0.3239413740506559, 0.3193119444620253, 0.31045137204404577, 0.3003838519091164, 0.29092520530194615, 0.28635713599447504, 0.2760026559138349], [0.5551333333333334, 0.6467, 0.7338666666666667, 0.7841333333333333, 0.8128, 0.82845, 0.8430833333333333, 0.8501666666666666, 0.8580833333333333, 0.8646166666666667, 0.8667666666666667, 0.8709833333333333, 0.8766166666666667, 0.8816666666666667, 0.8812, 0.88465, 0.8898833333333334, 0.8934666666666666, 0.8940833333333333, 0.8977666666666667], [0.6463955206871033, 0.5193838343620301, 0.4155286856889725, 0.3316091845035553, 0.3148408111333847, 0.29354524302482604, 0.2875490103960037, 0.26903486740589144, 0.27737221759557723, 0.262776792883873, 0.25498255288600924, 0.2390553195178509, 0.24918611392378806, 0.23830307483673097, 0.23538302001357078, 0.24996423116326333, 0.2464654156267643, 0.24081429636478424, 0.23204647853970528, 0.23771219885349273], [0.763875, 0.81925, 0.8685, 0.8885, 0.8895, 0.895625, 0.902, 0.904125, 0.906125, 0.908, 0.909375, 0.9145, 0.916125, 0.9175, 0.91875, 0.91425, 0.915375, 0.918875, 0.91975, 0.91825]], [0.25, 0, [0.4140813298491654, 0.27481235485118843, 0.22397600941614174, 0.1890777693286951, 0.16538111197112848, 0.1448796250478132, 0.12440053254032313, 0.10817898457734855, 0.09634132136696025, 0.08548538653410352, 0.07339220296349257, 0.06470446296305314, 0.060030178171393875, 0.053294485403614034, 0.04429284706704323, 0.04014099264770115, 0.03974721442450951, 0.03304463665041803, 0.02955428938137994, 0.026940144761875052], [0.8496666666666667, 0.8982666666666667, 0.9162166666666667, 0.9292166666666667, 0.93805, 0.9457666666666666, 0.9534333333333334, 0.9596, 0.9645833333333333, 0.9679, 0.9726166666666667, 0.9761666666666666, 0.9775, 0.9800166666666666, 0.9842, 0.9855333333333334, 0.9857, 0.98805, 0.9895666666666667, 0.9905833333333334], [0.3327465409040451, 0.27738857254385946, 0.23834018683433533, 0.24359044748544692, 0.23630736249685289, 0.26239568686485293, 0.23089197066426276, 0.23183160039782524, 0.2287161501646042, 0.23795067170262338, 0.2680365410447121, 0.28079107534885406, 0.2745736412107945, 0.27641161236166956, 0.2967236565724015, 0.29836027943715454, 0.28526886811852453, 0.3188628684282303, 0.3159900237545371, 0.33990017675608397], [0.876875, 0.899875, 0.918125, 0.9105, 0.918125, 0.91, 0.92075, 0.922625, 0.924, 0.921, 0.920875, 0.921, 0.9285, 0.927625, 0.9265, 0.927375, 0.925875, 0.927, 0.92575, 0.925875]], [0.25, 0.25, [0.48859380523978013, 0.3269256727337075, 0.275135099903734, 0.24039912359244914, 0.21368402032566858, 0.19328243048317523, 0.17890911489359732, 0.16624130663682402, 0.15215728174088827, 0.1416037013468299, 0.13273427299440288, 0.12227611260405227, 0.11463099068699917, 0.10616964906720179, 0.09988978996809357, 0.09424899211093815, 0.08670466838887077, 0.0835973875783781, 0.0778748192367698, 0.07327510508696741], [0.82055, 0.8806666666666667, 0.9004333333333333, 0.9117333333333333, 0.9206333333333333, 0.92785, 0.9333, 0.9384166666666667, 0.9430333333333333, 0.9471833333333334, 0.95055, 0.9540166666666666, 0.9568833333333333, 0.9601666666666666, 0.9620333333333333, 0.9652, 0.9676833333333333, 0.9682666666666667, 0.9706, 0.9724333333333334], [0.34025013536214826, 0.29788709819316866, 0.2680273652672768, 0.2463292105793953, 0.23471139985322953, 0.22580294385552407, 0.21676637730002404, 0.20925517010688782, 0.23552959233522416, 0.21975916308164598, 0.23494828915596008, 0.21611644634604454, 0.22251244640350343, 0.22066593673825263, 0.2214409472346306, 0.22849382662773132, 0.24493269926309585, 0.2397777333110571, 0.23578458192944526, 0.2563280282020569], [0.870875, 0.8875, 0.900375, 0.906625, 0.9145, 0.921125, 0.92125, 0.92425, 0.916, 0.923125, 0.920375, 0.92675, 0.92575, 0.924875, 0.925, 0.924875, 0.922875, 0.931125, 0.932375, 0.929]], [0.25, 0.5, [0.6104797730917362, 0.42115319246994154, 0.3527538229359874, 0.3136731511446586, 0.2857721160565104, 0.26646374052426197, 0.24732486170523965, 0.23057452346613286, 0.21953405395769743, 0.20952929538100767, 0.19584925043811677, 0.18926965880162044, 0.18003955145856973, 0.17379174885878176, 0.16635702809354644, 0.15807223409366633, 0.1509416516620054, 0.1477138751140758, 0.14028569269798266, 0.13906246528172417], [0.7786833333333333, 0.8482166666666666, 0.8730833333333333, 0.888, 0.8978, 0.9033666666666667, 0.9089166666666667, 0.9147666666666666, 0.91955, 0.9221833333333334, 0.92715, 0.9309666666666667, 0.9334, 0.93495, 0.9376833333333333, 0.9402666666666667, 0.94405, 0.9439166666666666, 0.9466833333333333, 0.9464833333333333], [0.3859497320652008, 0.3124091213941574, 0.28177140313386917, 0.2564259949326515, 0.24969424712657928, 0.23137387067079543, 0.22758139592409135, 0.22978509336709976, 0.2293499847650528, 0.22430640310049058, 0.21563700905442237, 0.21529569518566133, 0.22171301135420798, 0.2105387990772724, 0.21190602815151213, 0.21494245541095733, 0.21312989933788776, 0.20670134457945824, 0.2146600303351879, 0.21474341893941165], [0.86, 0.888, 0.89625, 0.907, 0.908, 0.915, 0.917875, 0.92, 0.921125, 0.917625, 0.924, 0.921875, 0.925875, 0.92575, 0.928125, 0.92775, 0.928625, 0.93075, 0.92975, 0.930375]], [0.25, 0.75, [1.1724896589194789, 0.8803599189911315, 0.692622532690766, 0.5974764075837156, 0.5319996399920124, 0.49373906012028773, 0.4741932853007876, 0.45601858158927483, 0.43706520244892216, 0.4238534729236733, 0.41077356216813454, 0.38932509837882606, 0.3771154705856019, 0.3687882057305719, 0.34927689276937485, 0.3379922736602933, 0.33547254843212393, 0.3263144160448107, 0.31800466419251233, 0.3133781185822446], [0.5631833333333334, 0.6579333333333334, 0.7342166666666666, 0.7765833333333333, 0.8036333333333333, 0.8197166666666666, 0.82755, 0.8320166666666666, 0.8397833333333333, 0.8432666666666667, 0.8519333333333333, 0.85835, 0.86285, 0.8641, 0.87105, 0.8756666666666667, 0.8775166666666666, 0.87965, 0.88255, 0.8832333333333333], [0.5745115535259246, 0.4740168128013611, 0.4092038922309876, 0.345498643040657, 0.32894178831577303, 0.2999964846372604, 0.28456189918518066, 0.28186965006589887, 0.26958267349004744, 0.26703972268104553, 0.2667745503783226, 0.2553461962342262, 0.25764305877685545, 0.2528705199956894, 0.24987997275590895, 0.24210182267427444, 0.2366510547697544, 0.24053962442278862, 0.22825994032621383, 0.2270425768494606], [0.776875, 0.822625, 0.848875, 0.87825, 0.88925, 0.899875, 0.9015, 0.904375, 0.9035, 0.906, 0.906875, 0.91125, 0.907, 0.908625, 0.91175, 0.917125, 0.91675, 0.916125, 0.919875, 0.917625]], [0.5, 0, [0.43062501005145276, 0.29807482149078646, 0.2541527441585623, 0.21918726423338278, 0.1950343672964555, 0.17517360023010387, 0.16213757058244144, 0.14869415854364, 0.13477844860392815, 0.12352272007129848, 0.11392300839184412, 0.10589898744228679, 0.09751250602896692, 0.089864786467088, 0.08516462990539526, 0.07973235945548934, 0.07441158362824137, 0.07053931183896578, 0.06258528833356954, 0.06177985634201014], [0.8429, 0.88905, 0.9052166666666667, 0.9182166666666667, 0.92755, 0.9337666666666666, 0.93835, 0.944, 0.9489333333333333, 0.95365, 0.9565333333333333, 0.9599166666666666, 0.9637833333333333, 0.9659666666666666, 0.9685666666666667, 0.9705, 0.9713666666666667, 0.9738, 0.9770166666666666, 0.9769833333333333], [0.32814766228199005, 0.29447353577613833, 0.25052148789167406, 0.22761481428146363, 0.23280890756845474, 0.23155913531780242, 0.21984874603152274, 0.2166314404308796, 0.2202563073039055, 0.22508277136087418, 0.2237191815972328, 0.2246915928721428, 0.22815296687185765, 0.2254556802213192, 0.2337513281852007, 0.2381753808259964, 0.24798179551959038, 0.24766947883367538, 0.24877363580465317, 0.2518915164768696], [0.879625, 0.89025, 0.907875, 0.916625, 0.91625, 0.91825, 0.920875, 0.923625, 0.922625, 0.923, 0.92575, 0.927125, 0.928625, 0.92625, 0.925375, 0.925625, 0.926375, 0.92475, 0.9255, 0.92675]], [0.5, 0.25, [0.5022556754285847, 0.3545388207554436, 0.2965180559564374, 0.2689443711818917, 0.24340009927622544, 0.22504497168144819, 0.21177587015574167, 0.19926073912507308, 0.18498492261557692, 0.1792394390810273, 0.16716771742809555, 0.16088557891500022, 0.15540826101420022, 0.1471743908549931, 0.14383414784458273, 0.1351151093741311, 0.1312572255915305, 0.12904865093140014, 0.12332957751079918, 0.11934908895072208], [0.8186333333333333, 0.8711666666666666, 0.8905666666666666, 0.9020666666666667, 0.9106333333333333, 0.9169333333333334, 0.9227, 0.9258166666666666, 0.9317, 0.9329666666666667, 0.9384833333333333, 0.9394333333333333, 0.94185, 0.9447666666666666, 0.9449833333333333, 0.9489, 0.9506, 0.9520333333333333, 0.95295, 0.9556833333333333], [0.37072600054740906, 0.2894986196160316, 0.2896255247592926, 0.2553737629055977, 0.2347450014948845, 0.23144772934913635, 0.22532679361104965, 0.2152210614681244, 0.21610748746991157, 0.22872606116533278, 0.22058768355846406, 0.20230921444296837, 0.2118315652012825, 0.20028054055571556, 0.20844366964697839, 0.20884322375059128, 0.21231223946809769, 0.19875787001848222, 0.2072589308321476, 0.22480831852555275], [0.862, 0.894, 0.892375, 0.906375, 0.912625, 0.91375, 0.916875, 0.918875, 0.92125, 0.9185, 0.920375, 0.92825, 0.9255, 0.92925, 0.926875, 0.9285, 0.926375, 0.93075, 0.931125, 0.922875]], [0.5, 0.5, [0.6208003907124879, 0.4341448332582201, 0.3655890760454796, 0.3245583019102179, 0.3000562671722888, 0.2840681741280215, 0.2686156402947679, 0.25843519997844566, 0.24892204790227196, 0.23988707410469493, 0.22968693327770304, 0.22323107979953416, 0.21376596502403714, 0.21353628940340172, 0.208721635311143, 0.20283085862393063, 0.19862186088204892, 0.1939613972542319, 0.18833921627917968, 0.18451892669552933], [0.7769666666666667, 0.8453333333333334, 0.86965, 0.88425, 0.8911, 0.8957666666666667, 0.90125, 0.9056666666666666, 0.9083833333333333, 0.9122666666666667, 0.91455, 0.9176833333333333, 0.92035, 0.9217, 0.9232333333333334, 0.9238333333333333, 0.9270333333333334, 0.9283, 0.93035, 0.9312333333333334], [0.390482270359993, 0.3140819278359413, 0.286346542596817, 0.26530489122867584, 0.25648517191410064, 0.25534764647483826, 0.24066219604015351, 0.22813884472846985, 0.22091108289361, 0.22591463786363603, 0.22548504903912545, 0.21807716876268388, 0.23463654381036758, 0.21917386519908905, 0.2077158398628235, 0.2112607652246952, 0.205703763961792, 0.21748955991864205, 0.20092388433218003, 0.20742826372385026], [0.859125, 0.884375, 0.89225, 0.9035, 0.9045, 0.904875, 0.907875, 0.915375, 0.914875, 0.915375, 0.916375, 0.92075, 0.91575, 0.91825, 0.92375, 0.924, 0.924875, 0.917125, 0.926875, 0.920875]], [0.5, 0.75, [1.1608194957918196, 0.8736483463918222, 0.7270457689632485, 0.6118623841482439, 0.5539627463769302, 0.5169604117872872, 0.4843029365547176, 0.4664089765979537, 0.449539397952399, 0.4308713404481599, 0.4170197155842903, 0.4104185118508746, 0.3983522486299086, 0.3890672579232945, 0.38423672571047535, 0.38125834129512437, 0.36963055836461756, 0.36898326972273116, 0.3608236700328174, 0.35822524538617145], [0.56785, 0.6591833333333333, 0.71765, 0.7660333333333333, 0.7931666666666667, 0.8079666666666667, 0.8198833333333333, 0.8275166666666667, 0.8349833333333333, 0.8422, 0.8473666666666667, 0.8486833333333333, 0.85425, 0.85675, 0.8578666666666667, 0.8603333333333333, 0.8643333333333333, 0.8637833333333333, 0.8684333333333333, 0.8680166666666667], [0.5984484012126923, 0.5152713191509247, 0.42289899206161496, 0.3746640253067017, 0.3369040569067001, 0.32359291434288023, 0.2978636801838875, 0.2998174095153809, 0.2883352539539337, 0.2839300352931023, 0.2775397801399231, 0.2616970262527466, 0.259125192284584, 0.25470315623283385, 0.2535187450051308, 0.2600560383200645, 0.25031394577026367, 0.2547155976295471, 0.23950587111711502, 0.24401323813199996], [0.750875, 0.78025, 0.86225, 0.869875, 0.884875, 0.891625, 0.898875, 0.89275, 0.901875, 0.9005, 0.899875, 0.908375, 0.91125, 0.910375, 0.910375, 0.907, 0.9135, 0.910375, 0.914125, 0.911625]], [0.75, 0, [0.5018121279410716, 0.3649225841834347, 0.31199926770985253, 0.2825479824850554, 0.25993211727057186, 0.2431308363737074, 0.22870161555913973, 0.22126636312587428, 0.2113911879540824, 0.20279224649834227, 0.19300907663603836, 0.18686007729360163, 0.1815741605866057, 0.1759802805684777, 0.17041425832084564, 0.16513840764014323, 0.15892388751861383, 0.1548161118118557, 0.1498002242614656, 0.14744469122107284], [0.8158, 0.8648, 0.8846833333333334, 0.8954666666666666, 0.9035333333333333, 0.9097666666666666, 0.9142666666666667, 0.91615, 0.9219166666666667, 0.9239333333333334, 0.9268166666666666, 0.9287666666666666, 0.9304833333333333, 0.9327333333333333, 0.9365, 0.9368666666666666, 0.9395333333333333, 0.9418833333333333, 0.9445, 0.9450166666666666], [0.35916801404953, 0.30038927191495896, 0.2824265750646591, 0.28094157111644746, 0.2402345055937767, 0.24779821130633353, 0.2263277245759964, 0.22270147562026976, 0.22010754531621932, 0.20850908517837524, 0.21723379525542258, 0.20454896742105483, 0.2065480750799179, 0.20593296563625335, 0.21030707907676696, 0.2015896993279457, 0.19770563289523124, 0.19552358242869378, 0.197759574085474, 0.19900305101275445], [0.867125, 0.890875, 0.896875, 0.896, 0.912125, 0.90875, 0.9185, 0.916875, 0.920375, 0.925125, 0.919375, 0.92675, 0.927125, 0.924625, 0.924125, 0.9275, 0.928, 0.928875, 0.93325, 0.930125]], [0.75, 0.25, [0.564780301424359, 0.41836969141385705, 0.3581543931924204, 0.3251280398018706, 0.30215959723538427, 0.28700008430778345, 0.27507679125488693, 0.26540731782439164, 0.25373875692105496, 0.24964979071734048, 0.24098571216357922, 0.23604591902512223, 0.2270722362135392, 0.2229606584985373, 0.22031292727570545, 0.21439386613126885, 0.21020108821200156, 0.2042837777872012, 0.20376247368149283, 0.20021205727082453], [0.7927, 0.8474166666666667, 0.8672166666666666, 0.8811833333333333, 0.8883, 0.8952833333333333, 0.89795, 0.9011333333333333, 0.9055833333333333, 0.9071166666666667, 0.9100333333333334, 0.911, 0.91515, 0.9162166666666667, 0.91775, 0.9197833333333333, 0.9218666666666666, 0.9239, 0.9236833333333333, 0.92455], [0.39558523416519165, 0.3187315353155136, 0.30105597496032716, 0.2717038299441338, 0.25286867189407347, 0.24664685553312302, 0.24286985045671464, 0.23643679201602935, 0.23006864881515504, 0.2277349520921707, 0.22591854375600814, 0.2165311907827854, 0.21385486593842506, 0.21402871897816658, 0.2096972267627716, 0.21242560443282127, 0.2098898750245571, 0.2062524998188019, 0.19932547932863234, 0.20170186588168143], [0.850625, 0.88125, 0.8845, 0.897125, 0.9065, 0.9085, 0.907625, 0.91275, 0.917125, 0.9135, 0.91825, 0.922625, 0.91925, 0.921125, 0.923625, 0.92225, 0.923375, 0.922875, 0.925625, 0.92775]], [0.75, 0.5, [0.6916971901205303, 0.4947840944567977, 0.41710148827988963, 0.38678343986460906, 0.36429949198513906, 0.34339441834831796, 0.33055868282564665, 0.3199633415272114, 0.31550557391920575, 0.3022628513289921, 0.2959158662110885, 0.2941135993993867, 0.28555906579089063, 0.27903660322462065, 0.2769482293601102, 0.27154609372716215, 0.26548120195963487, 0.26188135733291795, 0.2588035051009929, 0.2574938320115939], [0.7497333333333334, 0.8236833333333333, 0.8482333333333333, 0.8618666666666667, 0.8703666666666666, 0.8772166666666666, 0.8803333333333333, 0.8829166666666667, 0.88525, 0.88945, 0.89275, 0.8937166666666667, 0.8969, 0.8977666666666667, 0.9, 0.90175, 0.9041666666666667, 0.9035, 0.9049, 0.9046166666666666], [0.41916924858093263, 0.3380992366075516, 0.31549062132835387, 0.2921286026239395, 0.2786481494307518, 0.28516836106777194, 0.25556409001350405, 0.2538892236948013, 0.24726227968931197, 0.24262803781032563, 0.24080126863718032, 0.24242325466871262, 0.23416680485010147, 0.22847312396764755, 0.22423979061841964, 0.2311997367441654, 0.22794704174995423, 0.21943940049409866, 0.21820387506484987, 0.21150743806362152], [0.8435, 0.87725, 0.88425, 0.890375, 0.898125, 0.89275, 0.905625, 0.906125, 0.911, 0.910625, 0.911, 0.909875, 0.914875, 0.915375, 0.917875, 0.915, 0.91475, 0.919625, 0.923875, 0.92425]], [0.75, 0.75, [1.162218615571573, 0.8284856370453642, 0.7309887468624217, 0.6590983641744931, 0.6089096262510906, 0.5663433943285363, 0.5383681068733048, 0.5242803116787725, 0.49926126579930785, 0.48940120944018556, 0.4789252862779062, 0.46633604049746163, 0.4596060775458686, 0.4464966354847971, 0.4418302221593064, 0.43759817490254893, 0.42892070028827645, 0.4226101264516428, 0.418694807601763, 0.4110745745840103], [0.58005, 0.6824666666666667, 0.7223333333333334, 0.7464333333333333, 0.7711333333333333, 0.7891833333333333, 0.8012333333333334, 0.80635, 0.8172666666666667, 0.82225, 0.8271833333333334, 0.831, 0.8335833333333333, 0.8371833333333333, 0.8412166666666666, 0.84265, 0.8458833333333333, 0.8471166666666666, 0.8497666666666667, 0.8522833333333333], [0.5945872340202332, 0.518519122838974, 0.4681703653335571, 0.42978407418727876, 0.40349935555458066, 0.37377681517601014, 0.35234942865371705, 0.3359788683652878, 0.3217720929384232, 0.3279728285074234, 0.3114012089371681, 0.3060767319202423, 0.2949701727628708, 0.2981588536500931, 0.2855641575455666, 0.28112928783893587, 0.28212732630968096, 0.27846804082393645, 0.27372796374559405, 0.27415593349933626], [0.78525, 0.8215, 0.820125, 0.844375, 0.86375, 0.875125, 0.876625, 0.882, 0.887875, 0.884625, 0.890375, 0.892125, 0.897125, 0.894125, 0.902625, 0.89975, 0.89975, 0.90125, 0.902, 0.90075]]]\n",
"\n",
"\n",
"Dropout1 = 0.25 # param {type:\"slider\", min:0, max:0.75, step:0.25}\n",
"Dropout2 = 0.75 # param {type:\"slider\", min:0, max:0.75, step:0.25}\n",
"\n",
"def plot(Dropout1, Dropout2):\n",
" d1, d2, train_loss, train_acc, validation_loss, validation_acc = data[int(Dropout1 * 4) * 4 + int(Dropout2 * 4)]\n",
" print(d1, d2)\n",
" plot_loss_accuracy(train_loss, train_acc, validation_loss, validation_acc)\n",
" plt.gcf().axes[0].set_ylim(0, 1.2)\n",
" plt.gcf().axes[1].set_ylim(0.5, 1)\n",
"\n",
" my_stringIObytes = io.BytesIO()\n",
" plt.savefig(my_stringIObytes, format='png', dpi=90)\n",
" my_stringIObytes.seek(0)\n",
" my_base64_jpgData = base64.b64encode(my_stringIObytes.read())\n",
" plt.close()\n",
" p.value = \"\"\" \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_How_much_augmentation_help_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! Bonus 2.2: Data Augmentation\n",
"\n",
"Did the training accuracy reduce further compared to with dropout alone? Is the model still overfitting?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_ae125a93.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Great! In this section you trained what may have been your very first CNN. You added regularization and data augmentation in order to get a model that generalizes well. All the pieces are beginning to fit together!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Data_Augmentation_Bonus_Discussion\")"
]
}
],
"metadata": {
"accelerator": "GPU",
"colab": {
"collapsed_sections": [],
"include_colab_link": true,
"machine_shape": "hm",
"name": "W2D2_Tutorial1",
"provenance": [],
"toc_visible": true
},
"kernel": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_How_much_augmentation_help_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! Bonus 2.2: Data Augmentation\n",
"\n",
"Did the training accuracy reduce further compared to with dropout alone? Is the model still overfitting?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content-dl/tree/main/tutorials/W2D2_ConvnetsAndDlThinking/solutions/W2D2_Tutorial1_Solution_ae125a93.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Great! In this section you trained what may have been your very first CNN. You added regularization and data augmentation in order to get a model that generalizes well. All the pieces are beginning to fit together!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Data_Augmentation_Bonus_Discussion\")"
]
}
],
"metadata": {
"accelerator": "GPU",
"colab": {
"collapsed_sections": [],
"include_colab_link": true,
"machine_shape": "hm",
"name": "W2D2_Tutorial1",
"provenance": [],
"toc_visible": true
},
"kernel": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 0
}